清华大学专题

AI革命:清华大学揭秘大模型工具学习的未来
🌟 未来已来:大模型工具学习开启智能新时代 🌟 清华大学THUNLP最新研究,探索AI工具使用的无限可能 文末有报告免费下载,需要的朋友自行下跳。 亲爱的读者朋友们,人工智能的浪潮已经不可阻挡地涌入我们的生活。今天,我们要带您走进清华大学自然语言处理与社会人文计算实验室(THUNLP )的最新研究——大模型工具学习,一窥AI如何借助工具,释放出超越人类的巨大潜力。 一、工具学习的

清华大学副教授都志辉讲座笔记
第一版中,讲MPI并行代码直接用cuda重写,一个月完成,发现有大量计算错误,并且不能排查。(结果不一样原因就是移植的代码错了,因为移植过程不可能完全想明白程序逻辑,总会有各种各样的问题出来,这也是大型应用程序移植的难点) 第二版中的解决方法就是要做单元拆分。并且一直的时候分析代码并重写,写成适合cuda计算的数据结构。 在能提升性能地方的代码用cuda一直,没有什么提升余地的地方用Ope
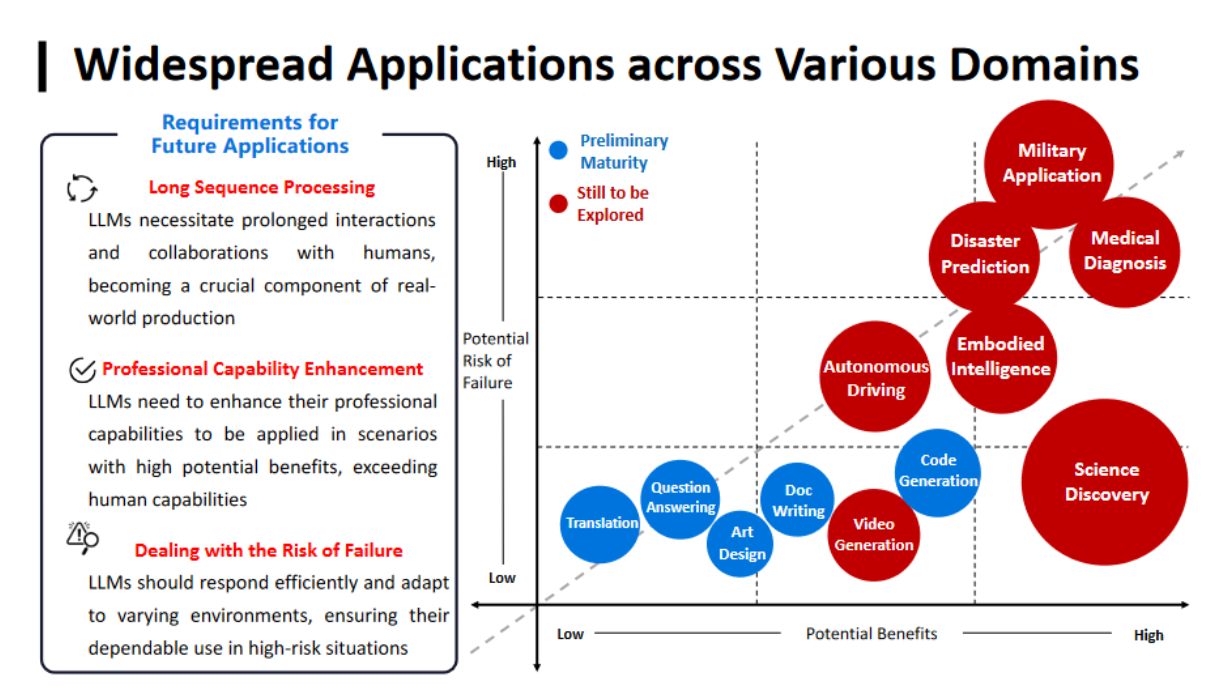
【Lecture1】清华大学大模型公开课——大模型绪论
#清华大模型公开课第二季 #OpenBMB 目录 1. The Evolution of Artificial Intelligence --History 人工智能的演变--历史 1.1 Definition of AI --定义 1.2 Conceptualization of AI -- 概念 1.3 Birth of AI as a Discipline 1.4 Develop

