本文主要是介绍数据结构(六)—— 散列查找(3):冲突处理方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据结构系列内容的学习目录 → \rightarrow →浙大版数据结构学习系列内容汇总。
- 3. 冲突处理方法
- 3.1 处理冲突的方法
- 3.2 开放定址法
- 3.2.1 线性探测法
- 3.2.2 平方探测法
- 3.2.3 双散列探测法
- 3.2.4 再散列
- 3.3 分离链接法
- 3.4 冲突处理方法的实现
- 3.4.1 平方探测法处理冲突
- 3.4.2 分离链接法处理冲突
3. 冲突处理方法
3.1 处理冲突的方法
常用处理冲突的思路:
⋄ \diamond ⋄ 换个位置:开放地址法
⋄ \diamond ⋄ 同一位置的冲突对象组织在一起:链地址法
3.2 开放定址法
★ \bigstar ★ 开放定址法(Open Addressing)
一旦产生了冲突(该地址已有其它元素),就按某种规则去寻找另一空地址;
若发生了第i次冲突,试探的下一个地址将增加d,基本公式是: h i ( k e y ) = ( h ( k e y ) + d i ) h_{i}(key)=(h(key)+d_{i}) hi(key)=(h(key)+di) mod TableSize( 1 ≤ \leq ≤ i < < < TableSize );
d i d_{i} di决定了不同的解决冲突方案:线性探测( d i = i d_{i}=i di=i)、平方探测( d i = ± i 2 d_{i}=\pm i^{2} di=±i2)、双散列( d i = i ∗ h 2 ( k e y ) d_{i}=i*h_{2}(key) di=i∗h2(key))。
3.2.1 线性探测法
线性探测法(Linear Probing): 以增量序列1,2,…,( TableSize -1)循环试探下一个存储地址。
要注意“聚集”现象。
例: 设关键词序列为{ 47,7,29,11,9,84,54,20,30 },散列表表长TableSize =13(装填因子α= 9/13= 0.69);散列函数为h(key) = key mod 11。
用线性探测法处理冲突,列出依次插入后的散列表,并估算查找性能。

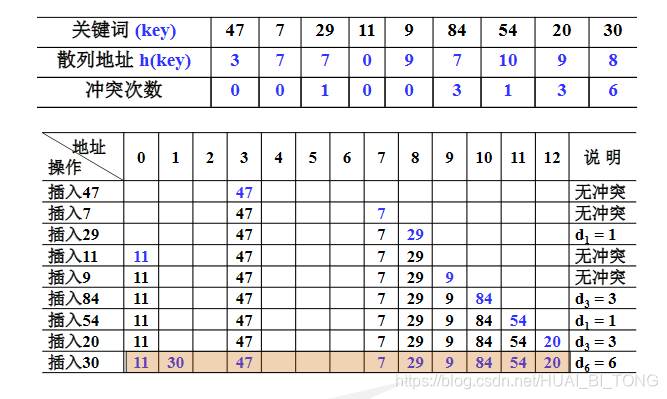
散列表查找性能分析:
⋄ \diamond ⋄ 成功平均查找长度(ASLs)
⋄ \diamond ⋄ 不成功平均查找长度(ASLu)

分析: ASLs:查找表中关键词的平均查找比较次数(其冲突次数加1)
ASL s = (1+7+1+1+2+1+4+2+4)/9 = 23/9 ≈ 2.56
ASLu:不在散列表中的关键词的平均查找次数(不成功)
一般方法:将不在散列表中的关键词分若干类。
如:根据H(key)值分类
ASL u = (3+2+1+2+1+1+1+9+8+7+6)/11 = 41/11 ≈ 3.73
3.2.2 平方探测法
平方探测法(Quadratic Probing)(或二次探测法):以增量序列 1 2 1^{2} 12, − 1 2 -1^{2} −12, 2 2 2^{2} 22, − 2 2 -2^{2} −22,… …, q 2 q^{2} q2, − q 2 -q^{2} −q2且q ≤ LTableSize/2」循环试探下一个存储地址。
例: 设关键词序列为{ 47,7,29,11,9,84,54,20,30 },散列表表长TableSize = 11;散列函数为h(key) = key mod 11。
用平方探测法处理冲突,列出依次插入后的散列表,并估算ASLs。

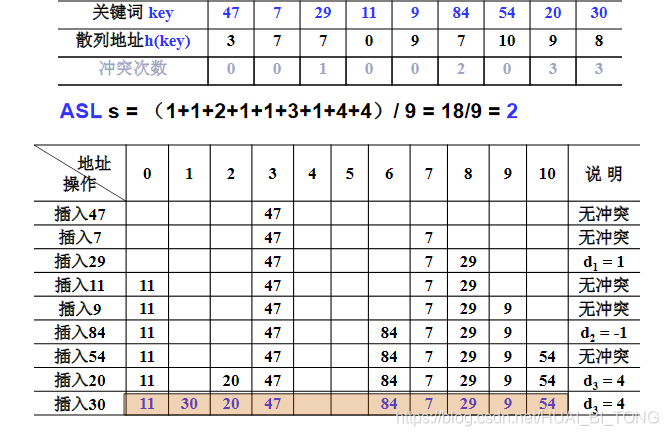
是否有空间,平方探测(二次探测)就能找得到?

有定理显示:如果散列表长度TableSize是某个4k+3(k是正整数)形式的素数时,平方探测法就可以探查到整个散列表空间。
