本文主要是介绍线性数据结构-手写队列-哈希(散列)Hash,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是hash散列?
哈希表的存在是为了解决能通过O(1)时间复杂度直接索引到指定元素。这是什么意思呢?通过我们使用数组存放元素,都是按照顺序存放的,当需要获取某个元素的时候,则需要对数组进行遍历,获取到指定的值。而这样通过循环遍历比对获取指定元素的操作,时间复杂度是O(n),也就是说如果你的业务逻辑实现中存在这样的代码是非常拉胯的。那怎么办呢?这就引入了哈希散列表的设计。
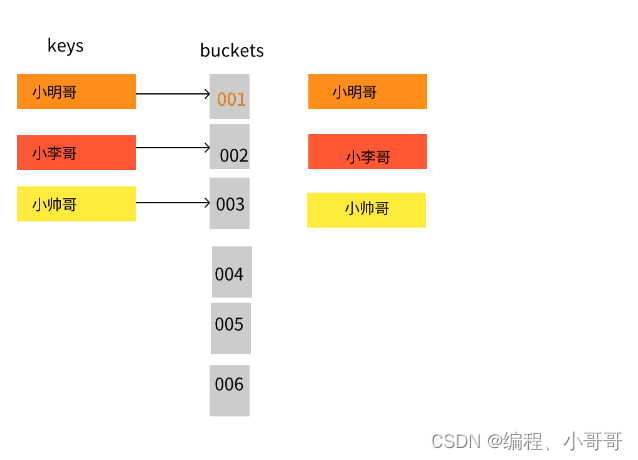
也就是说我们通过对一个 Key 值计算它的哈希并与长度为2的n次幂的数组减一做与运算,计算出槽位对应的索引,将数据存放到索引下。那么这样就解决了当获取指定数据时,只需要根据存放时计算索引ID的方式再计算一次,就可以把槽位上对应的数据获取处理,以此达到时间复杂度为O(1)的情况