数据结构 C++语言版 清华大学第三版 学习笔记
绪论 绪论一道冒泡排序拍懵我了,我以为 O ( n 2 ) O(n^2) O(n2) 复杂度的经典冒泡排序没有优化空间了,结果一个bool标识打脸,可以提前终止冒泡,如果已经是按顺序了的数组的话: void bubblesort1A(int A[], int n) { //起泡排序算法(版本1A):0 <= n bool sorted = false; //整体排序标志,首先假定尚未排序 w

pip设置国内源:阿里云、腾讯云、清华大学源
更换Python的pip源(尤其是默认源访问速度较慢时)是一个常见需求,可以显著提升安装Python包的速度。以下是如何为pip设置国内源的步骤,以阿里云、腾讯云、清华大学源为例: 1. 备份原有源配置(可选但推荐) 在进行任何更改之前,备份现有的pip配置文件是一个好习惯。这样,如果遇到问题,你可以轻松恢复到初始状态。 Bash 1mkdir ~/.pip_backup2cp ~/

清华大学|情绪研究的日常动态心理生理记录数据集DAPPER
清华大学心理学系团队发布面向情绪研究的日常动态心理生理记录数据集DAPPER 为了更好地理解人类情绪的心理和生理基础,人们对实验室以外的情绪相关数据的动态记录越来越感兴趣。通过使用基于智能手机的动态评估和手腕佩戴的生理记录设备,日常情绪研究的动态心理和生理记录(DAPPER)数据集提供人们在日常生活中的情绪体验的瞬时自我报告和生理数据。此数据集包括142名参与者的动态心理记录和其中88人在五天内

清华大学与智谱AI重磅开源 GLM-4:掀起自然语言处理新革命
在强大的预训练基础上,GLM-4-9B 的中英文综合性能相比 ChatGLM3-6B 提升了 40%。尤其是中文对齐能力 AlignBench、指令遵从能力 IFeval,以及工程代码处理能力 Natural Code Bench 方面都实现了显著提升。 自 2023 年 3 月 14 日开源 ChatGLM-6B 以来,GLM 系列模型受到了广泛的关注和认可。特别是在 ChatGLM3-6B

