本文主要是介绍深度学习特征提取新突破!42个涨点方案,让模型性能、效率倍增,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为数据预处理的一个重要步骤,特征提取是CV领域一个复杂但不可或缺的过程。它通过某种变换或映射,从原始数据中提取出对目标任务更有帮助的信息,以提高模型性能、降低计算成本、提升数据可解释性和模型泛化能力。
目前,特征提取主要有2大类主流方法:基于检测器的方法、无检测器的方法。基于检测器的方法依赖于手工设计的特征或者通过训练得到的深度神经网络来提取特征点,而无检测器的方法则直接从数据中提取特征,两者各有优势。
在实际应用中,选择合适的特征提取方法对后续模型的性能提升至关重要。本文介绍这2大类主流特征提取方法,并细分了7个具体方向,每种方法都附有代表论文以及相应代码(共42篇),方便同学们pick合适的方法,高效涨点。
论文原文以及代码需要的同学看文末
基于检测器的方法
这类方法通常包括以下几个关键步骤:首先,使用检测器在图像中定位到可能的特征点或区域;然后,对这些特征点或区域进行描述,生成特征向量;最后,利用这些特征向量进行后续的任务,如分类、识别等。这类方法的典型代表包括SIFT、SURF和ORB等算法。
1.先检测后描述
ZippyPoint: Fast Interest Point Detection, Description, and Matching through Mixed Precision Discretization
方法:研究的重点是网络量化技术和二进制描述符规范化层的应用,以加快推理速度并在计算能力有限的平台上使用。通过提出的ZippyPoint网络,研究成功地提高了网络运行速度、描述符匹配速度和3D模型大小,从而实现了至少一个数量级的改进。

创新点:
-
基于深度学习的轻量级二进制描述符:作者提出了ZippyPoint,这是一个通过网络量化和二进制描述符实现高效检测和描述的方法。相比传统的手工算法,ZippyPoint在计算资源有限的平台上实现了至少一个数量级的提速,并且在性能上与全精度模型相媲美。