哈希散列虽然解决了获取元素的时间复杂度问题,但大多数时候这只是理想情况。因为随着元素的增多,很可能发生哈希冲突,或者哈希值波动不大导致索引计算相同,也就是一个索引位置出现多个元素情况。如图所示;
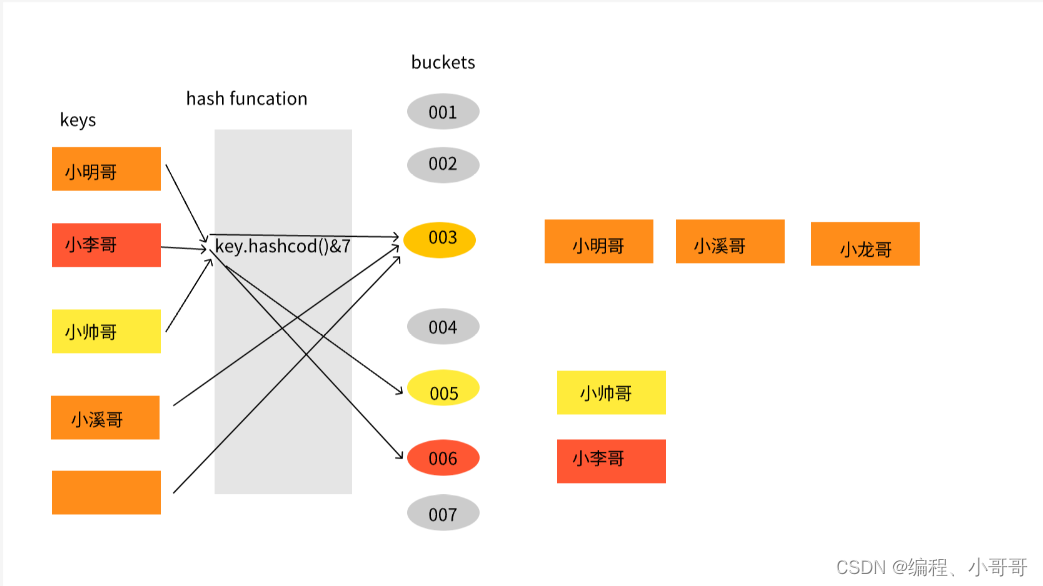
就出现了一系列解决方案,包括;HashMap 中的拉链寻址 + 红黑树、扰动函数、负载因子、ThreadLocal 的开放寻址、合并散列、杜鹃散列、跳房子哈希、罗宾汉哈希等各类数据结构设计。让元素在发生哈希冲突时,也可以存放到新的槽位,并尽可能保证索引的时间复杂度小于O(n)。
以下为实战部分
1:哈希碰撞
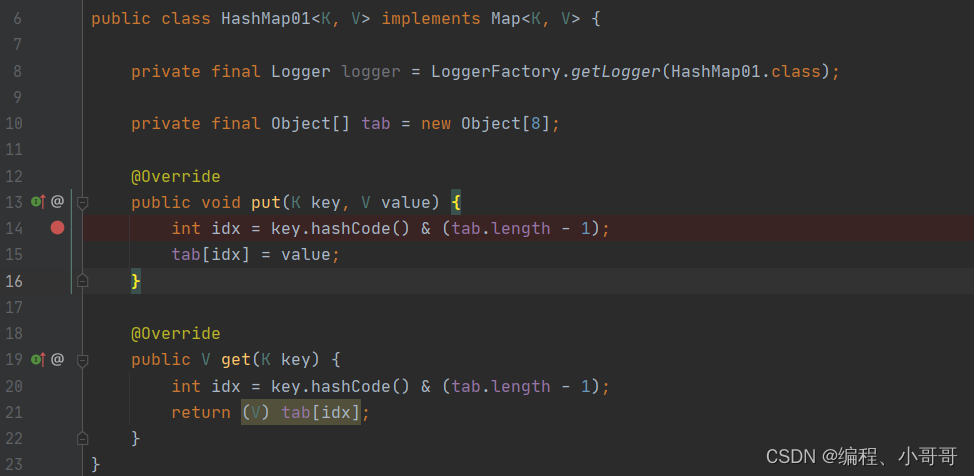
测试上述简单的map结构。
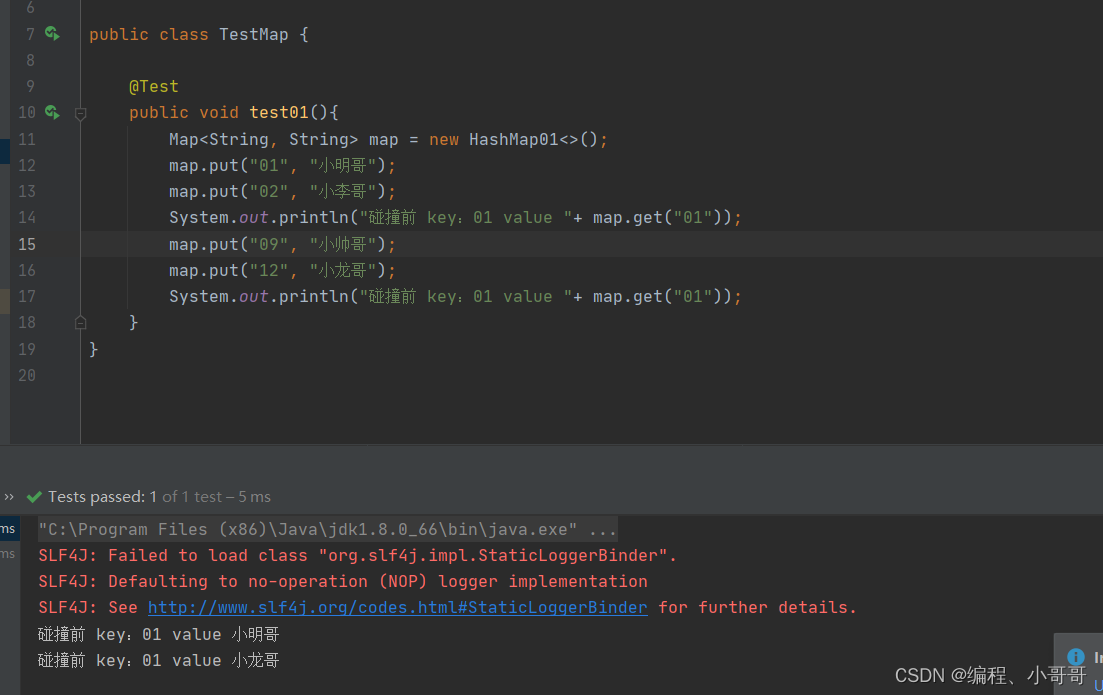
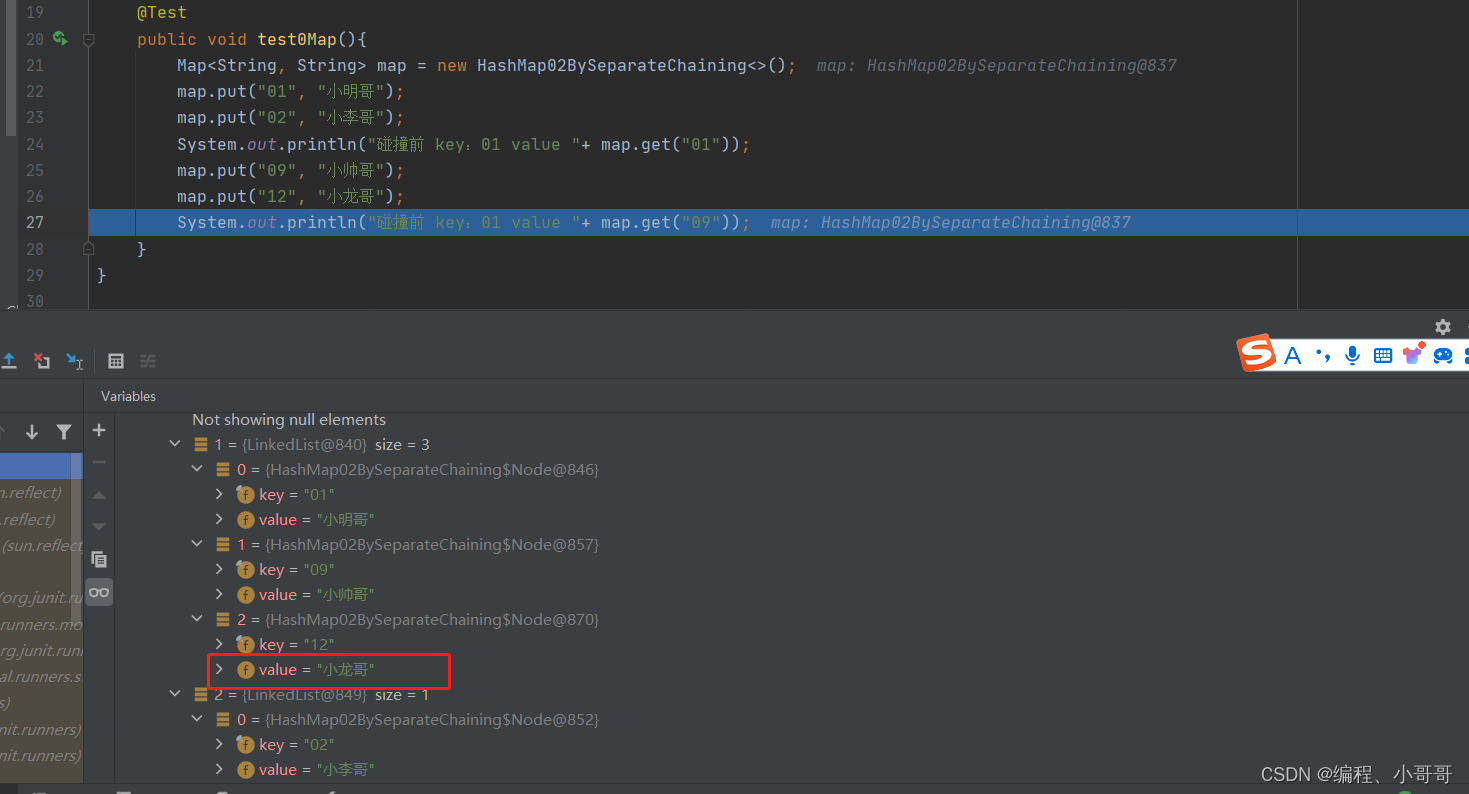
通过测试结果可以看到,碰撞前 map.get(“01”) 的值是花花,两次下标索引碰撞后存放的值则是苗苗
这也就是使用哈希散列必须解决的一个问题,无论是在已知元素数量的情况下,通过扩容数组长度解决,还是把碰撞的元素通过链表存放,都是可以的。