清华大学孙茂松:人工智能会取代部分低端智力劳动者,但不可能发现牛顿定律
5月23日,清华大学人工智能研究院常务副院长、欧洲科学院外籍院士孙茂松在北大光华度小满大模型公开课中,阐述了生成式人工智能对科技、文化和教育的影响。他认为,生成式人工智能(GAI)的基本定位是启发、辅助人类,不会取代人类,但会取代相当部分低端智力劳动者。 公开课上,孙茂松教授首先向大家介绍了生成式人工智能背后的计算机制——大模型,也叫语言的生成模型。这个模型驱动它的机理实际上非常简单,叫“下一个
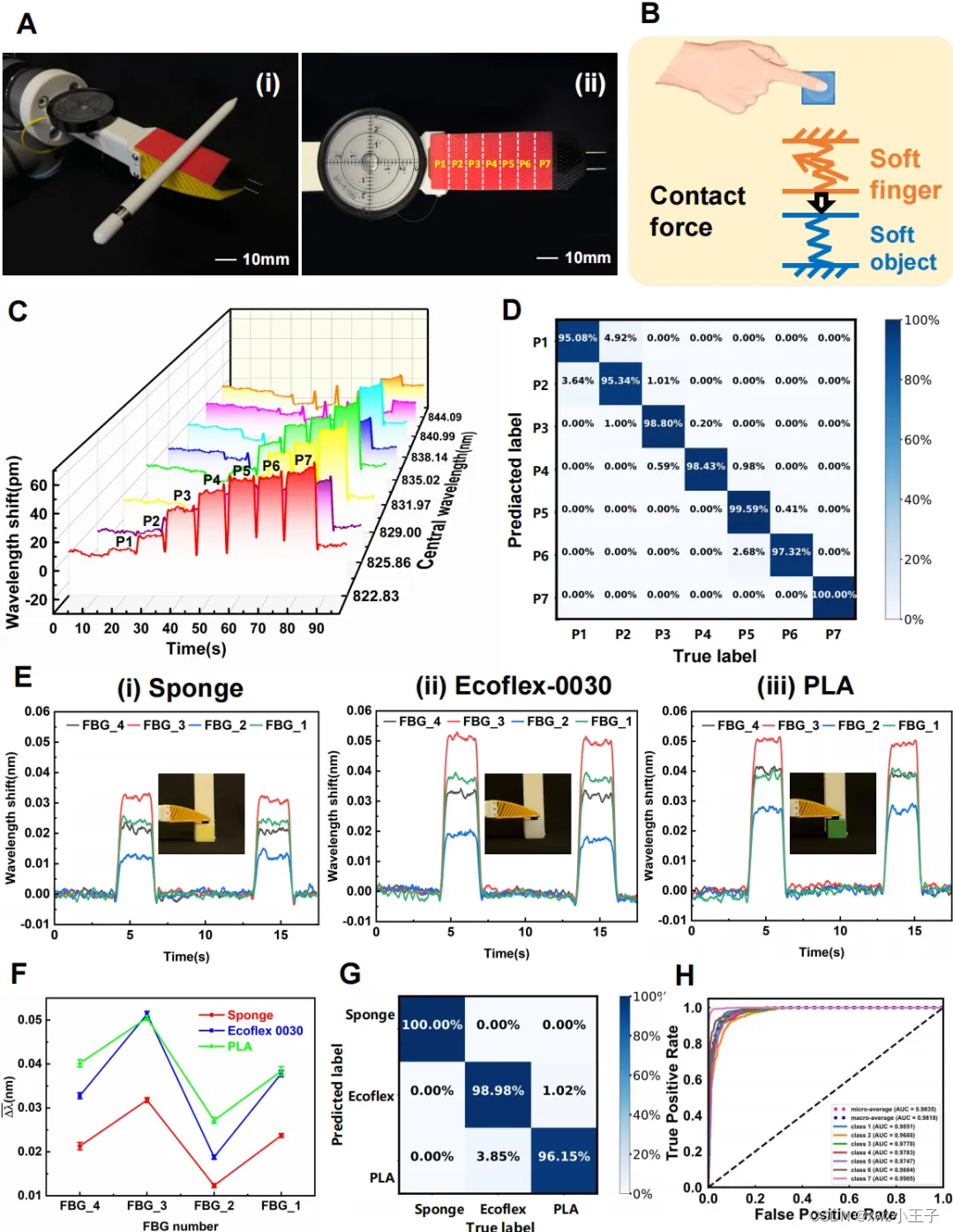
Advanced Intelligent Systems 清华大学曲钧天团队设计了基于光纤传感技术的多模态触觉感知仿生机械手
随着软体机器人技术的发展,触觉感知在人机安全交互、可穿戴设备和医疗器械领域发挥着重要作用。如何用简单的系统集成更多的触觉感知、获取更多交互信息面临着诸多挑战。 近日,清华大学国际研究生院曲钧天助理教授团队在国际期刊Advanced Intelligent Systems上发表以“A Bioinspired Robotic Finger for Multimodal Tactile Sensing

