本文主要是介绍清华大学:序列推荐模型稳定性飙升,STDP框架惊艳登场,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
获取本文论文原文PDF,请公众号留言:论文解读

引言:在线平台推荐系统的挑战与机遇
在线平台已成为我们日常生活中不可或缺的一部分,它们提供了丰富多样的商品和服务。然而,如何为用户推荐感兴趣的项目仍然是一个挑战。为了解决这个问题,研究者们提出了序列推荐任务,旨在从用户的历史行为序列中提炼出用户的兴趣,并据此进行恰当的推荐。尽管现有的方法在捕捉用户兴趣方面取得了一定的进展,但随机噪声的存在仍然是一个主要挑战。在现实世界的推荐平台中,随机噪声可能来源于用户从多个合适的候选项中随机选择一个项目,或者用户以随机顺序访问多个项目。这种随机噪声会导致序列无法为描述用户偏好提供稳定的监督信号,从而干扰模型的优化。
面对这一挑战,研究者们提出了多种方法来处理噪声问题,包括过滤掉不可靠的实例、建模反事实数据分布以及采用两阶段方法来校正序列。然而,这些方法往往依赖于定位噪声项/动作,可能会带来错误累积问题,而且随机项也包含了描述用户偏好的有价值信息。
本文提出了一个新的框架——统计驱动的预训练(STDP)框架,它利用统计信息和预训练范式来稳定推荐模型的优化。通过这种方法,模型的鲁棒性得到了增强,同时也促进了模型对用户长期偏好的捕捉。实验结果验证了我们提出的STDP框架的有效性,它改进了现有方法并取得了最先进的性能。
论文概览:标题、作者、出版信息和链接
标题: Beyond the Sequence: Statistics-Driven Pre-training for Stabilizing Sequential Recommendation Model
作者: Sirui Wang, Peiguang Li, Yunsen Xian, Hongzhi Zhang
出版信息: Seventeenth ACM Conference on Recommender Systems (RecSys ’23), September 18–22, 2023, Singapore, Singapore. ACM, New York, NY, USA
链接: https://arxiv.org/pdf/2404.05342.pdf
随机噪声对推荐系统的影响
1. 随机噪声的来源和问题
在现实世界的推荐平台中,随机噪声可能源自用户在多个合适候选项中随机选择一个项目,或者用户以随机顺序访问多个项目等情况。这种随机性导致序列不能提供稳定的监督信号来描述用户偏好,进而干扰了推荐模型的优化过程。
Sun等人首先验证了噪声行为的存在和严重性,并提出了一个过滤器来移除不可靠的实例。Zhang等人提出了对抗稀疏和噪声特性的行为序列的反事实数据分布模型。Lin等人提出了一种两阶段方法,首先通过调整噪声项目来纠正序列,然后用纠正后的序列训练模型。然而,现有方法依赖于定位噪声项/动作,并带来错误累积问题,而且随机项也包含描述用户偏好的有价值信息。
2. 现有方法的局限性
尽管现有方法在定位噪声项/动作方面取得了一定的进展,但它们存在依赖于错误累积的问题。此外,这些方法忽略了随机项中包含的描述用户偏好的有价值信息。因此,需要一种方法来减少随机噪声对模型优化的影响,并利用更稳定的信息来提高推荐系统的性能。