-
二进制描述符的标准化层:为了优化二进制描述符的性能,作者引入了二进制标准化(Bin.Norm)层,将描述符限制为具有恒定数量的1。通过使用Bin.Norm层,ZippyPoint在功能性能上显著改善,并且优于其他二进制描述符方法,如ORB和BRISK。

2.联合检测与描述
SFD2: Semantic-guided Feature Detection and Description
方法:论文提出了一种将高级语义信息隐式嵌入到特征检测和描述的过程中的方法,使模型能够在测试时直接从单一网络提取具有全局可靠性的特征。具体地说,在训练过程中,作者使用现成的语义分割网络的输出作为指导,并采用了语义感知和特征感知的结合策略来增强嵌入语义信息的能力。
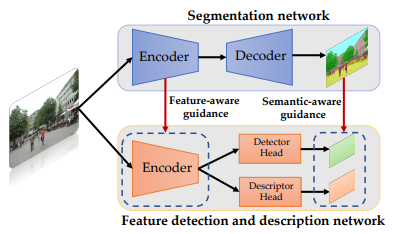
创新点:
-
隐式嵌入高级语义信息:通过在特征检测和描述过程中隐式嵌入语义信息,使模型能够从单个网络中端到端地提取全局可靠的特征。
-
与先进的匹配器相媲美的性能和更高的效率:本文方法通过将高级语义信息隐式地嵌入到局部特征中,既提高了特征检测和描述的准确性,又避免了使用昂贵的匹配方法。因此,本文方法在精度和效率之间取得了良好的平衡,尤其适用于计算资源有限的设备。
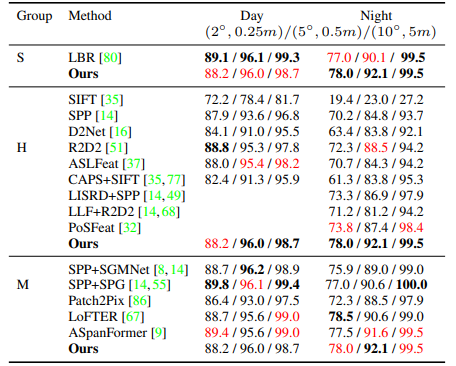
3.描述后检测
Shared Coupling-bridge for Weakly Supervised Local Feature Learning
方法:本文提出了一种增强的弱监督局部特征学习架构SCFeat。在局部特征学习方面,本文引入了F2R-Backbone用于局部描述符的学习。为了提高局部特征学习的效率,本文设计了共享耦合桥归一化方案,用于描述网络和检测网络的解耦训练。此外,本文还设计了一个增强的检测网络,通过峰值测量实现更准确的关键点定位。同时,本文采用基础矩阵误差作为新的奖励因子,以增强特征检测训练。