【清华大学】《自然语言处理》(刘知远)课程笔记
自然语言处理基础(Natural Language Processing Basics, NLP Basics) 自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然
备战 清华大学 上机编程考试-冲刺前50%,倒数第6天
真题训练: T1:舞蹈团 - 排序+滑动窗口 生活在在外星球X上的小Z想要找一些小朋友组成一个舞蹈团,于是他在网上发布了信息,一共有 \(n\) 个人报名面试。面试必须按照报名的顺序依次进行。小Z可以选择在面试完若干小朋友以后,在所有已经面试过的小朋友中进行任意顺序的挑选,以组合成一个舞蹈团。虽然说是小朋友,但是外星球X上的生态环境和地球上的不太一样,这些小朋友的身高可能相差很大。小Z希望组建

清华大学提出IFT对齐算法,打破SFT与RLHF局限性
监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是预训练后提升语言模型能力的两大基础流程,其目标是使模型更贴近人类的偏好和需求。 考虑到监督微调的有效性有限,以及RLHF构建数据和计算成本高昂,这两种方法常常被结合使用。但由于损失函数、数据格式的差异以及对
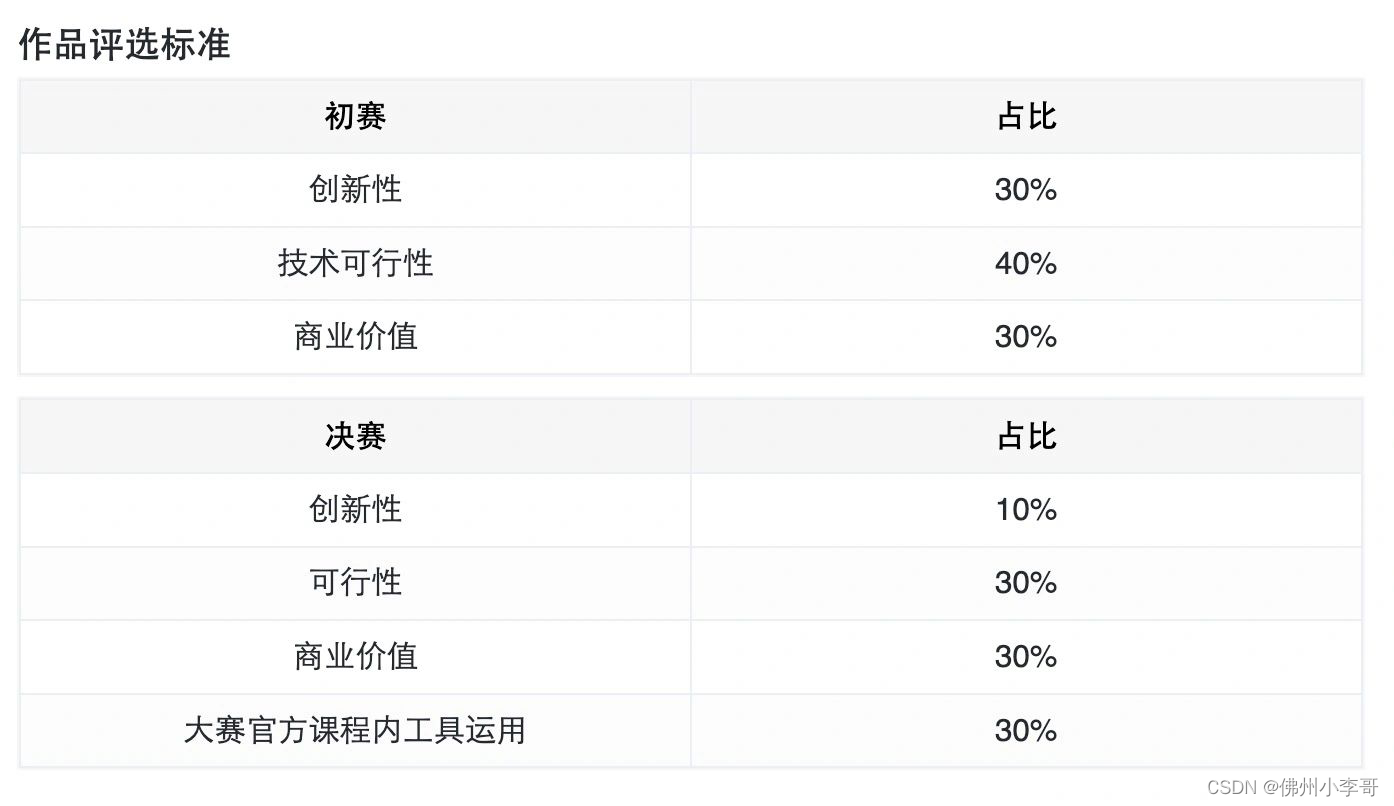
清华大学和亚马逊云科技等联名举办的GenAI应用挑战赛来不来?
亚马逊云科技和上海市人工智能行业协会、北京智源人工智能研究院指导,上海数据交易所、清华大学人工智能研究院基础模型研究中心、(所有主办方在下图,中国AI界明星天团),联合主办的中国生成式AI应用创新挑战赛开始报名了! 总决赛还会在5/30上海举办的亚马逊云科技Summit峰会上路演哦。下面带大家了解一下这次大赛➡️赛事简介 所有报名选手将通过学习本次比赛发布的一系列课程,掌握生成式AI核心理论和
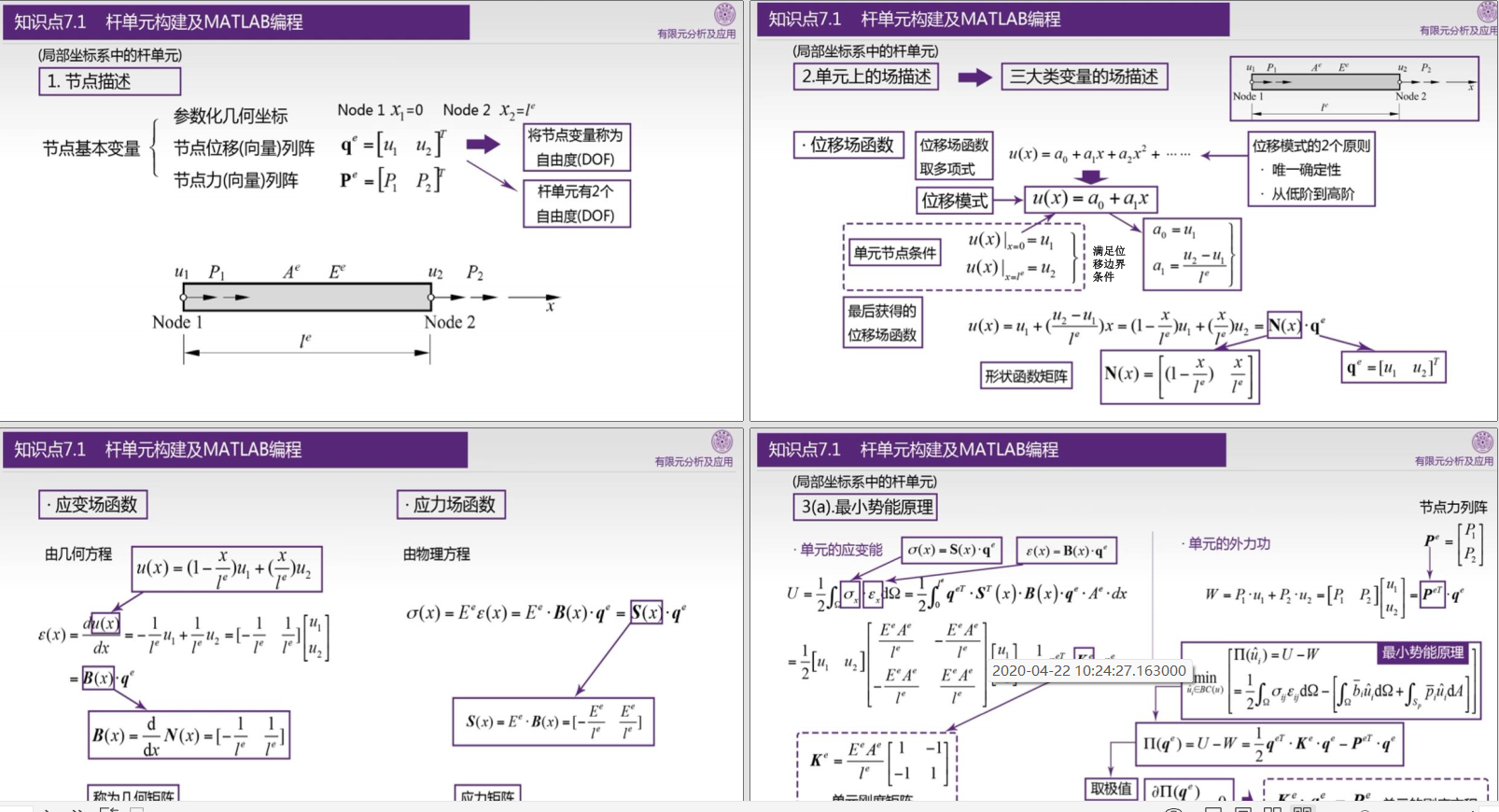
《有限元分析及应用》《有限元分析基础教程》-曾攀-清华大学|pdf电子书+有限元分析及应用视频教程(全85讲) 曾攀、雷丽萍 +课件PPT
专栏导读 作者简介:工学博士,高级工程师,专注于工业软件算法研究本文已收录于专栏:《有限元编程从入门到精通》本专栏旨在提供 1.以案例的形式讲解各类有限元问题的程序实现,并提供所有案例完整源码;2.单元类型包含:杆单元,梁单元,平面三角形单元,薄板单元,厚板单元,壳单元,四/六面体实体单元,金字塔单元等;3.物理场问题涉及:力学、传热学、电磁学及多物理场耦合等问题的稳态(静力学)和瞬态(动力学)

