本文主要是介绍计算机视觉——引导APSF和梯度自适应卷积增强夜间雾霾图像的可见性算法与模型部署(C++/python),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
在夜间雾霾场景中,可见性经常受到低光照、强烈光晕、光散射以及多色光源等多种因素的影响而降低。现有的夜间除雾方法常常难以处理光晕或低光照条件,导致视觉效果过暗或光晕效应无法被有效抑制。本文通过抑制光晕和增强低光区域来提升单张夜间雾霾图像的可见性。为了处理光晕效应,提出了一个光源感知网络来检测夜间图像的光源,并采用APSF(大气点扩散函数)引导的光晕渲染。该算法的框架在渲染图像上进行训练,实现了光晕的抑制。此外,还利用梯度自适应卷积来捕捉雾霾场景中的边缘和纹理。通过提取的边缘和纹理,在不丢失重要结构细节的情况下增强了场景的对比度。为了提升低光强度,算法的网络学习了一个注意力图,然后通过伽马校正进行调整。这个注意力图在低光区域有较高的值,在雾霾和光晕区域有较低的值。通过在真实的夜间雾霾图像上进行广泛的评估,算法的方法证明了其有效性。算法的实验表明,算法的方法在GTA5夜间雾霾数据集上达到了30.38dB的PSNR,比最先进的方法提高了13%。

论文地址:https://arxiv.org/pdf/2308.01738.pdf
源码地址:https://github.com/jinyeying/nighttime_dehaze
推理代码:https://download.csdn.net/download/matt45m/89110270
1. 论文贡献
夜间雾霾或雾图像通常遭受可见性降低的问题。除了夜间图像常见的问题,如低光、噪声、不均匀的光分布和多种光颜色外,夜间雾霾或雾图像还表现出强烈的光晕和颗粒遮蔽效应。尽管存在这些挑战,解决这些问题对于许多应用来说是至关重要的。这些应用包括自动驾驶汽车、自主无人机和监控等,因为夜间雾霾是自然现象,频繁且不可避免。日间雾霾去除方法无法处理夜间雾霾所独有的挑战。传统的非学习型日间除雾方法依赖于雾霾成像模型,但这个模型在夜间不适用,因为存在人造光源和照明颜色的复杂性。因此,与日间不同,算法不能假设大气光颜色是均匀的。此外,这个日间雾霾模型没有考虑到光晕的视觉表现。现有的夜间除雾方法产生了不令人满意的暗视觉或未缓解的光晕效应。非深度学习方法引入了对光晕的某些约束,但它们由于光晕和背景层的不精确分解或使用暗通道先验进行除雾,导致结果暗淡。基于学习的方法面临的主要挑战是缺乏真实世界的成对训练数据,因为获取包含光晕和多光源的夜间雾霾场景的清晰真实图像是不切实际的。算法的方法通过抑制光晕和增强低光区域来增强单张夜间雾霾图像的可见性。算法的光晕抑制包括两个主要部分:APSF引导的光晕渲染和梯度自适应卷积。算法的光晕渲染方法使用APSF引导的方法为各种光源创建光晕效应。算法采用光源感知网络来检测图像中光源的位置,然后对这些光源应用APSF引导的光晕渲染。算法的框架从渲染的图像中学习,因此可以抑制不同光源中的光晕效应。算法的梯度自适应卷积从雾霾图像中捕捉边缘和纹理。具体来说,通过计算相邻像素之间的像素差异来获取边缘,同时使用双边核来提取图像的纹理。边缘和纹理然后被输入到算法的框架中以增强图像细节。为了增强非光源区域的可见性,算法引入了一个新颖的注意力引导增强模块。雾霾区域的权重较低,而暗区域的权重较高。总体而言,算法的贡献可以总结如下:
- 据算法所知,算法的方法是基于学习的网络,首次一站式处理夜间光晕和低光条件。
- 算法提出了一个光源感知网络和APSF引导的光晕渲染,以模拟来自不同光源的光晕效应。通过从APSF引导的光晕渲染数据中学习,算法的框架有效地抑制了真实世界雾霾图像中的光晕效应。
- 由于夜间图像对比度较低,算法采用梯度自适应卷积进行边缘增强和双边核进行纹理增强。
2. 相关工作
早期的除雾方法利用多张图像或先验来估计大气光和传输。随着深度学习的出现,提出了许多网络来估计传输图或端到端输出清晰图像。最近,已经开发了全监督、半监督、零样本和无监督方法。然而,这些方法在夜间雾霾方面遇到了困难,因为它们面临非均匀、多色的人造光和缺乏干净的地面真实数据用于训练。基于优化的夜间除雾方法遵循大气散射模型、新的成像模型等。Pei和Lee将雾霾夜间图像的空气光颜色转移到日间,并使用DCP进行除雾。Ancuti等人引入了一种基于融合的方法和拉普拉斯金字塔分解来估计局部空气光。Zhang等人使用照明补偿、颜色校正和DCP进行除雾。Zhang等人提出了最大反射率先验(MRP)。Tang等人使用Retinex理论和泰勒级数展开。Liu等人使用正则化约束。Wang等人提出了灰色雾霾线先验和变分模型。现有的夜间除雾方法依赖于基于局部补丁的大气光估计,假设小补丁内的均匀性。因此,它们的性能对补丁大小敏感。这些方法在优化方面不自适应且耗时。与它们不同,算法的方法是基于学习的,更高效、实用和快速。最近,提出了基于学习的夜间除雾方法。