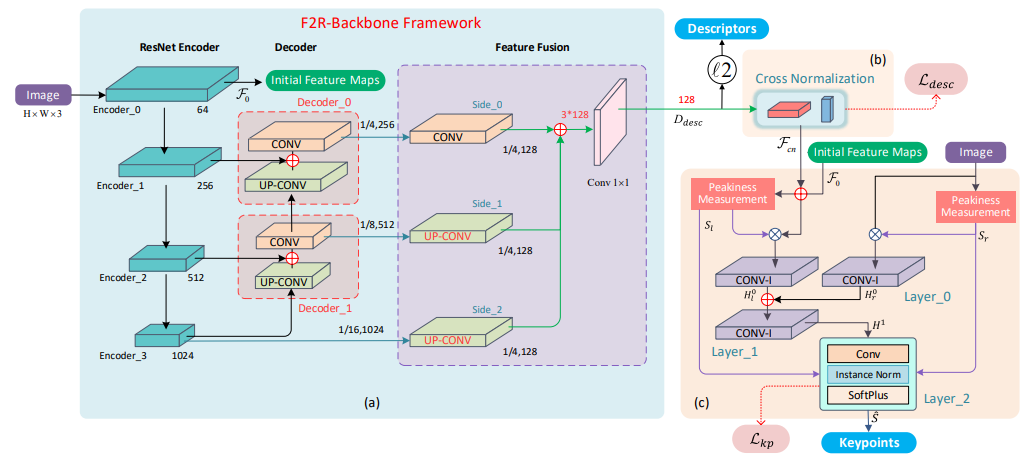
创新点:
-
SCFeat提出了一个F2R-Backbone用于局部描述符学习,通过增加描述网络和检测网络之间的共享耦合桥归一化来提高描述网络和检测网络的训练效率。
-
SCFeat使用峰值度量来衡量候选关键点的可靠性,综合考虑空间和通道响应。
-
SCFeat在图像匹配、视觉定位和三维重建任务中取得了优越的性能,超过了其他基线方法。
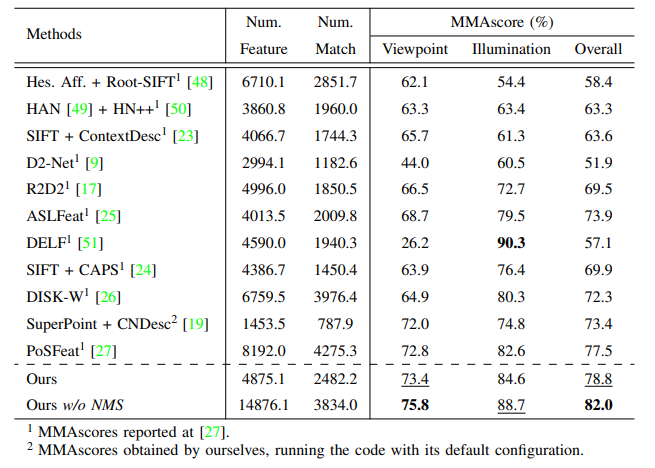
4.基于图的方法
Learning Feature Matching via Matchable Keypoint-Assisted Graph Neural Network
方法:论文提出一种名为MaKeGNN的图神经网络,用于学习特征匹配。通过引入BCAS模块和MKACA模块,MaKeGNN能够以紧凑而稳健的注意力模式聚合上下文信息。

创新点:
-
MaKeGNN方法引入了BCAS模块和MKACA模块,实现了紧凑而强大的信息传递,从而在特征匹配任务中取得了最先进的性能,同时显著降低了计算和内存复杂度。
-
MaKeGNN方法通过动态采样两组具有高匹配性分数的均匀分布的关键点,引导网络进行紧凑而有意义的信息传递,避免了与非可重复关键点的冗余连接和干扰,从而提高了特征匹配的准确性和效率。
-
MaKeGNN方法在相对相机估计、基础矩阵估计和视觉定位等任务上取得了最先进的性能,同时在计算和内存复杂度方面显著降低,具有很高的实用价值和应用前景。

无检测器的方法
这类方法不依赖于显式的特征点或区域检测步骤,通常直接对图像进行全局或局部的分析,通过深度学习模型等工具自动学习并提取特征。比如CNN就是一种典型的无检测器特征提取方法。此外还有一些基于CNN的改进算法,如Fast R-CNN、Faster R-CNN和YOLO等。
1.基于CNN的方法
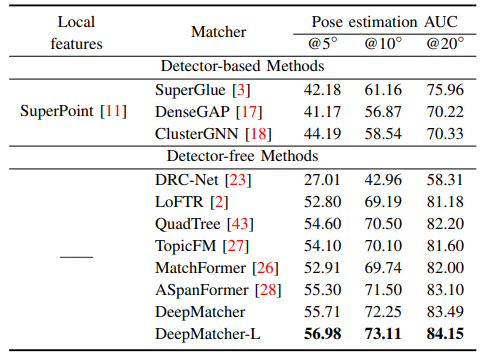
