本文主要是介绍有效识别 63 万个三维空间构型,清华大学牵头发布 Uni-MOF 模型,预测 MOF 吸附能力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
工业世界里,高纯气体被广泛应用于半导体制造、光纤生产、科学研究、医疗健康、环保能源等诸多领域。例如,半导体行业,高纯气体是芯片制造的关键原材料,直接影响着集成电路的性能和良率。
制备高纯气体的关键挑战便是气体分离,常见的气体分离方法有深冷法(精馏原理)、吸附法(分子极性**)、膜法(膜过滤)等。其中,金属有机框架 (MOFs) 由于具有高度有序的孔结构和可调节的孔径大小,在气体吸附存储与分离方面展现出巨大的应用潜力。相关人士预测,MOFs 对 21 世纪的重要性可能与塑料对 20 世纪的重要性一样。
然而准确预测 MOFs 吸附能力仍面临诸多挑战,针对这一问题,清华大学化工系卢滇楠教授团队,联合美国加州大学河滨分校吴建中教授和北京科学智能研究院高志锋研究员,近日在 nature communications 发布了题为「A comprehensive transformer-based approach for high-accuracy gas adsorption predictions in metal-organic frameworks」的最新论文。
本研究提出一种三维 MOF 材料吸附行为预测的机器学习模型 Uni-MOF,用于预测各类工况下纳米多孔材料对各类气体的吸附性能, 这是材料科学领域在机器学习技术应用方面的重大突破。
研究亮点:
-
Uni-MOF 框架是一种多功能解决方案,可用于在不同条件下预测 MOF 的气体吸附能力
-
