本文主要是介绍机器学习算法(二):1 逻辑回归的从零实现(普通实现+多项式特征实现非线性分类+正则化实现三个版本),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、普通实现
- 1 数据集准备
- 2 逻辑回归模型
- 3 损失函数
- 4 计算损失函数的梯度
- 5 梯度下降算法
- 6 训练模型
- 二、多项式特征实现非线性分类
- 1 数据准备与多项式特征构造
- 2 逻辑回归模型
- 三、逻辑回归 --- 正则化实现
- 1 数据准备
- 2 逻辑回归模型
- 3 正则化损失函数
- 4 计算损失函数的梯度
- 5 梯度下降
- 6 训练模型
- 总结
前言
今天我们开始介绍逻辑回归的从零开始实现代码了,其中内容会包括普通实现、多项式特征实现非线性分类、正则化实现三个版本。相信看完底层实现你对逻辑回归的理解也会上升一个层次。
一、普通实现
1 数据集准备
在训练的初始阶段,我们将要构建一个逻辑回归模型来预测,某个学生是否被大学录取。设想你是大学相关部分的管理者,想通过申请学生两次测试的评分,来决定他们是否被录取。现在你拥有之前申请学生的可以用于训练逻辑回归的训练样本集。对于每一个训练样本,你有他们两次测试的评分和最后是被录取的结果。为了完成这个预测任务,我们准备构建一个可以基于两次测试评分来评估录取可能性的分类模型。
让我们从检查数据开始。
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltpath = 'ex2data1.txt'
data = pd.read_csv(path, header=None, names=['Exam 1', 'Exam 2', 'Admitted'])
data.head()
输出:
# 可视化一下该二分类数据
fig, ax = plt.subplots(1,1,figsize=(4,3))
ax.scatter(data[data['Admitted']==1]['Exam 1'], data[data['Admitted']==1]['Exam 2'], color = 'lightgreen', marker='o', label='Admitted')
ax.scatter(data[data['Admitted']==0]['Exam 1'], data[data['Admitted']==0]['Exam 2'], color = 'red', marker='x', label='Not Admitted')plt.xlabel('Exam 1 Score')
plt.ylabel('Exam 2 Score')
plt.legend(loc='upper right')
plt.grid(True)
plt.show()
输出:
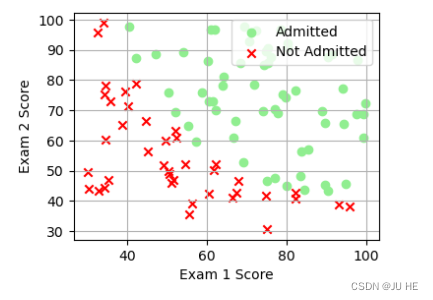
看起来在两类间,有一个清晰的决策边界。现在我们需要实现逻辑回归,那样就可以训练一个模型来预测结果。
# 数据准备
X_train = data.iloc[:,0:2].values # X_train是一个(m,n)的矩阵,m是样本数,n是特征数
y_train = data.iloc[:,2].values # y_train是一个(m,)的向量
print(f"X_train: {X_train}")
print(f"y_train: {y_train}")
输出:

2 逻辑回归模型
f w , b ( x ) = g ( w ⋅ x + b ) f_{\mathbf{w},b}(x) = g(\mathbf{w}\cdot \mathbf{x} + b) fw,b(x)=g(w⋅x+b)
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1
回忆逻辑回归模型,最外层是一个sigmoid函数,因此我们需要先实现sigmoid函数。
def sigmoid(z):return 1 / (1 + np.exp(-z))
# 可视化一下sigmoid函数
nums = np.arange(-10, 10, step=1)
fig, ax = plt.subplots(1,1,figsize=(4,3))
ax.plot(nums, sigmoid(nums), color='lightgreen')
plt.grid(True)
plt.show()
输出:
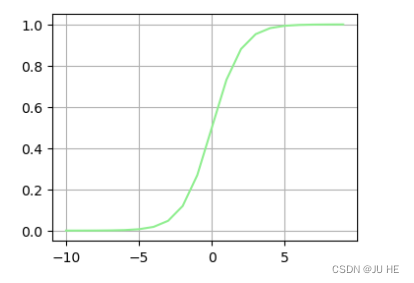
模型实现了,接下来我们需要实现损失函数,以及梯度下降算法。
3 损失函数
l o s s ( f w , b ( x ( i ) ) , y ( i ) ) = ( − y ( i ) log ( f w , b ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) (2) loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)}) = (-y^{(i)} \log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) - \left( 1 - y^{(i)}\right) \log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) \tag{2} loss(fw,b(x(i)),y(i))=(−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))(2)
-
f w , b ( x ( i ) ) f_{\mathbf{w},b}(\mathbf{x}^{(i)}) fw,b(x(i)) is the model’s prediction, while y ( i ) y^{(i)} y(i), which is the actual label
-
f w , b ( x ( i ) ) = g ( w ⋅ x ( i ) + b ) f_{\mathbf{w},b}(\mathbf{x}^{(i)}) = g(\mathbf{w} \cdot \mathbf{x^{(i)}} + b) fw,b(x(i))=g(w⋅x(i)+b) where function g g g is the sigmoid function.
- It might be helpful to first calculate an intermediate variable z w , b ( x ( i ) ) = w ⋅ x ( i ) + b = w 0 x 0 ( i ) + . . . + w n − 1 x n − 1 ( i ) + b z_{\mathbf{w},b}(\mathbf{x}^{(i)}) = \mathbf{w} \cdot \mathbf{x^{(i)}} + b = w_0x^{(i)}_0 + ... + w_{n-1}x^{(i)}_{n-1} + b zw,b(x(i))=w⋅x(i)+b=w0x0(i)+...+wn−1xn−1(i)+b where n n n is the number of features, before calculating f w , b ( x ( i ) ) = g ( z w , b ( x ( i ) ) ) f_{\mathbf{w},b}(\mathbf{x}^{(i)}) = g(z_{\mathbf{w},b}(\mathbf{x}^{(i)})) fw,b(x(i))=g(zw,b(x(i)))
*
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J\left( \theta \right)=\frac{1}{m}\sum\limits_{i=1}^{m}{[-{{y}^{(i)}}\log \left( {{h}_{\theta }}\left( {{x}^{(i)}} \right) \right)-\left( 1-{{y}^{(i)}} \right)\log \left( 1-{{h}_{\theta }}\left( {{x}^{(i)}} \right) \right)]} J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]
- It might be helpful to first calculate an intermediate variable z w , b ( x ( i ) ) = w ⋅ x ( i ) + b = w 0 x 0 ( i ) + . . . + w n − 1 x n − 1 ( i ) + b z_{\mathbf{w},b}(\mathbf{x}^{(i)}) = \mathbf{w} \cdot \mathbf{x^{(i)}} + b = w_0x^{(i)}_0 + ... + w_{n-1}x^{(i)}_{n-1} + b zw,b(x(i))=w⋅x(i)+b=w0x0(i)+...+wn−1xn−1(i)+b where n n n is the number of features, before calculating f w , b ( x ( i ) ) = g ( z w , b ( x ( i ) ) ) f_{\mathbf{w},b}(\mathbf{x}^{(i)}) = g(z_{\mathbf{w},b}(\mathbf{x}^{(i)})) fw,b(x(i))=g(zw,b(x(i)))
def compute_cost_logistic(X, y, w, b):<这篇关于机器学习算法(二):1 逻辑回归的从零实现(普通实现+多项式特征实现非线性分类+正则化实现三个版本)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