DeepMatcher: A Deep Transformer-based Network for Robust and Accurate Local Feature Matching
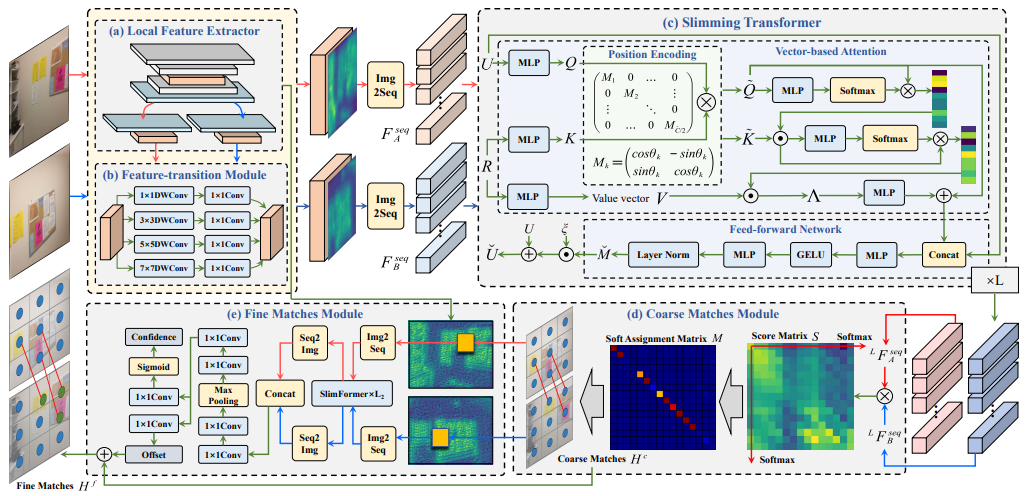
方法:DeepMatcher的主要研究目标是开发一个深度局部特征匹配网络,以提供更易于匹配的人类直观特征,并减少计算复杂性。为了实现这个目标,DeepMatcher采用了Slimming Transformer(SlimFormer)来进行深度特征聚合和长程上下文建模,并引入相对位置编码和特征转换模块(FTM)来提高匹配性能。
创新点:
-
DeepMatcher引入了SlimFormer,这是一种专门为DeepMatcher设计的精简Transformer。SlimFormer利用基于向量的注意力来建模所有关键点之间的相关性,并以高效和有效的方式实现了长程上下文聚合。同时,SlimFormer还应用了相对位置编码,以显式地揭示相对距离信息,从而进一步提高关键点的表示。
-
为了确保从局部特征提取器到SlimFormer之间的平滑过渡,DeepMatcher引入了FTM。FTM通过采用(1×1, 3×3, 5×5, 7×7)深度卷积和1×1点卷积,调整提取特征的感受野,确保在SlimFormer中实现有效的深度特征交互。
2.基于transformer的方法
Gradient-Semantic Compensation for Incremental Semantic Segmentation
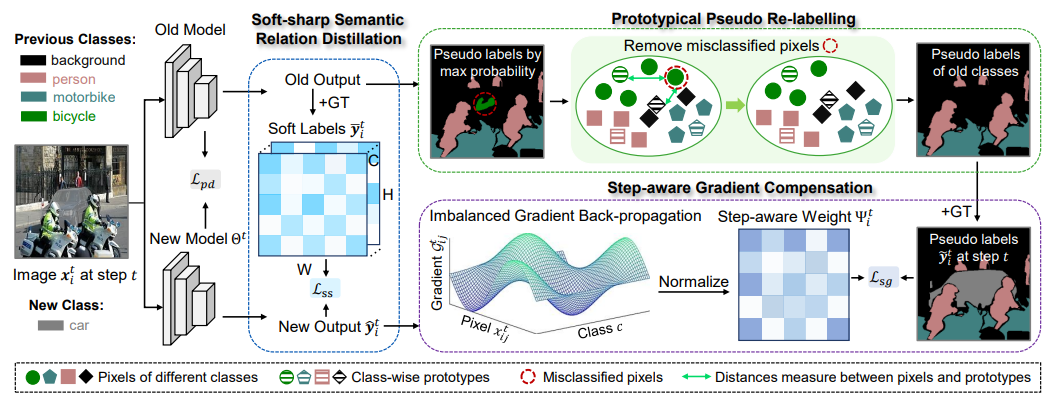
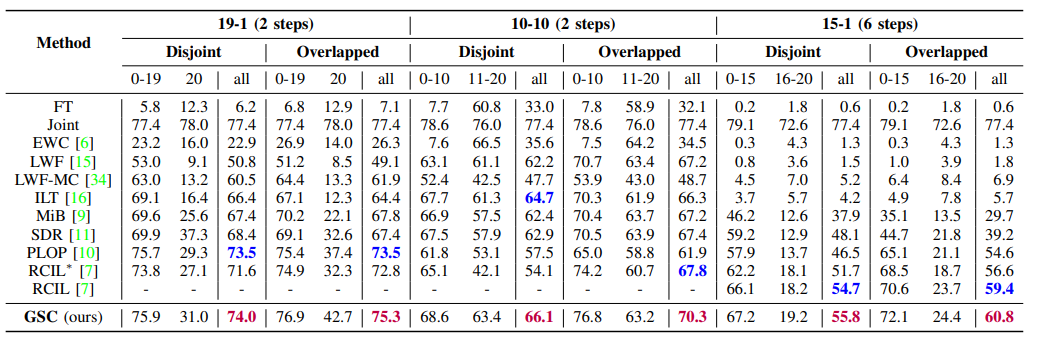
方法:论文提出一种梯度-语义补偿(GSC)模型,以克服增量语义分割的挑战,并解决灾难性遗忘和背景转移问题。通过重新加权梯度反向传播和提供强大的语义指导来平衡旧类的遗忘速度,以及通过伪标签进行背景中的高质量伪标签生成。