Uni-MOF 不仅可以通过预训练识别和恢复纳米多孔材料的三维结构,还进一步考虑了温度、压力和不同气体分子等操作条件,这使得其既适用于科学研究又适用于实际应用
-
通过利用其他气体的吸附数据,Uni-MOF 准确预测了未知气体的吸附性能

论文地址:
https://www.nature.com/articles/s41467-024-46276-x
关注公众号,后台回复「吸附」获取完整 PDF
数据集:现有数据库 + 程序生成数据
本研究中,用于预训练的 MOF/COF 结构主要来源于两方面——从当前可用的数据库中收集,或使用相应的程序生成。
目前存在大量的 MOF/COF 数据库,包括计算合成的 hMOFs50 数据库,基于拓扑结构**的晶体构造程序 (ToBaCCo) MOFs,以及实验级别的 CoRE(计算就绪实验)MOFs51,CoRE COFs52 和 CCDC(剑桥晶体学数据中心)等。
此外,在线集成数据库 MOFXDB 中提供了超过 168,000 个 MOF/COF 结构。除了在材料库中探索纳米多孔材料外,研究人员还使用了 ToBaCCo.3.0 程序,生成了超过 306,773 个 MOF 结构。
对于下游任务,即 MOFs 对气体的吸附吸收,研究人员从 MOFXDB 等线上来源收集数据,形成了超过 240 万个 hMOFs 对五种气体 (CO2、N2、CH4、Kr、Xe) 在 273/298 K 和 0.01–10 Pa 条件下的吸附数据集,以及超过 46 万个 CoRE MOFs 对两种气体 (Ar、N2) 在 77/87 K 和 1–105 Pa 条件下的吸附数据集。