散列表数据结构定义如下所示。
typedef struct HashTbl *HashTable;
struct HashTbl{int TableSize; //散列表的大小Cell *TheCells; //数组
}H;
散列表的初始化代码如下所示。
HashTable lnitializeTable( int TableSize )
{HashTable H;if (TableSize < MinTablesize){Error("散列表太小");return NULL;}// 分配散列表H=(HashTable)malloc(sizeof(struct HashTbl));if (H = NULL)FatalError("空间溢出!!!");H->TableSize = NextPrime(TableSize);// 分配散列表CellsH->TheCells = (Cell *)malloc(sizeof(Cell)*H->TableSize);if(H->Thecells == NULL)FatalError("空间溢出!!!");for(int i = 0; i < H>Tablesize; i++)H->TheCells[i].Info = Empty;return H;
}

使用平方探测法进行散列表的查找操作,代码如下所示。
Position Find(ElementType Key, HashTable H ) //平方探测
{Position CurrentPos, NewPos;int CNum = 0; // 记录冲突次数NewPos = CurrentPos = Hash(Key, H->TableSize);while(H->TheCells[NewPos].Info != Empty && H->Thecells[NewPos].Element != Key) {// 字符串类型的关键词需要strcmp函数!!if(++CNum % 2) // 判断冲突的奇偶次NewPos = CurrentPos +(CNum+1)/2*(CNum+1)/2;while(NewPos >= H->TableSize)NewPos -= H->TableSize;else {NewPos = CurrentPos - CNum/2 * CNum/2;while(NewPos < 0)NewPos += H->TableSize;}}return NewPos;
}

散列表的插入操作,代码如下所示。
void Insert(ElementType Key, HashTable H) // 插入操作
{Position Pos;Pos = Find(Key, H);if(H->TheCells[Pos].Info != Legitimate ) // 确认在此插入{H->TheCells[Pos].Info = Legitimate;H->Thecells[Pos].Element = Key;// 字符串类型的关键词需要strcpy函数!!}
}
在开放地址散列表中,删除操作要很小心。通常只能“懒惰删除”,即需要增加一个“删除标记(Deleted)”,而并不是真正删除它。以便查找时不会“断链”。其空间可以在下次插入时重用。
3.2.3 双散列探测法
双散列探测法(Double Hashing): d i d_{i} di为 i ∗ h 2 ( k e y ) i*h_{2}(key) i∗h2(key), h 2 ( k e y ) h_{2}(key) h2(key)是另一个散列函数。
探测序列: h 2 ( k e y ) h_{2}(key) h2(key), 2 h 2 ( k e y ) 2h_{2}(key) 2h2(key), 3 h 2 ( k e y ) 3h_{2}(key) 3h2(key),…
⋄ \diamond ⋄ 对任意的key, h 2 ( k e y ) ≠ 0 h_{2}(key)≠0 h2(key)=0 !
