本文主要是介绍有待挖掘的金矿:大模型的幻觉之境,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人工智能正在迅速变得无处不在,在科学和学术研究中,自回归的大型语言模型(LLM)走在了前列。自从LLM的概念被整合到自然语言处理(NLP)的讨论中以来,LLM中的幻觉现象一直被广泛视为一个显著的社会危害和一个关键的瓶颈,阻碍了LLM在现实世界中的应用。无论是在流行且全面的学术调查中,还是在面向公众的技术报告中,都将幻觉问题定位为LLM的主要伦理和安全陷阱之一,应该与其他问题(如偏见和毒性)一起得到严重缓解。因此,将幻觉减少到可以忽略不计的水平的承诺,不仅被视为一个技术挑战,也是更广泛使命的关键组成部分,以减轻与LLM的广泛部署和广泛采用相关的社会污名和系统风险。
然而,一小部分工作提出了一种观点,即幻觉并非本质上有害。这种探索性的观点强调了幻觉的潜在价值和合理必要性。最近的研究表明,幻觉是统计上的必然,并且由于创造性、生成性和信息准确性之间的权衡,从LLM中消除幻觉是不可能的。此外,在许多特定领域的应用中,实现创造性和事实性之间的优化平衡,比仅仅试图消除幻觉更能有效地最大化LLM的效用。幻觉可能特别有价值的LLM用例包括发现新型蛋白质、为创意写作提供灵感以及制定创新的法律类比。
在本文中,我们试图扩大幻觉的概念,并认为幻觉更接近于“虚构”这一概念,这一术语已经在关于AI的公共话语中获得了流行,但尚未在学术文献中广泛传播。
1 “虚构”(confabulation)VS“幻觉”(hallucination)
"Confabulation" 和 "hallucination" 都是从精神病学借用过来的人化类比,但"confabulation"因避免了暗示LLMs具有感官体验或意识的棘手含义,且更中性,因此在AI公共话语中被视为"hallucination"的首选替代词。
1.1 现有定义的局限性
现有的定义主要关注伪造与事实不符的特征,忽略了其在人类交流中的社会和认知效益。
这些定义没有充分考虑人类在填补知识空白时,倾向于使用叙事作为认知资源的倾向。
1.2 新的定义
伪造是一种叙事冲动,即生成更具实质性、更连贯的输出的倾向。这种冲动体现了人类利用叙事进行理解和交流的倾向。
伪造可以产生虚构但可信的信息,帮助人们填补知识空白,并构建连贯的语义意义。
2 数据、方法和结果
2.1 基准数据集
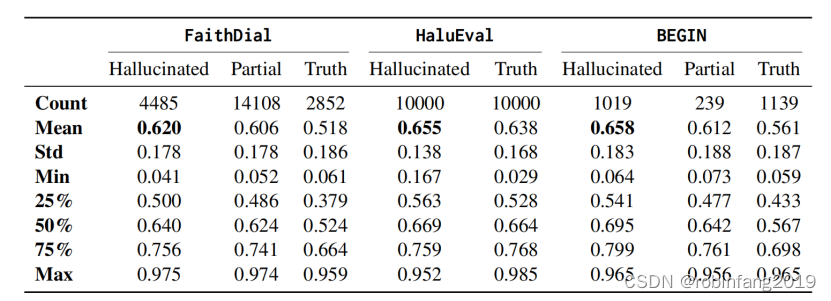
FaithDial:一个无幻觉的对话基准,介于寻求信息的用户和聊天机器人之间,改编自“维基百科巫师”。Mechanical Turk注释器将WoW的人类生成响应标记为“幻觉”或真实响应。真实响应被细分为三个类别:“蕴含”(Entailment)、“不合作”(Uncooperative)和“通用”(Generic),并对21445个原始响应进行了忠实且基于知识的编辑。
BEGIN:是对FaithDial进行的初步研究,旨在选择一个现有的基准进行后续的大规模注释和编辑。作为一个较小的专家策划集,它包括信息寻求查询以及人类编写和模型生成(GPT-2、DoHA和CRTL)的响应,每种响应都使用与FaithDial略有不同的幻觉分类法进行标记(增加了“部分幻觉”作为标签),由专家注释器完成。我们采用BEGIN作为对我们在HaluEval上发现的叙事模式的模型和数据集的一致性和鲁棒性的验证,以确认不同数据集和模型之间叙事模式的一致性和鲁棒性。