2:拉链寻址
既然我们没法控制元素不碰撞,但我们可以对碰撞后的元素进行管理。比如像 HashMap 中拉链法一样,把碰撞的元素存放到链表上。
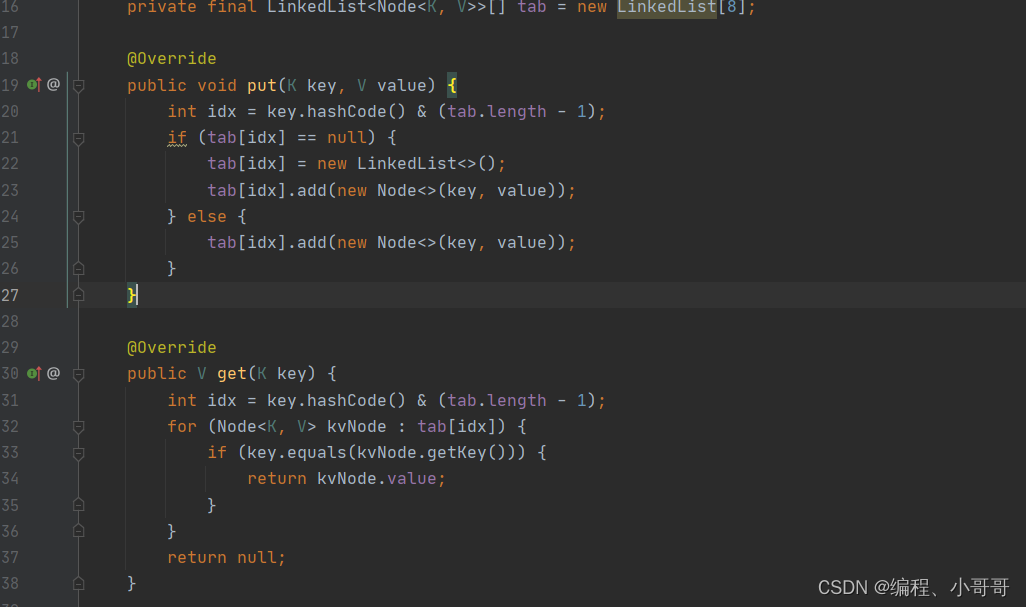
测试拉链寻址
3:开放寻址
除了对哈希桶上碰撞的索引元素进行拉链存放,还有不引入新的额外的数据结构,只是在哈希桶上存放碰撞元素的方式。它叫开放寻址,也就是 ThreaLocal 中运用斐波那契散列+开放寻址的处理方式。
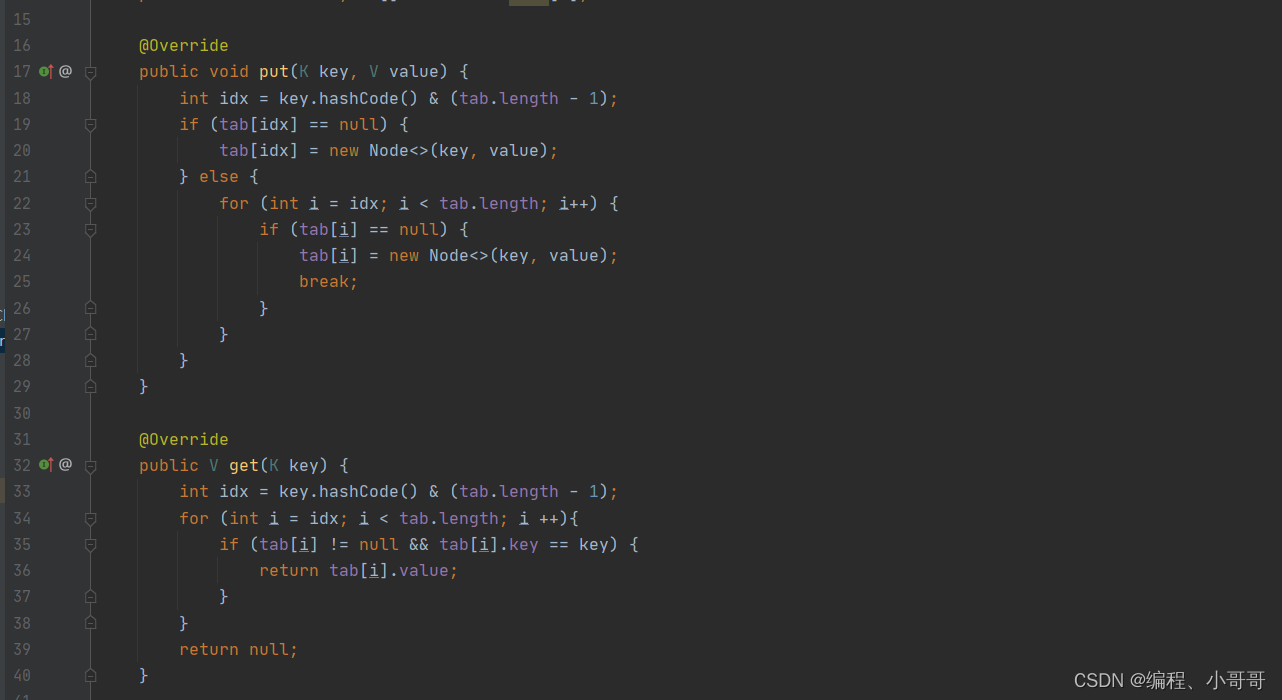
开放寻址的设计会对碰撞的元素,寻找哈希桶上新的位置,这个位置从当前碰撞位置开始向后寻找,直到找到空的位置存放。
在 ThreadLocal 的实现中会使用斐波那契散列、索引计算累加、启发式清理、探测式清理等操作,以保证尽可能少的碰撞。
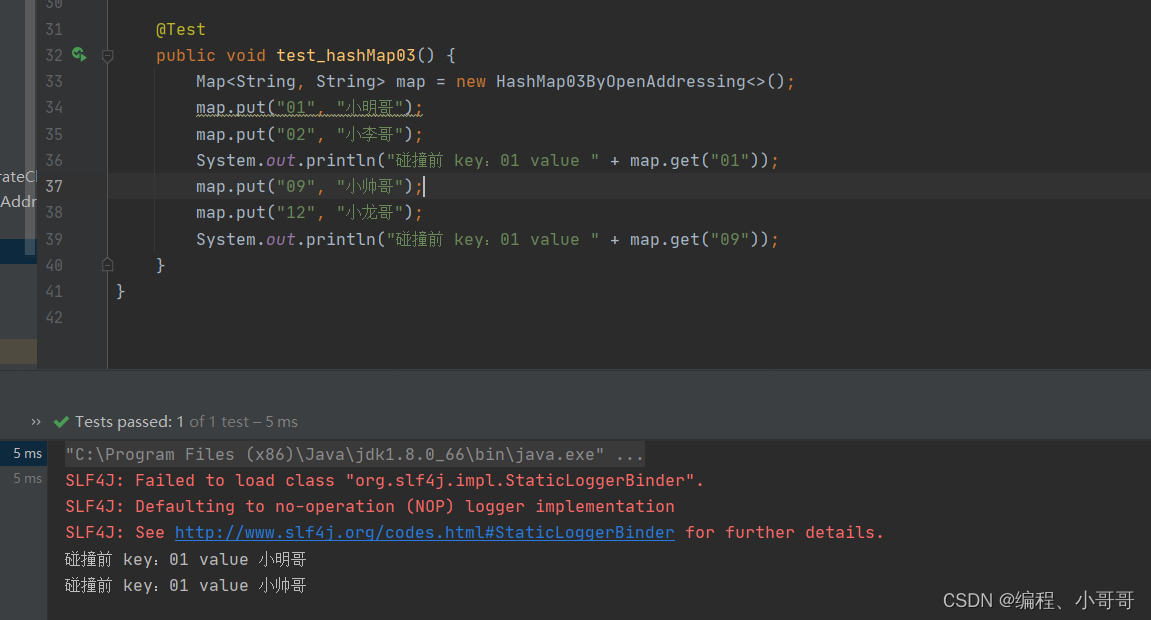
4:罗宾汉哈希
罗宾汉哈希是一种基于开放寻址的冲突解决算法;冲突是通过偏向从其“原始位置”(即项目被散列到的存储桶)最远或最长探测序列长度(PSL)的元素的位移来解决的。