⋄ \diamond ⋄ 探测序列还应该保证所有的散列存储单元都应该能够被探测到。
选择以下形式有良好的效果:
h 2 ( k e y ) h_{2}(key) h2(key)= p - (key mod p)
其中,p < TableSize,p、TableSize都是素数。
3.2.4 再散列
当散列表元素太多(即装填因子α太大)时,查找效率会下降;
⋄ \diamond ⋄ 实用最大装填因子一般取0.5<= a<= 0.85
当装填因子过大时,解决的方法是加倍扩大散列表,这个过程叫做“再散列(Rehashing)”。
3.3 分离链接法
分离链接法(Separate Chaining): 将相应位置上冲突的所有关键词存储在同一个单链表中。
例: 设关键字序列为{ 47,7,29,11,16,92,22,8,3,50,37,89,94,21 };散列函数取为h(key) = key mod 11;用分离链接法处理冲突。
散列表数据结构定义如下所示。
struct HashTbl {int TableSize; // 散列表的大小List TheLists; // 链表
}*H;
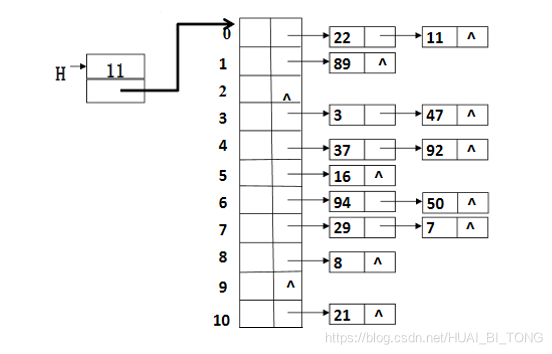
⋆ \star ⋆ 表中有9个结点只需1次查找;
⋆ \star ⋆ 5个结点需要2次查找;
⋆ \star ⋆ 查找成功的平均查找次数:ASL s=(9+5*2)/14=1.36。
使用分离链接法进行散列表的查找操作,代码如下所示。
typedef struct ListNode *Position, *List;
struct ListNode {ElementType Element;Position Next;
};
typedef struct HashTbl *HashTable;
struct HashTbl {int TableSize;List TheLists;
};
Position Find(ElementType Key, HashTable H)
{Position P;int Pos;Pos = Hash(Key, H->TableSize); // 初始散列置P = H->TheLists[Pos].Next; // 获得链表头while(P!=NULL && strcmp(P->Element, Key))P = P->Next;return P;
}
3.4 冲突处理方法的实现
3.4.1 平方探测法处理冲突
设关键词序列为{ 47,7,29,11,9,84,54,20,30 },用平方探测法处理冲突,得到依次插入后的散列表,实现代码如下所示。
#include<iostream>
using namespace std;#define MAXTABLESIZE 100000 // 允许开辟的最大散列表长度
typedef int Index; // 散列地址类型
typedef int ElementType; // 关键词类型用整型
typedef Index Position; // 数据所在位置与散列地址是同一类型// 散列单元状态类型,分别对应:有合法元素、空单元、有已删除元素
typedef enum {Legitimate, Empty, Deleted} EntryType; // 定义单元状态类型 typedef struct HashEntry Cell; // 定义散列表单元类型
struct HashEntry { // 哈希表存值单元 ElementType Data; // 存放元素EntryType Info; // 单元状态
};typedef struct HashTbl *HashTable; // 散列表类型
struct HashTbl { // 哈希表结构体 int TableSize; // 表的最大长度 Cell *Cells; // 存放散列单元数据的数组
};int NextPrime(int N); // 查找素数
HashTable CreateTable(int TableSize); // 创建哈希表
Index Hash(int Key, int TableSize); // 哈希函数 // 查找素数
int NextPrime(int N) // 返回大于N且不超过MAXTABLESIZE的最小素数
{int p = (N % 2) ? N + 2 : N + 1; // 从大于 N 的下个奇数开始int i;while (p <= MAXTABLESIZE) {for (i = (int)sqrt(p); i > 2; i--)if (!(p%i)) // p 不是素数 break;if (i == 2) // for正常结束,说明p是素数break;p += 2; // 继续试探下个奇数 }return p;