清华大学 【战略管理的逻辑】全6讲笔记
讨论从20世纪初的企业管理背景入手,讲述了随着经济和技术的进步,企业管理理念和实践所经历的主要变化。 1.战略管理的重要性及其时代演变 在过去的几十年里,企业管理的理念和方法经历了从重视生产效率到注重市场营销,再到强调战略规划的根本转变。20世纪二三十年代,随着劳动生产率的提升,产品开始出现剩余,高效生产和低成本成为企业竞争的关键因素。进入四五十年代,尽管劳动

清华大学灵境智能技术交叉创新群体博士后,综合年收入30-60万
清华大学灵境智能技术交叉创新群体现面向全球招聘优秀博士后研究人员,以进一步推动三维生成、三维重建、多模态智能交互、控制交互演化、知识工程及情感计算等领域的研究。我们诚邀有志于从事交叉学科研究的青年才俊加入我们的团队,共同探索智能技术的前沿领域。 一、博士后合作导师介绍 本次招聘的博士后合作导师为中国工程院院士、清华大学戴琼海教授以及国家杰青、清华大学陶建华教授。两位导

清华大学:序列推荐模型稳定性飙升,STDP框架惊艳登场
获取本文论文原文PDF,请公众号留言:论文解读 引言:在线平台推荐系统的挑战与机遇 在线平台已成为我们日常生活中不可或缺的一部分,它们提供了丰富多样的商品和服务。然而,如何为用户推荐感兴趣的项目仍然是一个挑战。为了解决这个问题,研究者们提出了序列推荐任务,旨在从用户的历史行为序列中提炼出用户的兴趣,并据此进行恰当的推荐。尽管现有的方法在捕捉用户兴趣方面取得了一定的进展,但随机噪声的存