此外,研究人员还使用 RASPA54 软件进行了 Grand Canonical Monte Carlo (GCMC) 53 模拟,产生了另外超 9.9 万个气体吸附吸收数据集,其中 5 万个初始化循环和额外的 5 万个循环用于吸附容量样本。收集的吸附数据是在 150–300 K 和 1 Pa–3 bar 范围内获得的,考虑了 7 种气体分子 (CH4、CO2、Ar、Kr、Xe、O2、He)。
模型框架:预训练+多任务预测微调
Uni-MOF 框架包括对三维纳米孔晶体的预训练和在下游应用中进行多任务预测的微调。
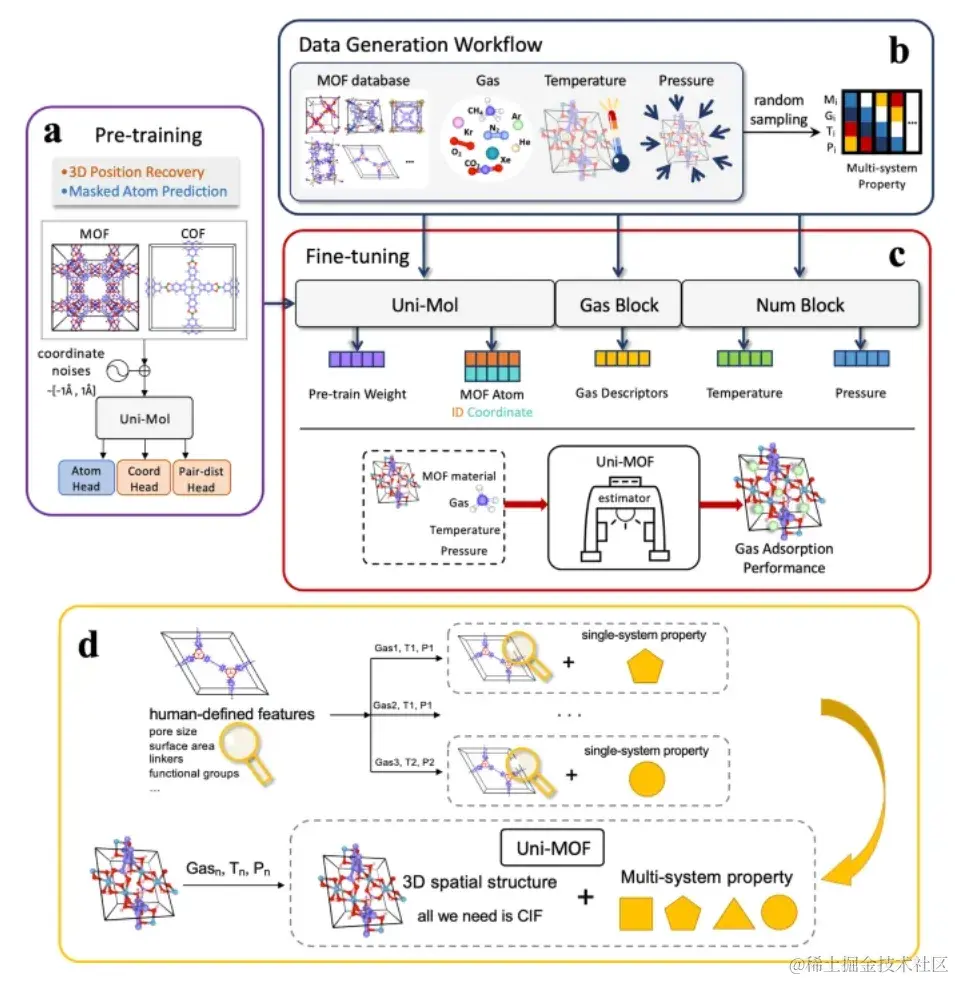
Uni-MOF 框架示意概览
在模型的预训练阶段, 研究人员实施了两类任务以提升模型性能。
第一类任务为预测被遮蔽原子的类型,即识别并预测在分子结构中被掩盖部分的原子种类。第二类任务为执行噪声下的三维坐标恢复任务,具体操作为在 15% 的原子坐标上引入范围在 [-1Å,+1Å] 之间的均匀噪声,进而基于这些受损坐标来计算空间位置编码。
这两类任务旨在增进模型对数据的抗干扰能力,从而在面对后续的预测任务时,提供更加精准的性能。
在微调阶段, 研究人员使用了约 3 百万个标记数据点,涵盖了 MOFs 和 COFs 在各种吸附条件下的情况,从而实现了吸附容量的准确预测。
通过跨系统目标数据的多样数据库,经过微调的 Uni-MOF 能够预测 MOFs 在任意状态下的多系统吸附性能,包括不同的气体、温度和压力。因此,Uni-MOF 是一个统一且易于使用的框架,可用于预测 MOF 吸附剂的吸附性能。
研究结果:Uni-MOF 框架在材料科学领域具有广泛应用
首先,研究人员验证了 Uni-MOF 的预测能力。
预测结果表明,当应用于具有充足数据和相对集中操作状态的数据库时,如 hMOF_MOFX_DB 和 CoRE_MOFX_DB,Uni-MOF 表现出非常高的稳健性,其 R² 值分别为 0.98 和 0.92。在分布广泛的数据集 CoRE_MAP 上,Uni-MOF 的预测精度达到 0.83,仍然可以实现出色的预测准确度,展示了其良好的泛化能力。