}// 创建哈希表
HashTable CreateTable(int TableSize)
{HashTable H;H = (HashTable)malloc(sizeof(struct HashTbl));H->TableSize = NextPrime(TableSize); // 保证散列表最大长度是素数 H->Cells = (Cell *)malloc(sizeof(Cell)*H->TableSize); // 初始化单元数组 for (int i = 0; i < H->TableSize; i++) // 初始化单元数组状态为“空单元”H->Cells[i].Info = Empty;return H;
}// 平方探测查找
Position Find(HashTable H, ElementType Key)
{Position CurrentPos, NewPos;int CNum = 0; // 记录冲突次数CurrentPos = NewPos = Hash(Key, H->TableSize); // 初始散列位置while (H->Cells[NewPos].Info != Empty && H->Cells[NewPos].Data != Key) // 当该位置的单元非空,并且不是要找的元素时,发生冲突{// 统计1次冲突,并判断奇偶次if (++CNum % 2) { // 冲突奇数次发生 NewPos = CurrentPos + (CNum + 1) / 2 * (CNum + 1) / 2; // 增量为+[(CNum+1)/2]^2while (H->TableSize <= NewPos) // 如果越界,一直减直到再次进入边界{NewPos -= H->TableSize; // 调整为合法地址}}else // 冲突偶数次发生{ NewPos = CurrentPos - CNum / 2 * CNum / 2; // 增量为-(CNum/2)^2 while (NewPos < 0) // 如果越界,一直加直到再次进入边界{NewPos += H->TableSize; // 调整为合法地址}}}return NewPos; // 此时NewPos或者是Key的位置,或者是一个空单元的位置(表示找不到)
}// 插入
bool Insert(HashTable H, ElementType Key, int i)
{Position Pos = Find(H, Key); // 先检查Key是否已经存在if (H->Cells[Pos].Info != Legitimate) // 如果这个单元没有被占,说明Key可以插入在此 {H->Cells[Pos].Info = Legitimate;H->Cells[Pos].Data = Key;return true;}else {cout << "键值已存在" << endl;return false;}
}// 除留余数法哈希函数
Index Hash(int Key, int TableSize)
{return Key % TableSize;
}int main()
{HashTable H = CreateTable(9);int N;cin >> N;for (int i = 0; i < N; i++) {int tmp;cin >> tmp;Insert(H, tmp, i);}for (int i = 0; i < H->TableSize; i++)cout << i << " " << H->Cells[i].Data << endl;system("pause");return 0;
}
测试效果如下图所示。

3.4.2 分离链接法处理冲突
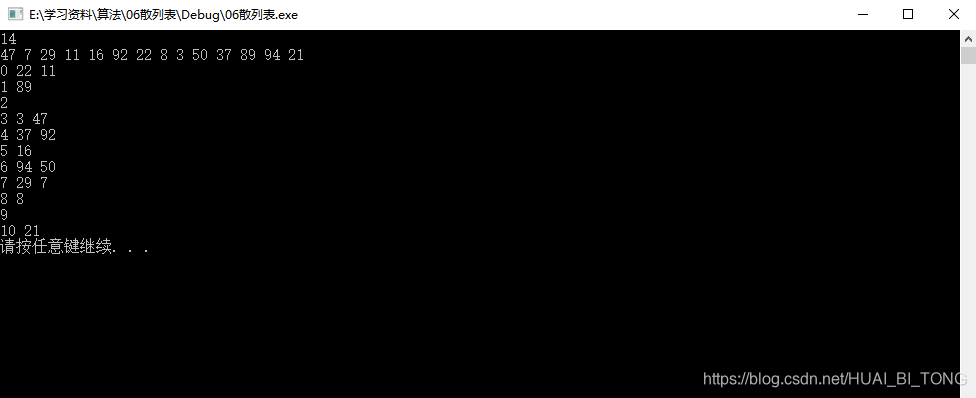
设关键词序列为{ 47,7,29,11,16,92,22,8,3,50,37,89,94,21 },用分离链接法处理冲突,得到依次插入后的散列表,实现代码如下所示。
#include<iostream>
using namespace std;#define MAXTABLESIZE 100000 // 允许开辟的最大散列表长度
typedef int Index; // 散列地址类型
typedef int ElementType; // 关键词类型用整型// 单链表的定义
typedef struct LNode *PtrToLNode;
struct LNode { // 单链表 ElementType Data;PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;typedef struct TblNode *HashTable; // 散列表
