本文主要是介绍交通大数据分析与挖掘实训【对提供的CSV格式数据使用pandas库分析-Matplotlib库绘图】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景:
《交通大数据分析与挖掘》实训
指 导 书
编著
二○二四年五月
一、实训目的
1、掌握python开发环境(如Anaconda)及Numpy等常见第三方库的使用;
2、熟悉Anaconda在线编程平台,学会基本的python程序编写、编译与运行程序的方法及函数语句;
3、学会导入不同格式数据文件,掌握不同类型数据的基本处理和分析思路;
4、熟练运用所学第三方库,结合相关交通类数据,开展相关数据分析,并实现交通实例数据的可视化效果展示。
二、实训理论基础
1、了解Python常用外置第三方库的安装与使用,掌握基于python的数据分析与可视化技术工具(numpy、pandas、matplotlib等) 基础知识。
2、 学习numpy计算和数据分析基础,如何创建并操作ndarray以及学会numpy常用属性和函数的使用。
3、认识pandas中两种结构化数据:Series和DataFrame,掌握两种数据的创建、行列的选择等操作。
4、认识.csv、.txt及.json格式文件,学习不同数据格式文件导入方法,以及对导入数据文件进行分析、处理和导出的方法。
5、认识request库,学习使用request访问网页并爬取数据。
6、 使用Matplotlib实现对处理后的数据进行图形化展示,掌握常用的饼图、散点图、柱状图、直方图等的展示,掌握相关函数参数的设置和用法,掌握通过matplotlib API的高级参数设置,实现对绘图的更多的控制和自定义。
7、完成以上内容的综合实例分析与操作,结合交通数据实例以及相关第三方库,通过开展不同类型交通实例数据分析与结果展示,形成课程实训报告。
三、实训仪器设备及材料清单
1、实训仪器设备
实验室机房台式计算机/个人笔记本计算机
网络连接
2、实训所用材料、软件及第三方库
Python运行及开发环境(如Anaconda、Pycharm)
第三方库numpy、pandas(geopandas)、matplotlib、seaborn等
《交通大数据分析与挖掘实训》实验课PPT学习资料
.csv、.txt格式交通数据实例源文件
四、实训内容及步骤
1、Python环境构建及相关第三方库软件安装;
2、Python基础知识与补充函数学习;
3、完成百度地图开发者认证及request库的学习;
4、完成重庆市轨道交通站点名称数据的导入,以及站点对应经纬度的爬取并保存;
5、Matplotlib 库基础函数与可视化绘图的学习;
6、Pandas(Geopandas) 库基础函数的学习;
7、轨道交通刷卡数据的导入;
8、(难点)结合轨道交通刷卡数据,开展分析挖掘与数据可视化,结果记录与分析;
9、实训总结及心得体会。
五、实训任务清单
1、完成样本数据中轨道交通站点的经纬度爬取,并保存为txt或者csv格式的文件。
2、计算样本数据中相邻两个站点的距离,获取最短路径。
3、统计样本数据中,每个站点每天的地铁客流量和公交客流量,选择其中一个站点,筛选一天每小时的客流量,并绘制客流量随时间变化的分布图。
4、将任务清单内容完成,并形成实践报告,附上完整代码,以小组为单位提交。
需求沟通与分析:
过程:
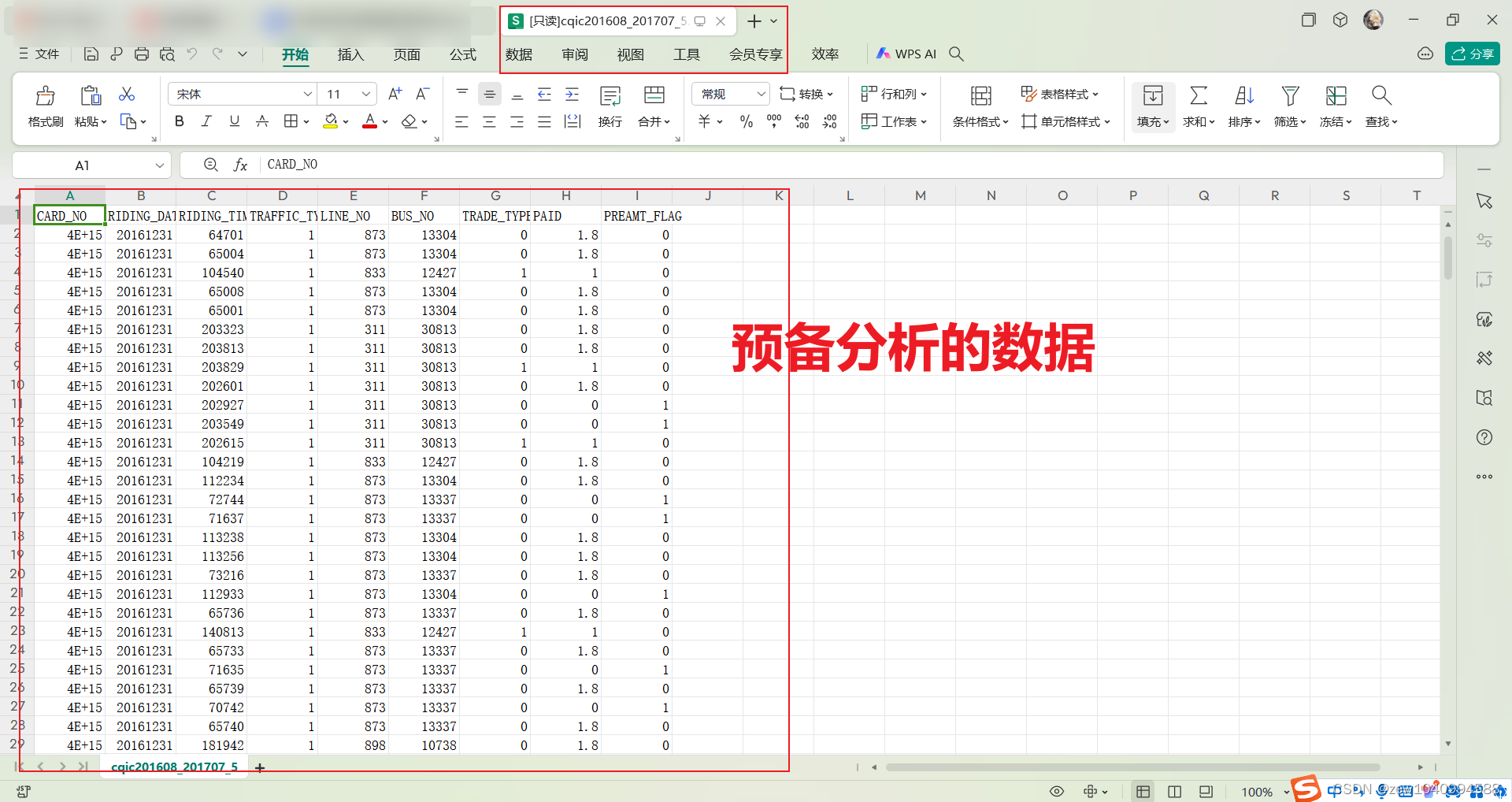
刷卡数据预处理
刷卡数据说明