Zhang等人通过使用合成的夜间雾霾图像进行全监督学习来训练网络。然而,这种方法无法有效抑制光晕,因为合成数据集没有考虑到光晕效应。Yan等人提出了一种半监督方法,使用高低频分解和灰度网络。然而,他们的结果往往较暗,丢失了细节。这是因为基于粗略频率的分解方法难以有效分离光晕,导致场景的亮度和可见性降低。DeGlow-DeHaze网络估计传输,然后是DehazeNet。然而,由DeHaze网络估计的大气光是从最亮的区域获得的,并被假定为全局均匀的,这在夜间是无效的。与它们相比,算法的结果可以抑制光晕,同时增强低光区域。点光源的光晕,称为大气点扩散函数(APSF),已经在各种工作中进行了研究。Narasimhan和Nayar首先引入APSF,并为多次散射光开发了一个基于物理的模型。Metari等人对APSF核进行了建模。Li等人使用层分离方法从输入图像中分解光晕,通过其平滑属性约束光晕,并使用DCP进行除雾。Park等人和Yang等人遵循夜间雾霾模型,并使用加权熵和超像素来估计大气光和传输图。然而,这些方法在去除光晕后,简单地将日间除雾应用于夜间除雾,导致他们的成果在可见性和颜色上存在失真。以前的工作主要集中在基于优化的方法上,而算法的作品是第一个将APSF先验纳入夜间学习网络的。
3. 提出的方法
图2展示了算法的流程,包括光晕抑制和低光增强。算法的光晕抑制有两个部分:deglowing网络和glow生成器。算法的deglowing网络将真实的雾霾图像转换为清晰的图像。算法使用一个鉴别器来判断生成的清晰图像和参考图像是真实的还是伪造的。算法的创新点在于这三个想法:APSF引导的光晕渲染、梯度自适应卷积和注意力引导增强。
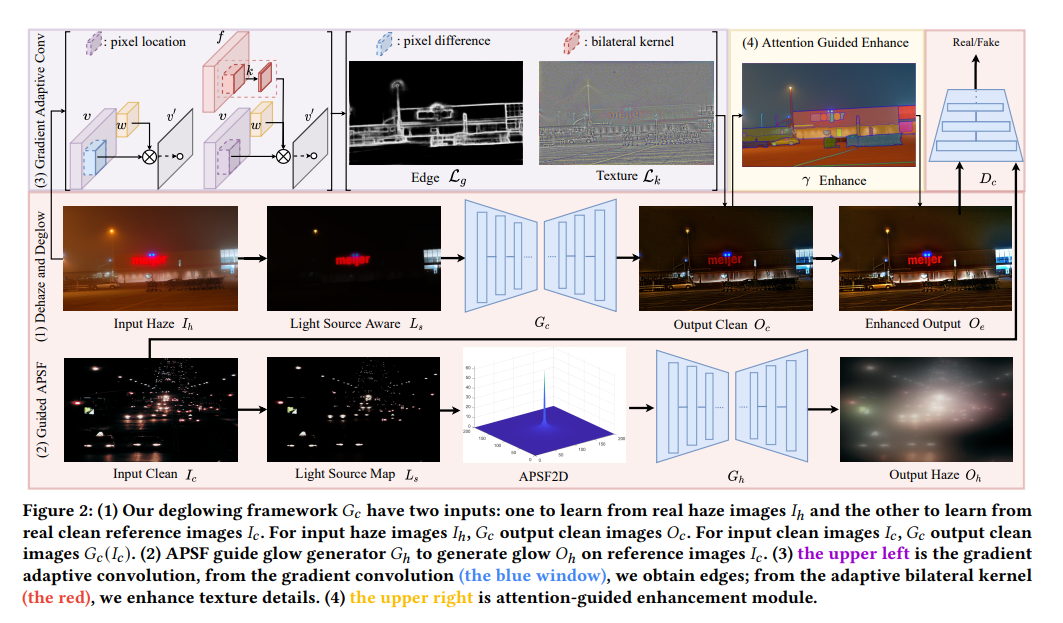
3.1. 光源感知网络
夜间场景经常包含活动光源,如路灯、车头灯和建筑灯光。这些光源可以在雾霾夜间场景中造成强烈的光晕。夜间场景中的雾霾和光晕的出现可以建模为:

3.2 APSF引导的夜间光晕渲染
在获得光源图后,算法提出了一种基于APSF的方法来渲染夜间光晕效果。首先,算法计算APSF函数,并将其转换为2D格式,这使算法能够在光源图上执行2D卷积,从而产生光晕图像。然后,算法结合清晰和光晕图像来渲染最终图像中的逼真光晕效果。

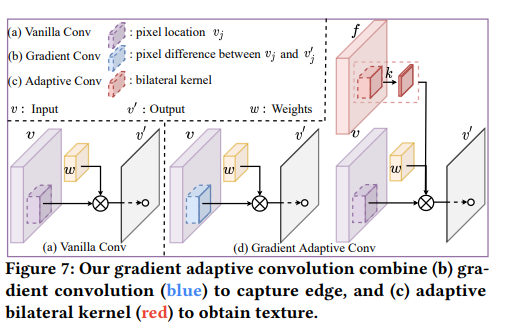
3.3. 梯度自适应卷积
夜间雾霾图像通常对比度较低,缺失纹理,照明不均匀。普通的2D卷积可能不足以增强夜间雾霾图像。因此,算法使用梯度自适应卷积来捕捉雾霾图像中的边缘和纹理。

3.4. 网络和其他损失
算法的光晕抑制是基于CycleGAN网络。算法使用deglowing网络,它与鉴别器耦合。为了确保重建一致性,算法有另一个雾霾生成器与它的鉴别器耦合。算法的雾霾生成器将输出图像转换为重构的清晰图像。通过施加循环一致性约束,算法的deglowing网络学习去除真实世界的光晕。由于循环一致性约束,算法被允许使用未配对的数据来优化算法的deglowing网络,从而减少合成数据集和真实世界光晕图像之间的领域差距。除了自监督的光源一致性损失、梯度损失和双边核损失外,算法按照[102]的方法,使用其他损失来训练算法的网络。它们是对抗损失、循环一致性损失、身份损失,权重分别为{1, 10, 10}。
3.5. 低光区域增强
夜间除雾经常导致暗结果,这是由于低光条件造成的。为了解决这个问题,算法引入了一个低光增强模块来提高对象区域的可见性。算法的方法包括生成一个注意力图,突出这些区域,使算法的方法专注于增强它们的强度。然后,算法应用一个低光图像增强技术来增强区域,即使在场景光照较低的情况下。

4. 实验结果
4.1. 数据集
GTA5是一个由GTA5游戏引擎生成的合成夜间雾霾数据集。它包括864对配对图像,其中787对图像用作训练集,其余图像用作测试集。RealNightHaze是一个真实世界的夜间除雾数据集。它包括440张夜间雾霾图像,其中150张图像来自[98],200张图像来自[87],其余图像从互联网收集。
4.2. 在合成数据集上的比较
在本节中,将方法与现有的最先进方法进行比较,包括Yan [87]、Zhang [97]、Li [45]、Ancuti [1]、Zhang [96]、Yu [94]、Zhang [98]、Liu [51]和Wang [77]。主要区别的总结如表2所示。实验结果如表1所示。可以看出,该算法的方法实现了显著的性能提升。采用两个广泛使用的指标PSNR和SSIM。算法的方法达到了30.38dB的PSNR和0.904的SSIM,比Yan的方法[87]分别提高了14%和5%。

4.3. 在真实世界数据集上的比较
