散列专题

整数Hash散列总结
方法: step1 :线性探测 step2 散列 当 h(k)位置已经存储有元素的时候,依次探查(h(k)+i) mod S, i=1,2,3…,直到找到空的存储单元为止。其中,S为 数组长度。 HDU 1496 a*x1^2+b*x2^2+c*x3^2+d*x4^2=0 。 x在 [-100,100] 解的个数 const int MaxN = 3000

【408数据结构】散列 (哈希)知识点集合复习考点题目
苏泽 “弃工从研”的路上很孤独,于是我记下了些许笔记相伴,希望能够帮助到大家 知识点 1. 散列查找 散列查找是一种高效的查找方法,它通过散列函数将关键字映射到数组的一个位置,从而实现快速查找。这种方法的时间复杂度平均为(

github源码指引:共享内存、数据结构与算法:基于共享内存的散列存储hash
初级代码游戏的专栏介绍与文章目录-CSDN博客 我的github:codetoys,所有代码都将会位于ctfc库中。已经放入库中我会指出在库中的位置。 这些代码大部分以Linux为目标但部分代码是纯C++的,可以在任何平台上使用。 相关专题:共享内存、数据结构与算法_初级代码游戏的博客-CSDN博客 相关文章:20、基于共享内存的散列存储hash-CSD

Javascript实现Java的HashMap(链表散列)
前言 如果你研究过Java中HashMap的源码,你就会知道HashMap底层的存储结构。Java中的HashMap是以链表散列的形式存储的,也就是数组+链表:HashMap中有一个Entry数组,默认的数组长度是16。这个值必须是2的整数次幂,以保证在通过key的hash值来计算entry应该放置的数组下标时可以尽量做到平均分配。而Entry数组中的每一个非空Entry都是一个Entry链表的

两种对 URL 的散列效果很好的函数
http://www.jos.org.cn/1000-9825/15/179.pdf http://wenku.baidu.com/link?url=irOpsGkPESNv76CWnpJXPLxJnguiudD7NRnM96hwkPu4MwS5AsCVrNe_o-Ihr7nw7aY1zhq268cHLsiE3QguF7tzQzLHIjp7X9n7Z81tnV_
Hash散列算法解析
虽然hash算法种类很多很多。然而,由于有先例(MD5,SHA-1,ripemd都不安全),我们很难保证使用那些标准的hash算法不会导致将来的不安全。于是,自己设计一个新的保密的hash算法就成了绝佳的选择。如何设计呢? 作者认为,至少有以下3种方法: 按照普通Hash算法模式设计修改标准Hash算法利用加密算法来构造Hash算法 第一种办法设计到的东西和内容

【shiro】shiro学习笔记3-散列功能
对于密码,有很多种加密方式散列是其中 最常用的,shiro提供了直接支持。 环境 <dependencies><!-- shiro --><dependency><groupId>org.apache.shiro</groupId><artifactId>shiro-core</artifactId><version>1.2.4</version></dependency><!--日志

SM3国密算法:优秀的密码散列函数
随着信息技术的飞速发展,信息安全已成为全球关注的焦点。密码学作为保障信息安全的核心技术,其重要性不言而喻。中国在密码学领域也取得了显著的成就,其中SM3国密算法就是中国自主设计并推广使用的密码学标准之一。 一、SM3算法概述 SM3算法是中国国家密码管理局于2010年发布的一种密码散列函数,旨在为信息安全提供保障。该算法基于密码学原理,能够生成固定长度的散列值,用于验证数据的完整性和真实性。S


C++笔记:Hash Function 散列函数
1. Hash Function 散列函数 简单的Hash实现: class CustomerHash {public:size_t operator()(const Customer& c) const {return hash<std::string>()(c.fname) + // first namehash<std::string>()(c.lname) + // last n

散列(哈希)及其练习题(基础)
目录 散列 字符出现次数 力扣经典题:两数之和 集合运算 交 并 差 字符串的出现次数 散列 导入: 有N个数和M个数,如何判断M个数中每个数是否在N中出现? 思想:空间换时间 创建hashtable,以N个数本身为索引(数组下标)构建 bool hashtable 输入x的过程中,hashtable[x]=True(若要计算出现次数,换成++) 但

线性数据结构-手写队列-哈希(散列)Hash
什么是hash散列? 哈希表的存在是为了解决能通过O(1)时间复杂度直接索引到指定元素。这是什么意思呢?通过我们使用数组存放元素,都是按照顺序存放的,当需要获取某个元素的时候,则需要对数组进行遍历,获取到指定的值。而这样通过循环遍历比对获取指定元素的操作,时间复杂度是O(n),也就是说如果你的业务逻辑实现中存在这样的代码是非常拉胯的。那怎么办呢?这就引入了哈希散列表的设计。 也就是说我们通过对一
python中什么样的数据类型是可散列的?
python里什么样的数据类型是可散列的?可散列也就是可以作为映射(字典、集合)里的键。 如果一个对象是可散列的,那么这个对象在它的生命周期内,它的散列值是不变的 ,而且这个对象需要实现__hash__方法,另外还要有__eq__方法,这样才能跟其他键比较。要注意两个对象相等,它们的散列值一定一样,但两个对象散列值一样它们可能不相等,这就是常说的散列表里的has