二叉树遍历——清华大学复试上机
文章目录 二叉树遍历——清华大学复试上机题目描述进行对题目的解析 创建结构体核心代码配图详解 要将得到的树中序遍历中序遍历核心代码 源代码运行结果 二叉树遍历——清华大学复试上机 题目描述 题目描述 编一个程序,读入用户输入的一串先序遍历字符串,根据此字符串建立一个二叉树(以指针方式存储)。 例如如下的先序遍历字符串: ABC##DE#G##F### 其中“#”表示的是空格,空

使用SVM/k-NN模型实现手写数字多分类 - 清华大学《机器学习实践与应用》22春-周作业
0 Contents 1.1 多分类SVM主要思想1.1.1 一对一SVM分类(OvO-SVM)1.1.2 一对多SVM分类(OvR-SVM) 1.2 实验设计及伪代码1.2.1 实验目的概述1.2.2 实验模型整体设计1.2.3 多分类伪代码及解释1.2.4 完整代码实现 1.3 测试结果及分析1.4 其他实验体会 1.1 多分类SVM主要思想 SVM模型处理分类问题建立在

清华大学大数据能力提升项目三名学生斩获2017年中国高校SAS数据分析大赛亚军
2017年11月20日,2017中国高校SAS数据分析大赛颁奖典礼在钓鱼台国宾馆举行。清华大学今年首次组队参赛,在与北京大学、人民大学、复旦大学等1036支参赛团队激烈比拼后,清华大学大数据能力提升项目的三位学生——王存光、姚超、李继凡组成的团队一举荣获亚军。 颁奖典礼现场 亚军获奖证书 中国高校SAS数据分析大赛举办五届以来,通常是金融专业和统计学专业学生的天下。此

重磅 | 2018年清华大学研究生新生大数据
编者按:又是一年金秋时节,美丽的清华园即将迎来许多新鲜的面孔,2018级研究生新生将成为这个园子的新主人,书写属于自己的清韵华章。 本文带你走近园子的新主人…… 2018年,园子迎来研究生新生共8310人,硕博比例约为1.83:1。 男女比:向来都是万众期待的一个数据。整体来看,新生同学男女比约为1.8:1,硕、博男女比分别为1.7:1与2.2:1。 君家住何处?:新生
THE世界大学排名发布:牛津大学蝉联榜首,清华大学亚洲第一
来源:腾讯体育 本文约2000字,建议阅读5分钟。 本文为大家分析了THE世界大学排名以及中国高校的上榜情况。 9月26日,泰晤士高等教育(THE)发布了2019年世界大学排名,牛津大学连续第三年位列榜首,剑桥大学排名第二。 中国高校表现亮眼,清华大学与去年相比上升8位,排名第22,同时超越新加坡国立大学,成为亚洲排名第一的大学,这也是自2011年以来,中国高校按照现有评比方法首次位列亚洲第
清华大学矣晓沅:“九歌”——基于深度学习的中国古典诗歌自动生成系统
授权自AI科技大本营(ID:rgznai100) 本文共2714字,建议阅读6分钟。本文为你介绍清华自然语言处理与社会人文计算实验室的自动作诗系统——“九歌”及其相关的技术方法和论文。 [ 导读 ]近年来人工智能与文学艺术的结合日趋紧密,AI 自动绘画、自动作曲等方向都成为研究热点。诗歌自动生成是一项有趣且具有挑战性的任务。在本次公开课中, 讲者将介绍清华自然语言处理与社会人文计算实验室的自
“计算社会科学数据平台”在清华大学发布(附账号申请链接)
2018年12月5日,由清华大学社会科学学院与数据科学研究院主办,清华大学经管学院、人文学院、教育研究院、马克思主义学院、公管学院、法学院、新闻学院共同参与的“计算社会科学数据平台”联合发布会于清华大学主楼召开。此次发布会以“智汇社科 重塑未来”为主题,邀请多个院系的专家代表出席并做主题分享,在与会嘉宾共同参与见证下发布了“计算社会科学数据平台”。 “计算社会科学数据平台”发布仪式,与会