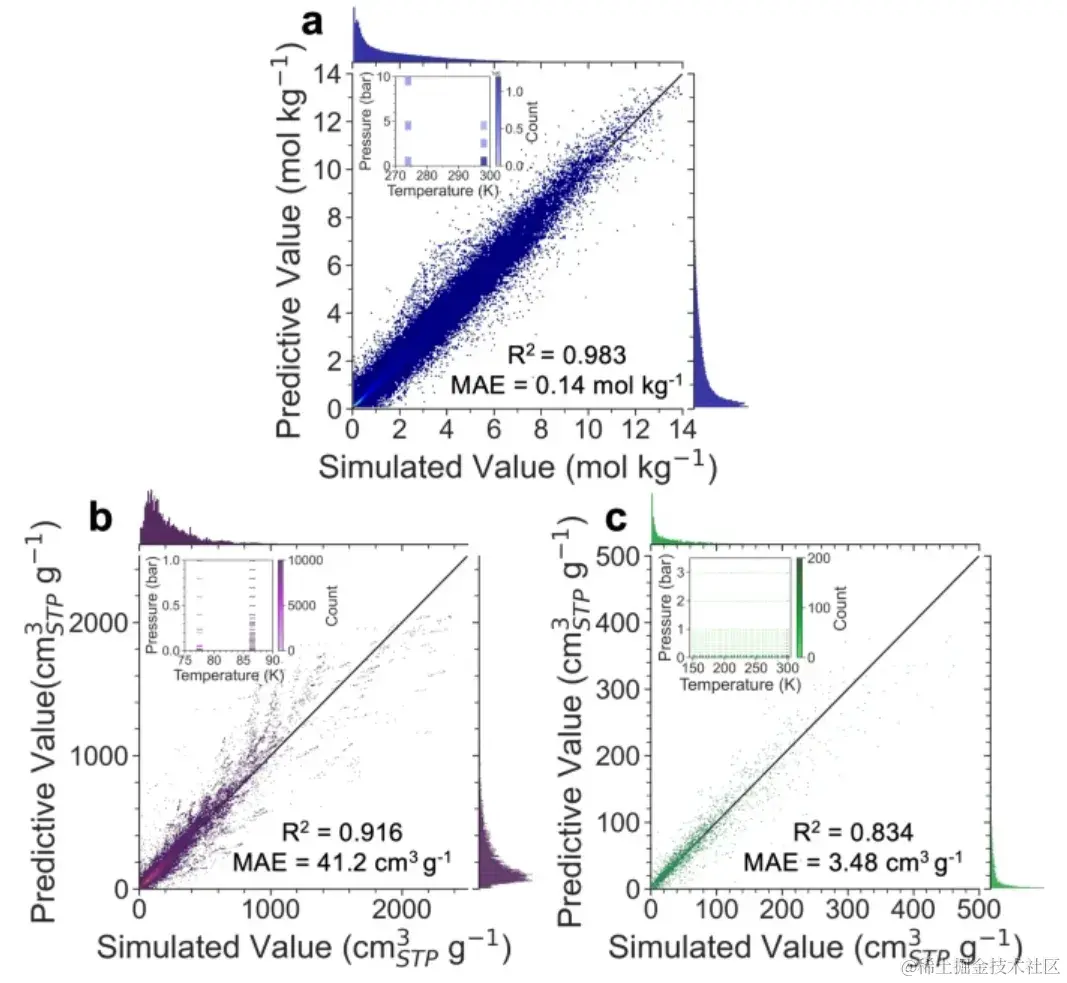
Uni-MOF 在大规模数据库中的整体性能
其次,研究人员将 Uni-MOF 的预测结果与实验收集结果进行了比较。
研究人员发现,Uni-MOF 框架仅基于低压条件下的预测吸附容量,就能够准确筛选出高性能吸附剂。值得注意的是,其在低压条件下的许多预测值与实验值存在显著偏差,特别是在 Mg-dobdc 和 MOF-5 的情况下。但即便如此,在诸多材料之中,Uni-MOF 框架的预测准确度依然名列前茅,这使得其适用于解决工程挑战。
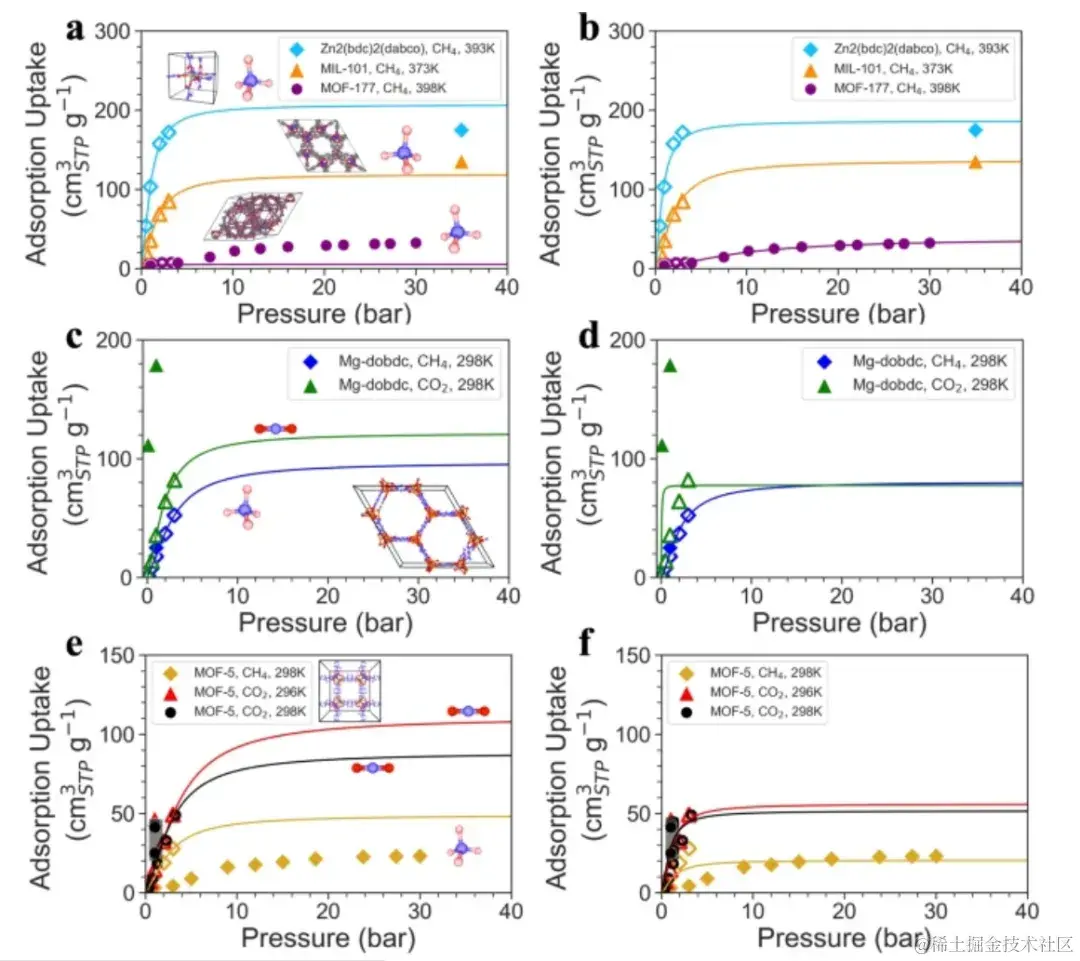
基于低压预测和高压实验值的吸附等温线每条曲线表示 Langmuir拟合
第三,研究人员验证了 Uni-MOF 在跨系统特性方面的预测能力。
试验结果显示,Uni-MOF 在预测未知气体的吸附能力方面表现出了鲁棒性,对氪实现了 0.85 的高预测精度 (R²),对所有未知气体的预测精度均高于 0.35。与单一系统任务相比,Uni-MOF 框架在跨系统数据集上表现出了优越的性能,并且可以准确预测未知气体的吸附性能,显示出其强大的预测能力和普适性。
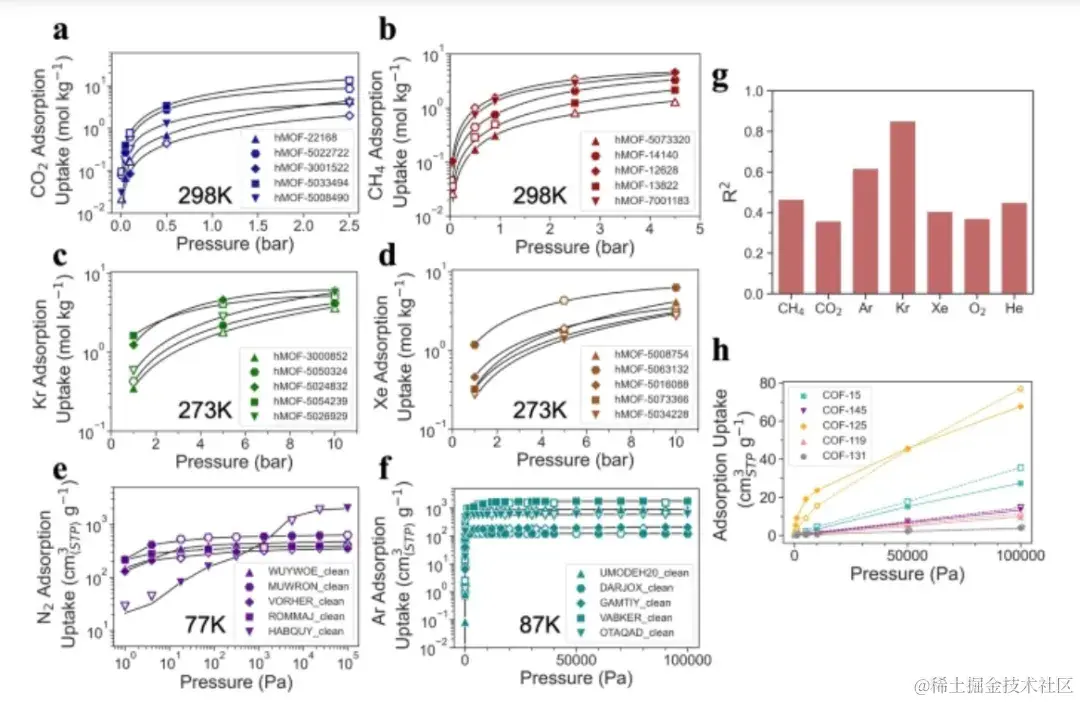
Uni-MOF 跨系统预测案例
另外,为评估该模型在结构识别方面的能力,研究人员以 hMOF-5004238 为例分析了材料结构内部的原子间相互作用力,证明 Uni-MOF 在识别超过 63 万个三维空间构型及其原子间连接关系上的有效性, 突显了该模型的通用性和广阔的应用前景。