轨道刷卡数据提取

线路提取

时间提取

重庆轨道交通运行线路网
站点分析及可视化

站点间时间因素分析及可视化

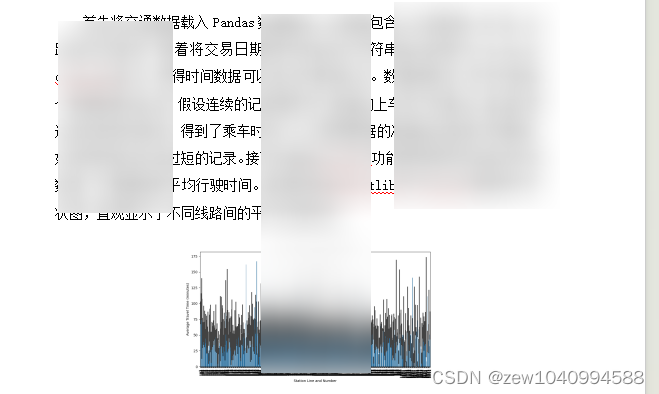
线路网分析及可视化

重庆轨道交通客流分析
线路客流频次统计及可视化

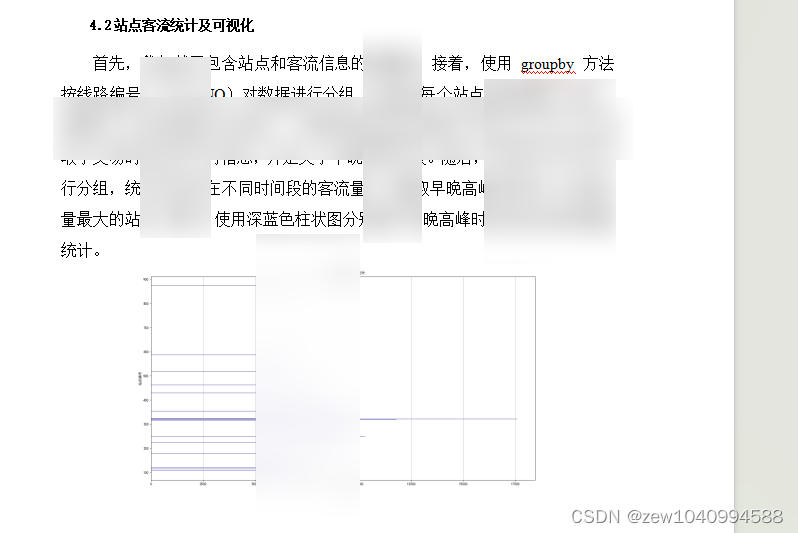
站点客流统计及可视化

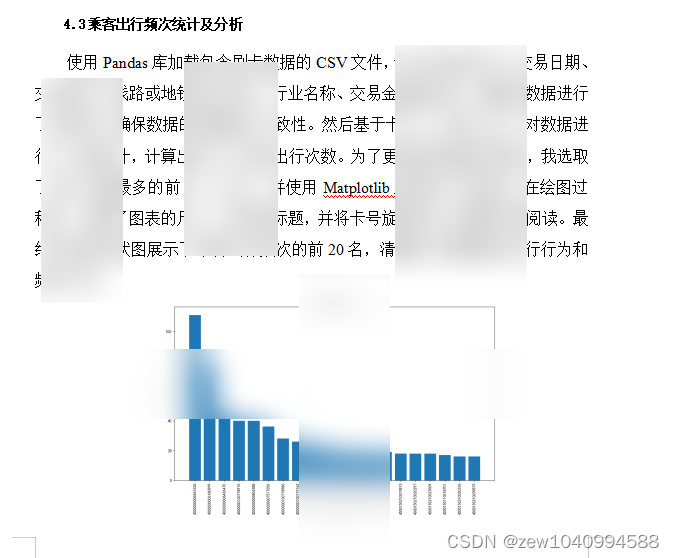
乘客出行频次统计及分析
总结与体会

源码、报告、指导手册获取


欢迎大家点赞、收藏、关注、评论、批评啦 、查看👇🏻👇🏻获取联系方式👇🏻👇🏻
这篇关于交通大数据分析与挖掘实训【对提供的CSV格式数据使用pandas库分析-Matplotlib库绘图】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





