本文主要是介绍多项式和Bezier曲线拟合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1. 多项式拟合
- 2. Bezier曲线拟合
- 3. 源码地址
1. 多项式拟合
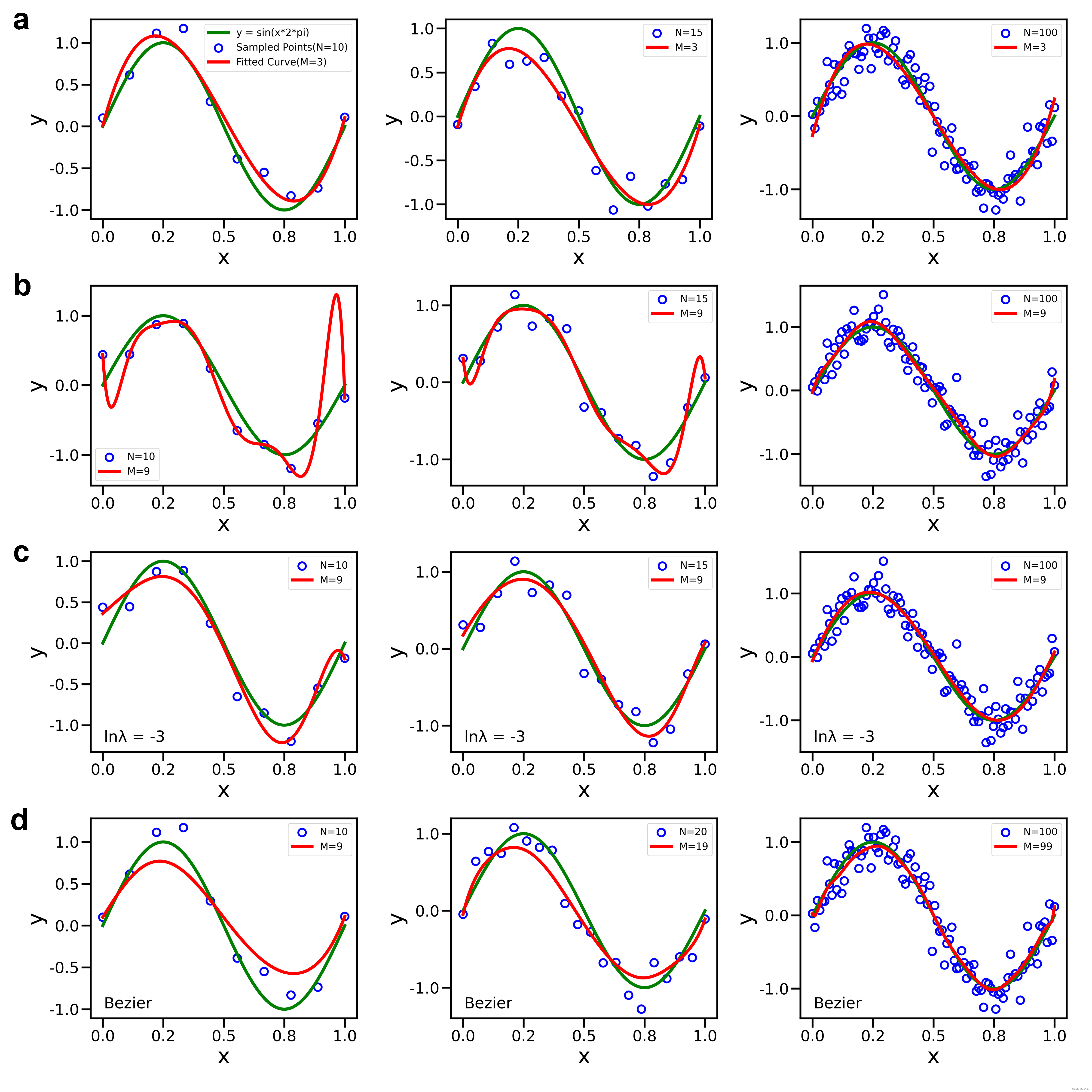
在曲线拟合中,多项式拟合方法的性能受到三个主要因素的影响:采样点个数、多项式阶数和正则项。
- 采样点个数 N N N:从Figure 1中可以看出较少的采样点个数可能导致过拟合(overfitting)问题,即拟合曲线过于贴合训练数据,但在新数据上的泛化能力较差。而较多的采样点个数可以提供更多的信息,有助于拟合更精确的曲线,但也会增加计算的复杂性,所以当采样点增加到100时所有方法的拟合效果都很好。
- 多项式阶数 M M M:随着多项式的阶数增加,模型的复杂度也随之增加。高阶多项式可以更好地拟合复杂的曲线,但也容易发生过拟合,比如9阶比3阶在采样点较少时表现非常差。如果选择了过低的多项式阶数,模型可能无法捕捉到数据中的复杂模式,但由于该曲线比较简单,所以在图中无法体现这一点。
- 正则项 λ \lambda λ:正则项用于控制模型的复杂度,避免过拟合。它通过在损失函数中引入一个惩罚项,限制模型参数的大小。更大的正则化参数(如L1或L2正则化中的λ值)会使得模型更加趋向于简单的拟合曲线。如果正则化参数过大,可能导致欠拟合(underfitting)问题,模型无法很好地拟合数据。我们这里选择 l n λ = − 3 ln\lambda=-3 lnλ=−3在9阶多项式拟合中表现比较合适,采样点较少时大大降低模型复杂度,拟合结果更贴合真实曲线。
# 使用多项式拟合
def polynomial_fit(x, y, degree, alpha=None):coeffs = np.polyfit(x, y, degree, rcond=alpha)return coeffs# 返回拟合曲线的计算结果
def polynomial_curve(x, coeffs):return np.polyval(coeffs, x)
2. Bezier曲线拟合
Bezier曲线是计算机图形学中广泛使用的一种参数曲线,它由一组控制点定义,并可以创建平滑的曲线路径。这种曲线在图形设计、动画和其他领域有着广泛的应用。在数据分析和信号处理领域,Bezier曲线也可以用来对散点数据进行平滑拟合。
我们这里将采样点作为Bezier曲线的控制点进行拟合,采样点较少时不如3阶多项式,而采样点达到20个及以上时效果有了明显提升。