js数据结构和算法(五)字典和散列(hash)
什么是字典结构? 字典是以键值对形式存储数据的数据结构,就像电话号码薄里的名字和电话号码那样的一一对应的关系。 javascript的Object类就是以这样的一种字典形式设计的。 键值对在字典中以这样的方式标记:d = {key1 : value1, key2 : value2 }。字典中的键/值对是没有顺序的。如果你想要一个特定的顺序,那么你应该在使用前自己对它们排序。 Di
加密算法、散列算法、摘要、签名、证书、MD5、RSA、SSL通讯等等
加密算法: 有对称加密和非对称加密。对称加密就是加密和解密时用的是同样的算法和密钥, 常见的对称加密算法有DES、3DES、Blowfish、IDEA、RC4、RC5、RC6和AES。而非对称加密是加密和解密用的是不同的密钥, 常见算法有RSA等。 散列算法: 散列(HASH)算法可以将不管多大的原始数据生成定长的数据,而且不同的原始数据一般可以保证经过hash算法计算之后,得到的定长数据不
SHA256安全散列算法
SHA256是安全散列算法SHA(Secure Hash Algorithm)系列算法之一,其摘要长度为256bits,即32个字节,故称SHA256。SHA系列算法是美国国家安全局 (NSA) 设计,美国国家标准与技术研究院(NIST) 发布的一系列密码散列函数,包括 SHA-1、SHA-224、SHA-256、SHA-384 和 SHA-512 等变体。主要适用于数字签名标准(DigitalS
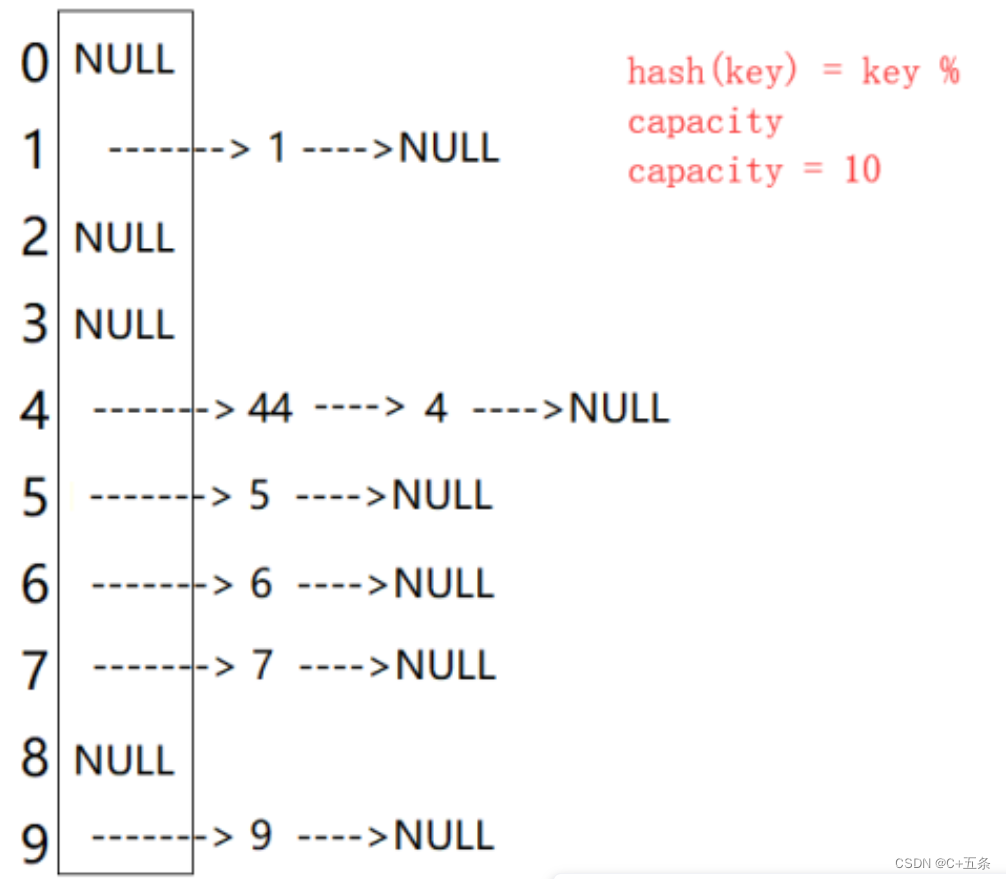
C++王牌结构hash:哈希表开散列(哈希桶)的实现与应用
目录 一、开散列的概念 1.1开散列与闭散列比较 二、开散列/哈希桶的实现 2.1开散列实现 哈希函数的模板构造 哈希表节点构造 开散列增容 插入数据 2.2代码实现 一、开散列的概念 开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表