下图显示了不同夜间除雾方法在真实夜间雾霾场景上的定性结果。该算法显著增强了夜间雾霾图像的可见性。具体来说,大多数最先进的方法无法充分去除雾霾,因为它们的方法受到合成数据集和真实世界图像之间领域差距的影响。Yan等人提出了一种半监督框架来去除夜间雾效,可以去除大部分雾霾效果。然而,他们的方法过度抑制了雾霾图像,因此他们的输出结果变得太暗。相比之下,该算法处理了光晕和低光条件。如图9(b)所示,该算法不仅去除了输入图像的雾霾,还增强了光线。例如,树木和建筑物的细节是清晰的。这是因为该算法通过利用APSF来模拟光晕渲染,因此可以有效去除真实世界夜间雾霾图像中的雾霾或光晕。此外,该算法提出了一个梯度自适应卷积来捕捉雾霾图像中的边缘和纹理。捕获的边缘和纹理然后被用来增强图像的细节,从而实现更好的性能。此外,该算法引入了一个注意力图来增强低光区域。因此,该算法的方法实现了显著的性能提升。该算法还对真实世界的夜间雾霾图像进行了用户研究。实验结果如表3所示。可以看出,该算法的方法在所有方面都获得了最高分。

4.4. 消融研究
该算法的框架包括三个核心部分:APSF引导的光晕渲染、梯度自适应卷积和注意力引导增强。为了证明每个部分的有效性,该算法在真实世界的夜间雾霾图像上进行了消融研究。APSF引导的光晕渲染如图5(底部)所示,该算法可以看到该算法的方法可以准确地检测到光源的位置(中间)。此外,渲染结果有效地模拟了光晕效果。梯度自适应卷积如图6所示,显示了梯度边缘图(中间)和纹理(底部)的结果。图11(b)和(c)显示了没有梯度损失L𝐴?和没有核损失L𝐴?的结果,(d)是带有梯度捕获卷积的。该算法可以看到该算法的梯度捕获卷积可以有效地保留雾霾图像的结构细节。通过充分利用梯度图和纹理,该算法的框架生成了更清晰的结果。低光增强如图10所示,显示了从(b)到(d)的低光增强结果。
5.模型部署
官方提供了预训练的模型,可以拿官方的模型转onnx之后用onnxruntime进行推理,这里使用的onnxruntime版本是1.15 。
C++代码推理:
#include "NighttimeDehaze.h"NighttimeDehaze::NighttimeDehaze(string model_path)
{std::wstring widestr = std::wstring(model_path.begin(), model_path.end()); windows写法///OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0); ///如果使用cuda加速,需要取消注释sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);ort_session = new Session(env, widestr.c_str(), sessionOptions); windows写法ort_session = new Session(env, model_path.c_str(), sessionOptions); linux写法size_t numInputNodes = ort_session->GetInputCount();size_t numOutputNodes = ort_session->GetOutputCount();AllocatorWithDefaultOptions allocator;for (int i = 0; i < numInputNodes; i++){input_names.push_back(ort_session->GetInputName(i, allocator));Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();auto input_dims = input_tensor_info.GetShape();input_node_dims.push_back(input_dims);}for (int i = 0; i < numOutputNodes; i++){output_names.push_back(ort_session->GetOutputName(i, allocator));Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();auto output_dims = output_tensor_info.GetShape();output_node_dims.push_back(output_dims);}this->inpHeight = input_node_dims[0][2]; /// n, h, w, cthis->inpWidth = input_node_dims[0][3];
}void NighttimeDehaze::preprocess(Mat img)
