本文主要是介绍深度学习目标检测算法SSD300 训练自己的数据与测试(基于Keras WIN10 Python3.6)数据集制作、代码详细介绍 (源代码、相关软件及权值下载),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于Keras搭建的SSD300目标检测神经网络
先看看效果(图片来源:视觉中国 www.vcg.com,这里只做演示使用,我也不获利,请视觉中国不要告我,实在不让我用就联系我删了吧,感恩)

1. 运行需要的模块
代码运行需要部分必须的Python模块包括:(部分依赖模块未列出)
- Keras >= 2.0.0
- TensorFlow >= 1.7.0
- Tensorboard >= 1.7.0
- numpy >= 1.9.0
- opencv >= 3.3.1
2. 测试代码运行情况
下载好的代码及权值文件(源代码及权值文件免费下载见文章尾)
最终你的项目文件夹应该是这样的
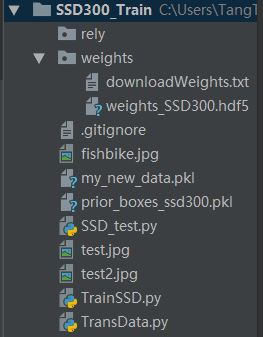
将下载好的权值文件放在 SSD300_Train/weights 文件夹中
运行 SSD_test.py 即可得到上图的效果 ~ ~
如果没报错就说明的Python环境配置正确了,恭喜进入下一阶段
3. SSD_test.py 讲解
项目自带的权值文件是以VOC数据集训练的,能够检测20种目标。详细内部实现不作详细讲解,主要介绍下面的主要部分。

4. 训练自己的数据集
4.1 创建自己的数据集
代码的数据集使用的VOC的数据格式(不知道的请自行百度一下,这里不细说),使用ImgLabel软件标注,软件下载可以去GitHub搜索imglabel源代码copy下来,使用方法请自行百度。文章尾部也给出了已经编译好了的exe版本下载地址(免费),嫌麻烦的也可以直接下载我上传到CSDN上的版本
重点!!!!!!
- 在进行标计前建议将拍摄的原始图像进行一定的缩放,保证图片的大小在200k左右,要不训练超级慢。
- 标记前请一定先确定好自己数据集存放的位置,一旦确定就不要变了,要不会很麻烦。
具体原因:代码中图片的具体读取是通过 读取标记文件(.xml)中的图片路径来读取图片的(如下图中红线的部分),如果数据集位置变了但文件中有没改这里,就会读取不到图片。
使用我上传到CSDN上的imglabel软件标注的同学可能会注意到路径中缺少文件后缀,请不要担心,继续往下看。

- 标注时同一类目标的名称一定要完全一样(包括大小写),要不就不是同一类了不是?
- 标注完毕后在数据集文件夹中创建一个name.txt,将数据集中的类别名称填入文件中,每个类名一行(例如下图),一定要和数据集中的类名完全一样。
5. 开始训练
训练包括两部,第一步生成标记数据文件(文件夹中的my_new_data.pkl);第二步配置训练参数开始训练。
5.1 生成标记数据文件
注意:每次更改训练集内的图片都应该重新生成标记数据文件!!!!
生成标记数据文件主要用到 TransData.py
使用时主要修改main函数

4.1中提到的.xml文件中的图片路径中缺少文件后缀同学请执行下一步,如果没有出现文件后缀丢失,请忽略。

没有后缀的在这里添加上后缀(包括后缀中的点), 如果数据集中的图片后缀不统一的话还是写个脚本将.xml文件中的后缀添加上,有需要的同学请评论联系我。
生成成功后应该会有一个.pkl文件产生(或者更新覆盖原来的)。
5.2 配置训练参数开始训练
主要修改TrainSSD.py文件
修改参数主要包括以下几个:
-
设置训练集的比例
此处设置训练集的个数占总的数据集的0.8,剩下的0.2为测试集
-
设置训练的batch_size
此处设置batch_size为每个batch 16张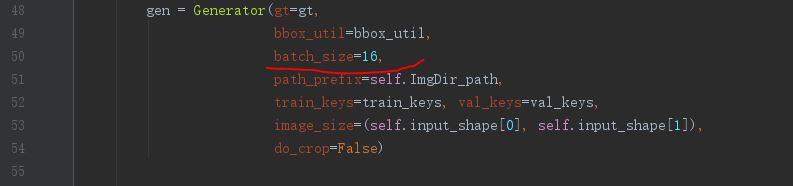
-
设置冻结层
这里涉及到迁移学习的一点概念思想,感兴趣的同学建议自己查查。这里我们将产生特征层的网络部分冻结起来,只训练类别预测和位置回归的部分,这样即使训练集很小也可以获得不错的训练效果。当然如果你的训练集比较大还是重头训练的好。

-
设置基础学习率
训练时学习率采用指数下降方式,每训练一个epoch,梯度都会改变,这里设置的是基础学习率

-
设置训练回合数
这里设置训练100回合
5.3 开始训练
按实际情况更改下列变量的值

修改完成后,开始训练,每训练一个回合后,权值文件会自动保存,同时代码中设置了Tensorboard的回调函数,可以调用tensorboard可视化训练信息。
调用tensorboard
打开cmd cd 到项目文件夹中 输入 tensorboard --logdir logs
将返回的连接复制到浏览器中打开即可
下载源代码
为了保障所有人能免费下载到源代码,同时推广一下自己建立的公众号(主要分享一些教程),请扫描下方二维码关注公众号回复相应的关键字获取下载链接
-
源代码及权值下载地址:回复“SSD训练”。
-
imglabel标注工具下载地址:回复“标注工具”
-
有需要rely源码的直接回复“rely下载”,就不一一发邮箱了。

这篇关于深度学习目标检测算法SSD300 训练自己的数据与测试(基于Keras WIN10 Python3.6)数据集制作、代码详细介绍 (源代码、相关软件及权值下载)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