总而言之,Uni-MOF 框架是 MOF 材料的多功能预测平台,作为 MOFs 的气体吸附预测器,它在预测各种操作条件下的气体吸附中表现出高精度,并在材料科学领域具有广泛的应用。更重要的是,Uni-MOF 在材料科学领域的机器学习技术应用方面取得了重大突破。
发现—设计—优化,AI 全面加速材料科学
材料科学是一门关乎发现、设计和制造新材料的重要学科,其在各个领域都具有极其重要的作用。从医疗保健到能源储存,从环境保护到信息技术,材料科学的发展对于解决当今社会面临的各种挑战至关重要。
随着技术的不断进步,我们正处于一个材料科学革命的时代,新材料的涌现为人类提供了解决问题的新途径和新工具。随着对材料特性和结构的深入理解,我们有望创造出更轻、更坚固、更节能的材料。
人工智能技术可以加速新材料发现、提升材料性能、降低研发成本,近年来在材料科学领域呈现出巨大的应用潜力。
材料发现与设计:
人工智能技术可以通过高效的数据挖掘和模式识别,加速新材料的发现和设计过程。例如,利用机器学习算法可以对大量已知材料的结构和性能进行分析,从而预测出具有特定性能的新材料。这种方法可以大大缩短材料筛选的时间,并降低试验成本。
2023 年 11 月底,Google DeepMind 在 Nature 杂志发表了论文称,开发了用于材料科学的人工智能强化学习模型 Graph Networks for Materials Exploration (GNoME),并通过该模型和高通量第一性原理计算,寻找到了 38 万余个热力学稳定的晶体材料,相当于「人类科学家近 800 年的知识积累」,极大加快了发现新材料的研究速度。
(点击查看详细报道:DeepMind 发布 GNoME,利用深度学习预测 220 万种新晶体)