struct TblNode { // 散列表结点定义int TableSize; // 表的最大长度 List Heads; // 指向链表头结点的数组
};// 查找素数
int NextPrime(int N)
{int p = (N % 2) ? (N + 2) : (N + 1); // 比 tablesize 大的奇数 int i;while (p <= MAXTABLESIZE) {for (i = (int)sqrt(p); i > 2; i--)if (!(p%i))break;if (i == 2) // 找到素数了 break;p += 2; // 下一个奇数}return p;
}// 创建哈希表
HashTable CreateTable(int TableSize)
{HashTable H;H = (HashTable)malloc(sizeof(struct TblNode));H->TableSize = NextPrime(TableSize);H->Heads = (List)malloc(sizeof(struct TblNode) * H->TableSize);for (int i = 0; i < H->TableSize; i++)H->Heads[i].Next = NULL; // 链表头:H->Heads[i] 是不存东西的 return H;
}// 除留余数法哈希函数
Index Hash(int TableSize, ElementType Key)
{return Key % TableSize;
}// 查找
Position Find(HashTable H, ElementType Key)
{Index pos = Hash(H->TableSize, Key); // 初始散列位置Position P = H->Heads[pos].Next; // 从该链表的第1个结点开始 while (P && P->Data != Key) // 当未到表尾,并且Key未找到时P = P->Next;return P; // 此时P或者指向找到的结点,或者为NULL
}// 插入
bool Insert(HashTable H, ElementType Key)
{Position P, NewCell;Index pos;P = Find(H, Key);if (!P) // 关键词未找到,可以插入 {NewCell = (Position)malloc(sizeof(struct LNode));NewCell->Data = Key;pos = Hash(H->TableSize, Key); // 初始散列表地址NewCell->Next = H->Heads[pos].Next; // 将NewCell插入为H->Heads[Pos]链表的第1个结点H->Heads[pos].Next = NewCell;return true;}else // 关键词已存在{cout << "键值已存在" << endl;return false;}
}void Print(HashTable H)
{for (int i = 0; i < H->TableSize; i++) {cout << i;List p = H->Heads[i].Next;while (p) {cout << " " << p->Data;p = p->Next;}cout << endl;}
}void DestroyTable(HashTable H)
{Position P, tmp;for (int i = 0; i < H->TableSize; i++) // 释放每个链表的结点{P = H->Heads[i].Next;while (P){tmp = P->Next;free(P);P = tmp;}}free(H->Heads); // 释放头结点数组free(H); // 释放散列表结点
}int main()
{HashTable H = CreateTable(9);int N;cin >> N;for (int i = 0; i < N; i++) {int tmp;cin >> tmp;Insert(H, tmp);}Print(H);DestroyTable(H);system("pause");return 0;
}
测试效果如下图所示。
这篇关于数据结构(六)—— 散列查找(3):冲突处理方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