STDP框架介绍:统计信息驱动的预训练
1. 框架概述与基础模型
STDP(StatisTics-Driven Pre-training)框架利用统计信息和预训练范式来稳定推荐模型的优化。该框架采用SASRec作为基础模型,并设计了几个预训练任务:共现项目预测(CIP)、成对序列相似性(PSS)、频繁属性预测(FAP)和由Zhou等人提出的项目属性预测(IAP)。
基础模型SASRec主要由嵌入层、编码层和预测层组成。嵌入层将用户访问的项目序列映射为d维向量序列,并集成位置特征。编码层使用多个自注意力块进行序列编码,生成序列的表示。预测层计算用户在下一步访问项目的概率。
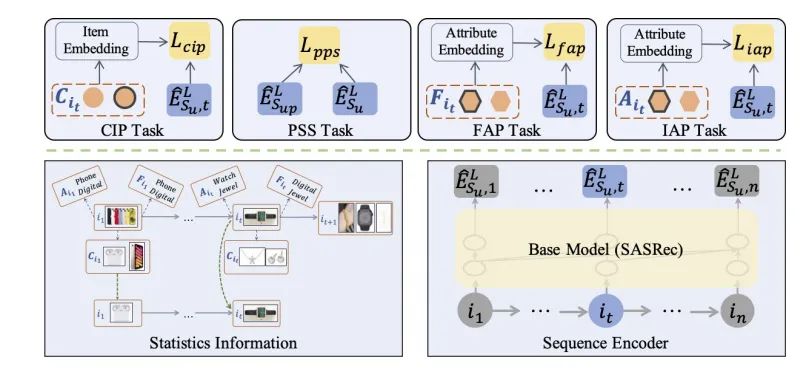
2. 预训练任务的设计
STDP框架设计了以下预训练任务:
- 共现项目预测(CIP):优化模型以预测下一个项目及其最常共现的项目,鼓励模型关注多个合适的目标,而不仅仅是可能不稳定的下一个项目。
- 成对序列相似性(PSS):通过将原始序列中的部分项目随机替换为它们的共现项目来生成成对序列,然后最大化原始序列和成对序列表示之间的相似性,增强模型对随机噪声的鲁棒性。
- 频繁属性预测(FAP):鼓励模型基于序列特征预测频繁属性,以促进捕获用户的长期偏好。
通过这些预训练任务,STDP框架提高了模型对随机访问输入的鲁棒性,并通过统计信息帮助模型捕获稳定的长期偏好。
统计信息的作用
在推荐系统中,统计信息的作用不可忽视。它为模型提供了稳定的信息,有助于减少随机噪声对模型优化的影响。本文中,我们特别关注了两种统计信息:项目共现信息和属性频率信息。
1. 项目共现信息的利用
项目共现信息是通过统计训练数据中项目的共现情况得到的。在本研究中,我们提出了两个预训练任务来利用这些信息。首先是共现项目预测(Co-occurred Items Prediction, CIP)任务,它鼓励模型预测下一个项目及其共现项目,从而使模型关注多个合适的目标,而不是仅仅集中在可能不稳定的下一个项目上。其次是配对序列相似性(Paired Sequence Similarity, PSS)任务,通过随机替换序列中的部分项目为它们的共现项目,并随机交换项目顺序,来模拟用户随机访问多个项目的情况。这样,模型在输入中模仿随机访问,从而增强了其鲁棒性。
2. 属性频率信息的应用
属性频率信息是通过统计序列中属性的出现频率得到的。在本文中,我们设计了一个序列级的频繁属性预测(Frequent Attribute Prediction, FAP)任务,鼓励模型基于序列特征预测频繁属性,从而帮助捕捉用户的长期偏好。这种方法的有效性得到了实验结果的验证,它改进了现有方法,实现了最先进的性能。
实验设置与评估方法
数据集和实验环境
1. 数据集和实验环境
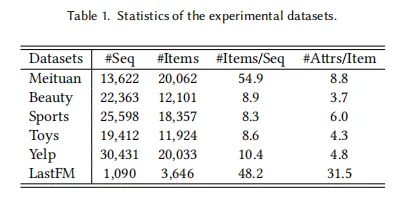
实验选择了六个公共数据集,包括美团、亚马逊(包括美容、运动和玩具)、Yelp和LastFM平台的数据集。这些数据集的详细统计信息列在表1中。实验数据由S3-Rec发布,其中项目序列按时间顺序组织。在数据准备过程中,共现项目集、属性集和喜好集的大小都限制为20,PSS任务中的替换率设置为0.2。序列长度填充到50,每个小批量的大小填充到256。