在实践中,确定合适的贝塞尔曲线控制点是一个迭代的过程,需要根据实际情况不断调整和改进。经验和直觉在初始阶段可能起到重要的作用,但通过实际观察和评估,结合优化算法和交叉验证,可以逐步优化控制点的位置,以获得更好的拟合效果和形状调整。
下面源码是简单的Bezier曲线拟合实现:
# 使用贝塞尔(Bernstein basis)曲线进行拟合
class BezierCurve:def __init__(self, control_points, ):self.control_points = control_pointsself.n = len(control_points) - 1def bernstein_basis(self, i, n, t):"""Calculate the i-th Bernstein basis polynomial of degree n at t."""return np.math.comb(n, i) * (t ** i) * ((1 - t) ** (n - i))def evaluate(self, t):"""Evaluate the Bezier curve at the given parameter t."""point = np.zeros_like(self.control_points[0])for i in range(self.n + 1):point += self.control_points[i] * self.bernstein_basis(i, self.n, t)return pointdef fit(self, samples):"""Fit the Bezier curve to the given samples using the least squares method."""t = np.linspace(0, 1, self.n + 1)A = np.zeros((len(samples), self.n + 1))for i, sample in enumerate(samples):for j in range(self.n + 1):A[i, j] = self.bernstein_basis(j, self.n, t[i])b = samplesx, _, _, _ = np.linalg.lstsq(A, b, rcond=None)self.control_points = x3. 源码地址
如果对您有用的话可以点点star哦~
https://github.com/Jurio0304/cs-math/blob/main/hw1_bezier_fitting.py
这篇关于多项式和Bezier曲线拟合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!