HaluEval:是一个全面的数据集,展示了合理但幻觉的ChatGPT生成与其真相对应物。与FaithDial和BEGIN更细粒度的幻觉标签不同,HaluEval只区分幻觉和真相响应。我们只使用HaluEval的对话部分,包含10000个样本,以保持与其他基准的领域一致性。
对于FaithDial和BEGIN数据集,我们将所有不包含“幻觉”标签的输出视为“真相”,并将所有包含“幻觉”标签以及一个额外真实标签的输出视为“部分”幻觉/真相。这种聚合允许跨数据集进行更直接的比较。如下表所示:虚构文本表现出更高水平的叙事性,因此可以被视为一种叙事丰富的行为。
2.2 方法
- 叙事性评估: 使用微调后的 ELECTRA-large 模型,对幻觉文本和真实文本进行叙事性评估,并比较两组文本的叙事性得分。
- 叙事性与幻觉标签的相关性分析: 使用二元逻辑回归模型,分析叙事性得分与幻觉标签之间的预测关系,以确定叙事性是否可以预测幻觉标签。
- 叙事性与连贯性的相关性分析: 使用贝塔回归模型,分析叙事性得分与对话连贯性得分之间的相关性,以确定叙事性是否与连贯性相关。
2.3 结果
- 叙事性: 在所有三个基准数据集中,幻觉文本的叙事性得分都显著高于部分幻觉文本和非幻觉文本,以及它们的真实回复。
- 叙事性与幻觉标签: 叙事性得分可以显著预测幻觉标签,即叙事性越高的文本,更有可能被标注为幻觉。
- 叙事性与连贯性: 叙事性得分与对话连贯性得分之间存在显著正相关关系,即叙事性越高的文本,对话的连贯性也越高。
3 虚构价值有待挖掘
我们认为,虚构的叙事丰富特性不应被视为缺陷,而是LLM与人类使用叙事作为说服、身份构建和社会协商多功能工具的既定倾向相一致的标志。反过来,规范观点对虚构的不加思索的否定将冒着从LLM的能力中消除对沟通和意义构建至关重要的行为和认知能力的风险。虚构价值有待进一步挖掘:
- 叙事性增强: 伪造的输出往往具有更高的叙事性,即内容更加连贯和有故事性。这与人类倾向于使用叙事来理解和沟通的方式相似,因此可能更易于理解和接受。
- 启发式工具: 伪造的输出可以作为启发式工具,帮助人们探索特定领域的场景,并利用伪造的特性进行创造性思维。
- 对抗样本: 伪造的输出可以用于构建对抗样本,帮助提高模型的鲁棒性和可靠性。
- 合成训练数据: 伪造的输出可以作为合成训练数据,用于增强模型的泛化能力。
4 未来研究方向
我们提出对LLM虚构现象作为潜在资源的系统性辩护,而不是一个绝对的负面陷阱。我们认为,认为LLM产生幻觉是因为它们不可靠、不忠实,最终不像人类的观点过于简化。相反,它们虚构并表现出与人类讲故事冲动非常相似的叙事丰富行为模式——也许幻觉使它们比我们愿意承认的更像我们。
- 因果关系未明确:尽管研究发现叙述性与连贯性之间存在关联,但研究并未断言叙述性直接驱动连贯性,这需要更全面的方法来阐明。
- 跨学科视角的支持:当前结论得到了跨学科视角的支持,但需要更健壮的叙事建模方法和更全面的人类评估来进一步探讨这一关联。
- 人类-AI交互的验证:研究中观察到的叙述性和连贯性特征在人类-人类交流中被认为是有益的,但这些特性在人类-AI交互中的适用性需要通过基于人类的评估来验证。
- 后续实验计划:计划通过包含人类参与者的实验来验证叙事参与的益处,并探索虚构在不同领域的应用潜力。
- 跨领域应用探索:如果叙事丰富的虚构得到有效验证,将为未来研究开辟新途径,包括在新闻、广告等领域的应用,并可能激发更多跨学科的探索。
这篇关于有待挖掘的金矿:大模型的幻觉之境的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