{Mat rgbimg;cvtColor(img, rgbimg, COLOR_BGR2RGB);resize(rgbimg, rgbimg, cv::Size(this->inpWidth, this->inpHeight));vector<cv::Mat> rgbChannels(3);split(rgbimg, rgbChannels);for (int c = 0; c < 3; c++){rgbChannels[c].convertTo(rgbChannels[c], CV_32FC1, 1.0 / (255.0 * 0.5), -1.0);}const int image_area = this->inpHeight * this->inpWidth;this->input_image.resize(3 * image_area);size_t single_chn_size = image_area * sizeof(float);memcpy(this->input_image.data(), (float*)rgbChannels[0].data, single_chn_size);memcpy(this->input_image.data() + image_area, (float*)rgbChannels[1].data, single_chn_size);memcpy(this->input_image.data() + image_area * 2, (float*)rgbChannels[2].data, single_chn_size);
}Mat NighttimeDehaze::predict(Mat srcimg)
{const int srch = srcimg.rows;const int srcw = srcimg.cols;this->preprocess(srcimg);std::vector<int64_t> input_img_shape = { 1, 3, this->inpHeight, this->inpWidth };Value input_tensor_ = Value::CreateTensor<float>(memory_info_handler, this->input_image.data(), this->input_image.size(), input_img_shape.data(), input_img_shape.size());Ort::RunOptions runOptions;vector<Value> ort_outputs = this->ort_session->Run(runOptions, this->input_names.data(), &input_tensor_, 1, this->output_names.data(), output_names.size());/nighttime_dehaze_realnight_Nx3xHxW.onnx和nighttime_dehaze_realnight_1x3xHxW.onnx在run函数这里会出错float* pdata = ort_outputs[0].GetTensorMutableData<float>();std::vector<int64_t> outs_shape = ort_outputs[0].GetTensorTypeAndShapeInfo().GetShape();const int out_h = outs_shape[2];const int out_w = outs_shape[3];const int channel_step = out_h * out_w;Mat rmat(out_h, out_w, CV_32FC1, pdata);Mat gmat(out_h, out_w, CV_32FC1, pdata + channel_step);Mat bmat(out_h, out_w, CV_32FC1, pdata + 2 * channel_step);vector<Mat> channel_mats(3);channel_mats[0] = bmat;channel_mats[1] = gmat;channel_mats[2] = rmat;Mat dstimg;merge(channel_mats, dstimg);resize(dstimg, dstimg, cv::Size(srcw, srch));dstimg.convertTo(dstimg, CV_8UC3);return dstimg;
}python部署:
import argparse
import cv2
import onnxruntime