创新点:
-
提出了一种梯度-语义补偿(GSC)模型来克服增量语义分割。这是早期考虑梯度和语义补偿的尝试。
-
为了减轻灾难性遗忘,设计了一种步骤感知的梯度补偿,以平衡旧类别的不同遗忘速度,从梯度方面进行平衡。此外,通过构建来自语义方面的软标签,提出了一种软锐语义关系蒸馏,以保持类间语义关系的一致性。
-
为了解决背景转移问题,提出了一种原型假标记重新标记方法,为背景中的旧类别生成高质量的伪标签,从而提供强大的语义指导。
3.基于Patch的方法
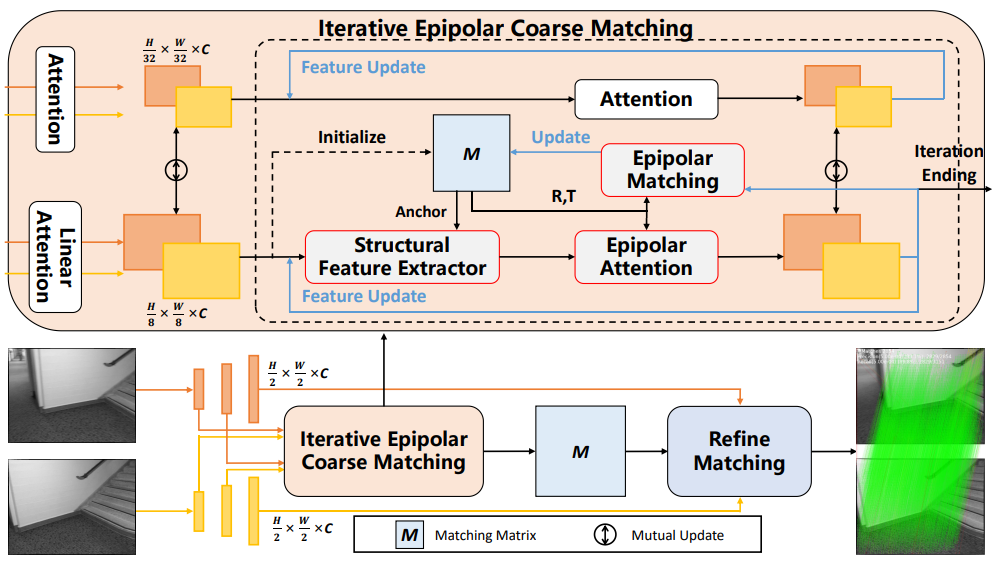
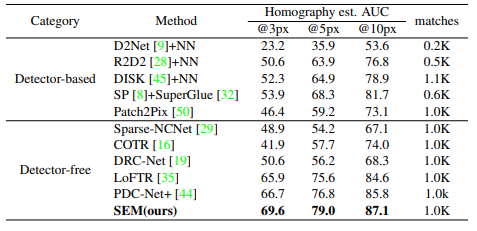
Structured Epipolar Matcher for Local Feature Matching
方法:本文提出了一种新颖的结构化极线匹配器(SEM),用于利用几何先验进行局部特征匹配。为了使特征更具区分度,作者设计了一种结构化特征提取器来补充外观特征。为了尽可能地排除干扰区域,作者提出了可迭代的粗匹配阶段中的极线注意力和匹配。
创新点:
-
结构化极线匹配算法(SEM):该算法通过利用几何先验信息进行局部特征匹配。该算法设计了结构化特征提取器来补充外观特征,使其更具辨别性。同时,该算法利用极线几何先验来排除干扰区域,通过迭代的粗匹配过程逐步优化匹配结果。
-
结构化特征提取器:该特征提取器通过利用像素之间的相对位置关系来构建结构化特征,从而克服了纹理缺失和重复纹理区域带来的挑战,提高了对应关系的准确性。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“特征42”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏
这篇关于深度学习特征提取新突破!42个涨点方案,让模型性能、效率倍增的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







