本文主要是介绍一篇文章看懂Homogeneous Graph与Heterogeneous Graph,以及如何通过DGL定义数据与模型 进行Batch训练,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Homogeneous Graph与Heterogeneous Graph
- 提供图训练的小知识
- Homogeneous Graph与Heterogeneous Graph的区别
- 在DGL(Deep Graph Library) 定义 同构图
- 在DGL(Deep Graph Library) 定义 异构图
提供图训练的小知识
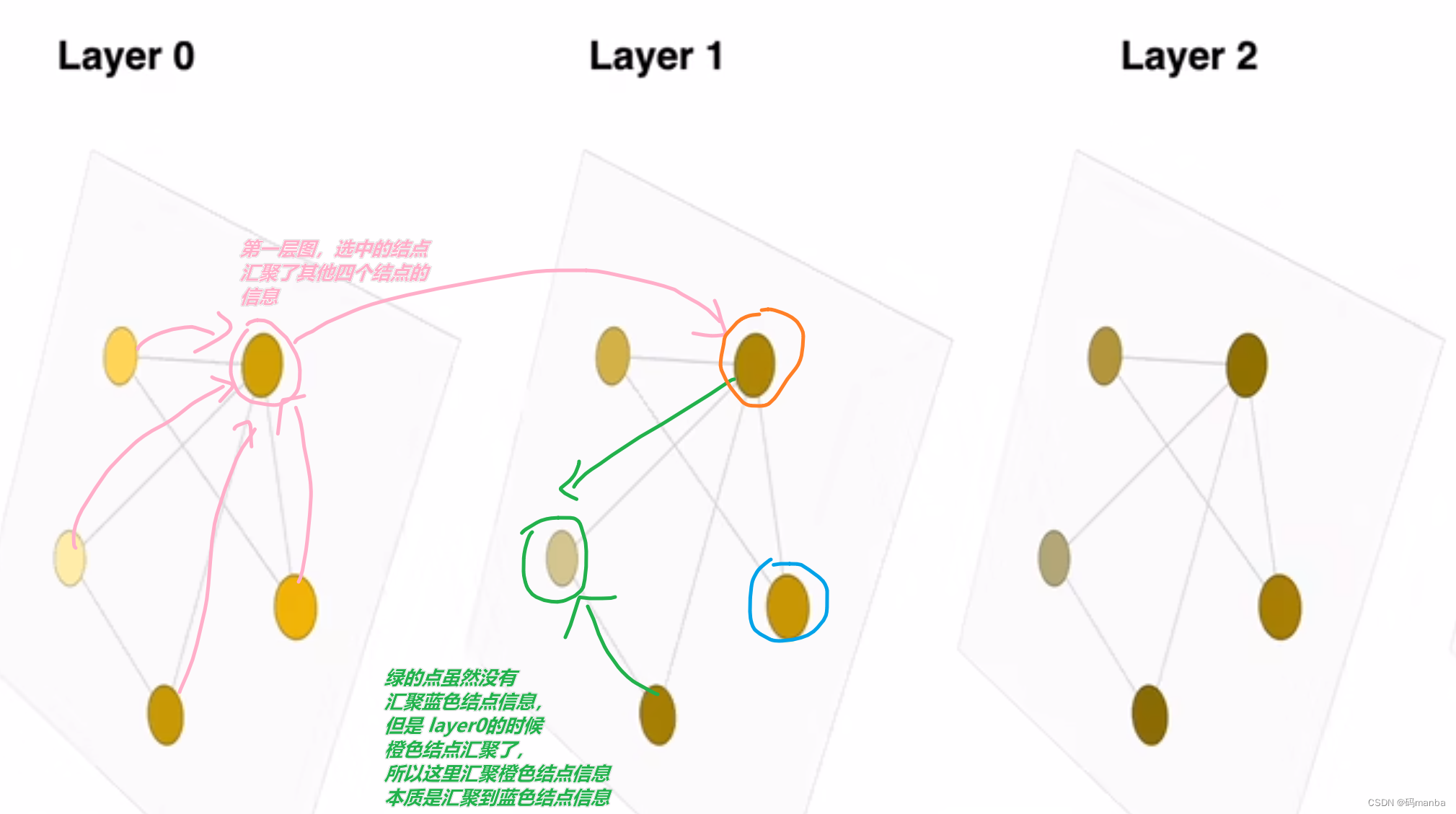
在一张图进行训练时, 可能由于层数的增加,使得结点可以充分汇聚到其他结点的信息。
layer0: 直接连接的信息被汇聚。
layer1: 间接连接的结点被汇聚。
layer2: …
Homogeneous Graph与Heterogeneous Graph的区别
- Homogeneous Graph(同构图)
同构图是指所有节点和边都是同质的,即节点之间的连接方式相同,边的类型相同。在同构图中,所有节点和边都属于同一种类型。例如,社交网络中的好友关系图就是一个同构图,其中所有节点都代表用户,边代表用户之间的好友关系。
在 DGL 中,使用 dgl.graph() 函数可以创建同构图。同构图的创建可以直接从节点和边的张量数据中构建,所有的节点和边都具有相同的类型。
- Heterogeneous Graph(异构图)
异构图是指节点和边可以有不同的类型,节点之间的连接方式和边的类型可以不同。在异构图中,节点和边可以代表不同的实体或关系,具有多样性。例如,电子商务网站中的商品-用户-类别三元关系图就是一个异构图,其中节点分为商品、用户和类别三种类型,边代表商品与用户之间的购买关系以及商品与类别之间的归属关系。
在 DGL 中,使用 dgl.heterograph() 函数可以创建异构图。异构图的创建需要指定不同类型的节点和边,以及它们之间的连接关系。
在DGL(Deep Graph Library) 定义 同构图
- 初始化图数据
初始化数据
import dgl
import torch# 初始化图列表
graph_list = []# 构建每组对话的图
for _ in range(batchsize):# 假设每组对话有5个句子num_sentences = 5sentence_features = torch.randn(num_sentences, 768) # 句子级特征# 添加句子级节点g.add_nodes(num_sentences, {'sentence_feat': sentence_features})g.add_edges([xxxx], [xxxx]) # 添加结点 ([起始结点],[终端结点])# 将图添加到图列表中graph_list.append(g)# 批次化图
batched_graph = dgl.batch(graph_list)- 定义同构图GCN
import dgl
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader# 定义一个简单的GCN模型
class GCN(nn.Module):def __init__(self, in_feats, hidden_size, out_feats):super(GCN, self).__init__()self.conv1 = dgl.nn.GraphConv(in_feats, hidden_size)self.conv2 = dgl.nn.GraphConv(hidden_size, out_feats)def forward(self, g, features):x = torch.relu(self.conv1(g, features))x = self.conv2(g, x)return x