import numpy as npclass nighttime_dehaze:def __init__(self, modelpath):# Initialize modelself.onnx_session = onnxruntime.InferenceSession(modelpath)self.input_name = self.onnx_session.get_inputs()[0].name_, _, self.input_height, self.input_width = self.onnx_session.get_inputs()[0].shapedef detect(self, image):input_image = cv2.resize(cv2.cvtColor(image, cv2.COLOR_BGR2RGB), dsize=(self.input_width, self.input_height))input_image = (input_image.astype(np.float32) / 255.0 - 0.5) / 0.5input_image = input_image.transpose(2, 0, 1)input_image = np.expand_dims(input_image, axis=0)result = self.onnx_session.run(None, {self.input_name: input_image})###nighttime_dehaze_realnight_Nx3xHxW.onnx和nighttime_dehaze_realnight_1x3xHxW.onnx在run函数这里会出错# Post process:squeeze, RGB->BGR, Transpose, uint8 castoutput_image = np.squeeze(result[0])output_image = output_image.transpose(1, 2, 0)output_image = cv2.resize(output_image, (image.shape[1], image.shape[0]))output_image = cv2.cvtColor(output_image.astype(np.uint8), cv2.COLOR_RGB2BGR)return output_imageif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--imgpath', type=str,default='n1.jpg', help="image path")parser.add_argument('--modelpath', type=str,default='models/nighttime_dehaze_720x1280.onnx', help="onnx path")args = parser.parse_args()mynet = nighttime_dehaze(args.modelpath)srcimg = cv2.imread(args.imgpath)dstimg = mynet.detect(srcimg)if srcimg.shape[0] > srcimg.shape[1]:boundimg = np.zeros((10, srcimg.shape[1], 3), dtype=srcimg.dtype)+255 ###中间分开原图和结果combined_img = np.vstack([srcimg, boundimg, dstimg])else:boundimg = np.zeros((srcimg.shape[0], 10, 3), dtype=srcimg.dtype)+255combined_img = np.hstack([srcimg, boundimg, dstimg])winName = 'Deep Learning in onnxruntime'cv2.namedWindow(winName, 0)cv2.imshow(winName, combined_img) ###原图和结果图也可以分开窗口显示cv2.waitKey(0)cv2.destroyAllWindows()

6. 结论
在本文中,该算法提出了一种新颖的夜间可见性增强框架,同时解决了光晕和低光条件问题。该算法的框架包括三个核心思想:APSF引导的光晕渲染、梯度自适应卷积和注意力引导的低光增强。该算法的框架通过从APSF引导的光晕渲染数据中学习来抑制光晕效应。由于该算法的APSF引导的光晕渲染,该算法允许使用半监督方法来优化该算法的网络,从而处理不同光源中的光晕效应。该算法提出的梯度自适应卷积用于从夜间雾霾图像中捕捉边缘或纹理。得益于捕获的边缘或纹理,该算法的框架有效地保留了结构细节。该算法的低光区域增强通过注意力图提高了暗或过度抑制区域的强度。定量和定性实验表明,该算法的方法实现了显著的性能提升。此外,消融研究证明了每个核心思想的有效性。处理具有多样化领域偏移的场景[99]将成为该算法未来研究的焦点。
这篇关于计算机视觉——引导APSF和梯度自适应卷积增强夜间雾霾图像的可见性算法与模型部署(C++/python)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