public void put(K key, V value) {Entry entry = new Entry(key, value);int idx = hash(key);System.out.println(key + " " + idx);// 元素碰撞检测while (table[idx] != null) {if (entry.offset > table[idx].offset) {// 当前偏移量不止一个,则查看条目交换位置,entry 是正在查看的条目,增加现在搜索的事物的偏移量和 idxEntry garbage = table[idx];table[idx] = entry;entry = garbage;idx = increment(idx);entry.offset++;} else if (entry.offset == table[idx].offset) {// 当前偏移量与正在查看的检查键是否相同,如果是则它们交换值,如果不是,则增加 idx 和偏移量并继续if (table[idx].key.equals(key)) {// 发现相同值V oldVal = table[idx].value;table[idx].value = value;} else {idx = increment(idx);entry.offset++;}} else {// 当前偏移量小于我们正在查看的我们增加 idx 和偏移量并继续idx = increment(idx);entry.offset++;}}// 已经到达了 null 所在的 idx,将新/移动的放在这里table[idx] = entry;size++;// 超过负载因子扩容if (size >= loadFactor * table.length) {rehash(table.length * 2);}}@Overridepublic V get(K key) {int offset = 0;int idx = hash(key);while (table[idx] != null) {if (offset > table[idx].offset) {return null;} else if (offset == table[idx].offset) {if (table[idx].key.equals(key)) {return table[idx].value;} else {offset++;idx = increment(idx);}} else {offset++;idx = increment(idx);}}return null;}通过测试结果和调试的时候可以看到,哈希索引冲突是通过偏向从其“原始位置”(即项目被散列到的存储桶)最远或最长探测序列长度(PSL)的元素的位移来解决。
最后附上经典面试题。
介绍一下散列表?
为什么使用散列表?
拉链寻址和开放寻址的区别?
还有其他什么方式可以解决散列哈希索引冲突?
对应的Java源码中,对于哈希索引冲突提供了什么样的解决方案?
友友们在评论区写下你们的答案!
以上的是线性数据结构-手写队列-哈希(散列)Hash 若需完整代码 可识别二维码后 给您发代码。

这篇关于线性数据结构-手写队列-哈希(散列)Hash的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





