本文主要是介绍开源AI聊天机器人应用程序模板; WrenAI用AI从数据中获取洞见;模拟多个代理人(agents)之间语言互动的仿真系统;语音数据集标注,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✨ 1: gemini-chatbot
使用Next.js构建的开源AI聊天机器人应用程序模板

Gemini-chatbot是一个使用Next.js构建的开源AI聊天机器人应用程序模板。它利用了Vercel AI SDK、Google Gemini以及Vercel KV来提供一个功能丰富、可定制的聊天体验。这个聊天机器人可以支持多种不同的AI模型和语言处理引擎,如Google Gemini(默认)、OpenAI、Anthropic、Cohere和Hugging Face,甚至可以自定义AI聊天模型和/或使用LangChain。这意味着你可以根据需要轻松切换不同的语言模型提供商。
地址:https://github.com/vercel-labs/gemini-chatbot
✨ 2: Agent Group Chat
模拟多个代理人(agents)之间语言互动的仿真系统
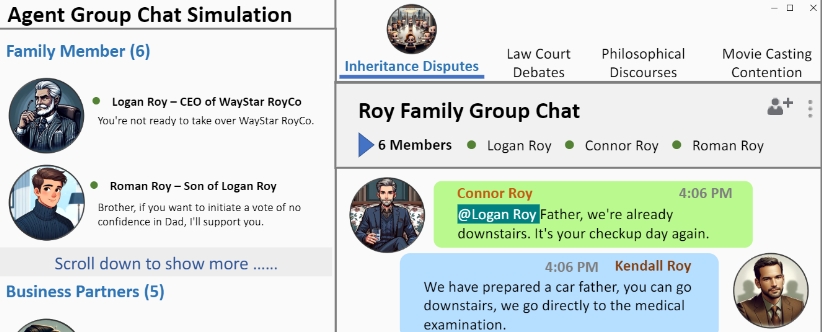
Agent Group Chat是一个模拟多个代理人(agents)之间语言互动的仿真系统,旨在研究语言在人类集体行为中的作用。通过设置不同角色和故事情节,例如遗产争执、法庭辩论、哲学论述和电影角色选角等,Agent Group Chat模拟代理人基于各自角色设定自由交谈的场景,观察代理人展现出预料之外且重要的集体突现行为(emergent behaviors)。该系统可以通过特定的环境设置评估代理人表现行为是否与人类期望相符合,并利用计算对话内容的n-gram Shannon熵来评估环境内的混乱程度。研究发现,在代理人与人类期望高度一致的前提下,促进更广泛的信息交换可确保仿真中多样性中的更大秩序性,从而促进更多意料之外且有意义的突现行为的出现。该项目的代码已开源,线上平台即将开放。
地址:https://github.com/MikeGu721/AgentGroup
✨ 3: WrenAI
革命性的AI数据助手,旨在通过简化与数据互动的方式,帮助个人和企业更快地获取结果和洞见
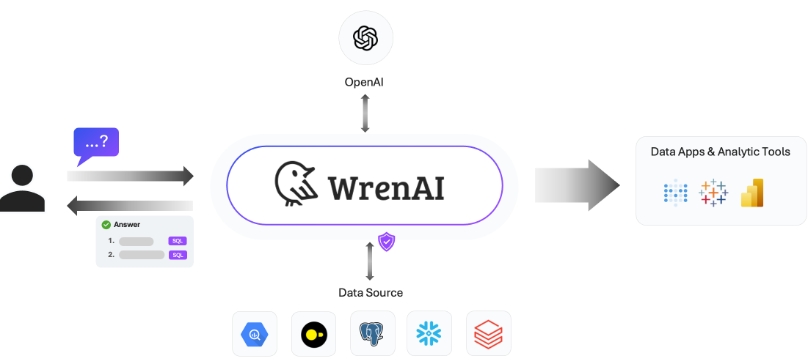
WrenAI是一个革命性的AI数据助手,旨在通过简化与数据互动的方式,帮助个人和企业更快地获取结果和洞见。这是通过让用户能够不需要编写SQL就能提问和获取数据分析结果完成的。
WrenAI是一个强大的工具,它通过人工智能和大型语言模型技术改变了我们与数据之间的互动方式。它不仅使得从数据中获取洞见变得更加简单和快速,而且通过持续学习和适应,保证了结果的准确性和相关性。无论是数据分析师、企业用户还是技术专家,WrenAI都提供了一种无缝、直观且高度安全的方式来利用他们的数据。如果你正在寻找一个能够快速获取数据洞察、增强业务决策支持且不 compromisecurity 的解决方案,WrenAI可能正是你需要的。
地址:https://github.com/Canner/WrenAI
✨ 4: LightLLM
基于Python的大型语言模型(LLM)推理和服务框架
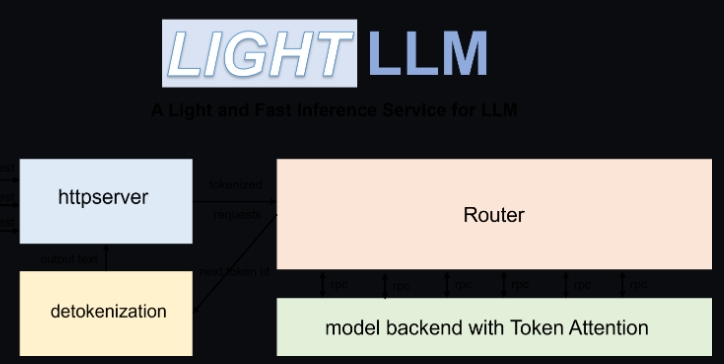
LightLLM是一个基于Python的大型语言模型(LLM)推理和服务框架,以其轻量级设计、易于扩展和高速性能而著称。它聚合了多个广受好评的开源实现的优点,包括但不限于FasterTransformer、TGI、vLLM和FlashAttention等。
地址:https://github.com/ModelTC/lightllm
✨ 5: Data-Speech
为语音数据集标记标签的实用程序脚本集合
Data-Speech是一套旨在为语音数据集标记标签的实用程序脚本集合。它的主要目的是为了提供一个简单、干净的代码库,用于应用音频转换(或标注),这些转换或标注可能是作为开发基于语音的AI模型(如文本到语音引擎)的一部分被请求的。
地址:https://github.com/huggingface/dataspeech
更多AI工具,参考国内AiBard123,Github-AiBard123
这篇关于开源AI聊天机器人应用程序模板; WrenAI用AI从数据中获取洞见;模拟多个代理人(agents)之间语言互动的仿真系统;语音数据集标注的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