密码学(一)—— 背景、常用的密码算法简介,单向散列简介、数字签名简介
背景 密码,最初的目的就是用于对信息的加密,计算机领域的密码技术种类繁多,但随着密码学的运用,密码还用于身份认证,防止否认等功能上。最基本的,是信息加密解密分为对称加密和非对称加密,这两者的区别在于是否在加密解密时是否使用了相同的密钥。除了信息的加密解密,还有用于确认数据完整性的单向散列技术,又称魏密码检验、指纹、消息摘要。信息的加密解密与信息的单向散列的区别时,加密解密是可以通过密钥来获取其加
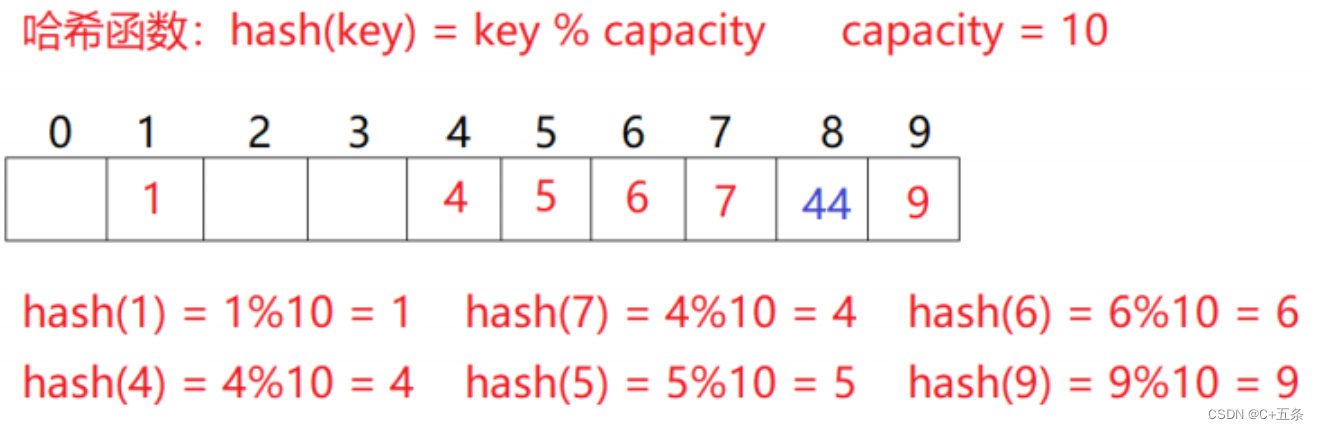
C++王牌结构hash:哈希表闭散列的实现与应用
一、哈希概念 顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素 时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O(log n),搜索的效率取决于搜索过程中元素的比较次数。 理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键
数据结构(六)—— 散列查找(3):冲突处理方法
数据结构系列内容的学习目录 → \rightarrow →浙大版数据结构学习系列内容汇总。 3. 冲突处理方法3.1 处理冲突的方法3.2 开放定址法3.2.1 线性探测法3.2.2 平方探测法3.2.3 双散列探测法3.2.4 再散列 3.3 分离链接法3.4 冲突处理方法的实现3.4.1 平方探测法处理冲突3.4.2 分离链接法处理冲突 3. 冲突处理方法 3

算法笔记读书思考---散列
散列 所谓散列,就是元素通过一个函数转化为整数,使得该整数可以尽量唯一地代表这个元素。我们可以把这个转化函数记为:H(),把这个元素记为key,那么这个元素转化后的整数为H(key)。 常用的散列函数有直接定址法,平方取中法,除留取余法等方法。今天我想着重讨论的是直接定址法,这是散列函数中我认为最常用,也是最实用,建议大家掌握。 直接定址法其实就是指的数恒等变换即H(key) = key,这个在

解决哈希表的冲突-开放地址法和链地址法 ---二次探测再散列的一个人名的例子
解决哈希表的冲突-开放地址法和链地址法 2010-10-12 13:50:51| 分类: C++编程|字号 订阅 在实际应用中,无论如何构造哈希函数,冲突是无法完全避免的。 1 开放地址法 这个方法的基本思想是:当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。 这个过程可用下式描述: H i ( key
Cuckoo hash - 布谷鸟散列 学习笔记
转载: CuckooHash(布谷鸟散列) 2020/11/13 布谷鸟散列是一种占用空间少,查询速度快的一个哈希算法,上面的博客写的很详细,mark一下,有机会再补充自己的实践代码。 2021/1/31 现在有很多基于cuckoo优化的hash算法,比如cocuckoo,smartcuckoo等。最近在读这两篇,读完总结一下。

哈希算法--7-14 字符串关键字的散列映射 (25 分)
除留余数法设计哈希表 : 由该式子得到value在哈希表中的存储位置:index = value % p;这里为了尽量的减少冲突,而且让value在哈希表中尽可能的均匀分布,p的选择就至关重要了。而合理选择p的经验是:若散列表表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。 平方探测法: 冲突是不可避免的,本题中提到的解决冲突的平方探测法:
继续xxx定律【浙江大学】【哈希散列】
牛客网题目链接 思路 只要是在其他数字计算过程中出现的就叫覆盖数,先用哈希表存起来,把可能关键数放在向量中,注意在输出时还需要判断一遍关键数。 #include <iostream>#include <vector>#include <string>#include <cmath>#include <algorithm>#include <queue>#include <cstd