在DGL(Deep Graph Library) 定义 异构图
- 初始化图数据
初始化数据
import dgl
import torch# 初始化一个空的异构图列表
hetero_graph_list = []# 遍历每组对话数据,构建异构图
for _ in range(batchsize):# 初始化一个异构图对象 ([xxx], [xxx] 表示 起始结点)g = dgl.heterograph({('结点类型1', '关系', '结点类型2'): ([xxx], [xxx]),('结点类型1', '关系', '结点类型3'): ([xxx], [xxx]),('结点类型2', '关系', '结点类型3'): ([xxx], [xxx]),})# 添加节点特征g.nodes['结点类型1'].data['feat'] = 结点类型1特征g.nodes['结点类型2'].data['feat'] = 结点类型2特征g.nodes['结点类型3'].data['feat'] = 结点类型3特征# 将图对象添加到异构图列表中hetero_graph_list.append(g)# 使用 dgl.batch_hetero() 函数将异构图列表批次化
batched_hetero_graph = dgl.batch_hetero(hetero_graph_list)
- 定义异构图网络结构
import dgl
import torch
import torch.nn as nn
import torch.nn.functional as Fclass HeteroGCN(nn.Module):def __init__(self, in_feats, hidden_feats, out_feats):super(HeteroGCN, self).__init__()# 定义每种节点类型的图卷积层self.conv1 = dgl.nn.HeteroGraphConv({'结点类型1': dgl.nn.GraphConv(in_feats['结点类型1'], hidden_feats),'结点类型2': dgl.nn.GraphConv(in_feats['结点类型2'], hidden_feats),'结点类型3': dgl.nn.GraphConv(in_feats['结点类型3'], hidden_feats)})self.conv2 = dgl.nn.HeteroGraphConv({'结点类型1': dgl.nn.GraphConv(hidden_feats, out_feats),'结点类型2': dgl.nn.GraphConv(hidden_feats, out_feats),'结点类型3': dgl.nn.GraphConv(hidden_feats, out_feats)})def forward(self, g, node_features):# 执行第一层异构图卷积h = self.conv1(g, node_features)# 应用激活函数h = {k: F.relu(h[k]) for k in h.keys()}# 执行第二层异构图卷积h = self.conv2(g, h)return h这篇关于一篇文章看懂Homogeneous Graph与Heterogeneous Graph,以及如何通过DGL定义数据与模型 进行Batch训练的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