2. 评估指标和基线方法
为了与先前的方法进行公平比较,我们保留了每个序列中的最后一个和倒数第二个项目作为测试和验证,其余项目用于训练。我们采用命中率(Hit Ratio, HR@5和HR@10)、归一化折扣累积增益(Normalized Discounted Cumulative Gain, NDCG@5和NDCG@10)和平均倒数排名(Mean Reciprocal Rank, MRR)作为评估指标。值得注意的是,评估是基于采样的项目集进行的。
我们选择了以下几种竞争性的基线方法进行性能比较:SASRec利用多头自注意力机制从Transformer网络捕获长期语义;BERT4Rec采用双向自注意力机制,并使用Cloze目标损失进行预训练;FDSA将异构信息集成到项目序列中,并从多个角度预测下一个项目;S3-Rec预训练SASRec模型以捕获异构信息之间的相关性,从而改进序列推荐,实现了最先进的性能。
实验结果与分析
1. STDP框架的整体性能
在实验中,我们的STDP框架在六个数据集上的表现均优于现有的基线方法。通过对比实验,我们发现STDP框架在MRR指标上平均提升了17.66%,并且在所有数据集上都实现了最佳得分。这一结果表明,STDP框架能够有效地利用统计信息来减少随机噪声的负面影响,从而提高了模型的整体性能。
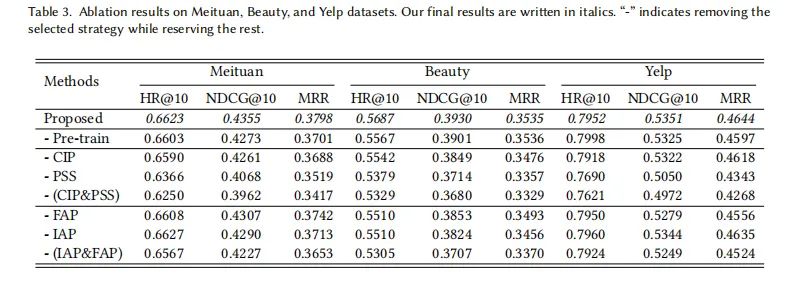
2. 消融研究:各个任务的贡献
为了进一步理解STDP框架中各个任务的贡献,我们进行了一系列的消融实验。结果显示,去除配对序列相似性(PSS)任务会比去除共现项目预测(CIP)任务对性能产生更大的影响。这可能是因为PSS任务直接作用于序列层面,而CIP任务则在项目层面发挥作用。此外,当同时去除CIP和PSS任务时,性能显著下降,这验证了全局共现信息在模型中的重要性。
3. 泛化能力验证
为了验证STDP框架的泛化能力,我们将其应用于GRU4Rec模型,并观察到性能有了显著提升。这一结果表明,STDP框架不仅适用于SASRec模型,也能够有效地提升其他序列推荐模型的性能,证明了其良好的泛化能力。

结论与未来展望
1. STDP框架的优势总结
本文提出的STDP框架通过利用统计信息和预训练任务来减少随机噪声的影响,显著提高了序列推荐模型的稳定性和性能。实验结果表明,STDP框架在多个数据集上均取得了最佳性能,证明了其有效性。
2. 对其他模型的推广潜力
STDP框架的设计不依赖于特定的序列推荐模型,因此具有很好的推广潜力。实验中将STDP应用于GRU4Rec模型也取得了积极的结果,这进一步验证了STDP框架的通用性和适用性。
3. 后续研究方向
尽管STDP框架已经显示出强大的性能,但仍有进一步的研究空间。未来的研究可以探索更多类型的统计信息,以及如何更有效地整合这些信息以进一步提升模型的鲁棒性和准确性。此外,可以考虑将STDP框架应用于更广泛的序列建模任务中,以验证其在不同领域的有效性。
这篇关于清华大学:序列推荐模型稳定性飙升,STDP框架惊艳登场的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