材料性能预测:
人工智能技术可以建立高效的预测模型,用于预测材料的性能和行为。这些模型可以基于大量的实验数据或模拟结果进行训练,从而提供对材料性能的准确预测。例如,利用机器学习算法可以预测材料的力学性能、热学性质和电子结构等,为材料设计和应用提供重要参考。
材料优化和设计:
人工智能技术可以通过对材料结构和性能进行智能优化,提高材料的性能和稳定性。例如,利用强化学习算法可以在材料制备过程中实现自动优化,从而实现材料性能的最大化。
材料工艺控制与监测:
人工智能技术可以用于优化材料制备过程,并实现对材料生产过程的智能监测和控制。例如,利用机器学习算法可以分析材料制备过程中的各种参数和条件,优化工艺流程,提高生产效率和材料质量。同时,人工智能技术还可以实现对材料生产过程的实时监测和预警,帮助提前发现和解决潜在问题,降低生产风险。
人工智能技术在材料科学领域的应用已经取得了一系列重要进展,为材料的发现、设计、优化和制备提供了新的思路和方法。未来,科学家们可以利用AI技术更好地预测材料的性能、模拟分子的结构、优化材料的设计、探索材料的性质等等……从而持续推动材料科学领域的进步和创新。
参考资料:
1.https://www.nature.com/articles/s41467-024-46276-x#Sec11
2.https://www.sohu.com/a/753459278_661314
3.https://www.tsinghua.edu.cn/info/1175/110086.htm
这篇关于有效识别 63 万个三维空间构型,清华大学牵头发布 Uni-MOF 模型,预测 MOF 吸附能力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







