本文主要是介绍Python实现BOA蝴蝶优化算法优化卷积神经网络分类模型(CNN分类算法)项目实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1.项目背景
蝴蝶优化算法(butterfly optimization algorithm, BOA)是Arora 等人于2019年提出的一种元启发式智能算法。该算法受到了蝴蝶觅食和交配行为的启发,蝴蝶接收/感知并分析空气中的气味,以确定食物来源/交配伙伴的潜在方向。
蝴蝶利用它们的嗅觉、视觉、味觉、触觉和听觉来寻找食物和伴侣,这些感觉也有助于它们从一个地方迁徙到另一个地方,逃离捕食者并在合适的地方产卵。在所有感觉中,嗅觉是最重要的,它帮助蝴蝶寻找食物(通常是花蜜)。蝴蝶的嗅觉感受器分散在蝴蝶的身体部位,如触角、腿、触须等。这些感受器实际上是蝴蝶体表的神经细胞,被称为化学感受器。它引导蝴蝶寻找最佳的交配对象,以延续强大的遗传基因。雄性蝴蝶能够通过信息素识别雌性蝴蝶,信息素是雌性蝴蝶发出的气味分泌物,会引起特定的反应。
通过观察,发现蝴蝶对这些来源的位置有非常准确的判断。此外,它们可以辨识出不同的香味,并感知它们的强度。蝴蝶会产生与其适应度相关的某种强度的香味,即当蝴蝶从一个位置移动到另一个位置时,它的适应度会相应地变化。当蝴蝶感觉到另一只蝴蝶在这个区域散发出更多的香味时,就会去靠近,这个阶段被称为全局搜索。另外一种情况,当蝴蝶不能感知大于它自己的香味时,它会随机移动,这个阶段称为局部搜索。
本项目通过BOA蝴蝶优化算法优化卷积神经网络分类模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 因变量 |
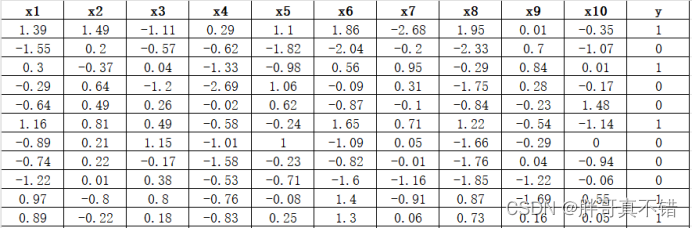
数据详情如下(部分展示):
3.数据预处理
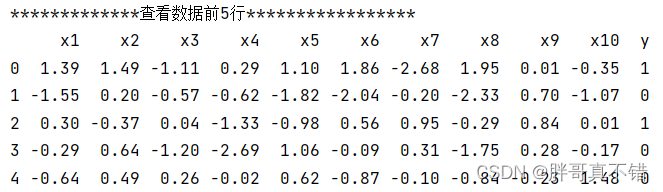
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
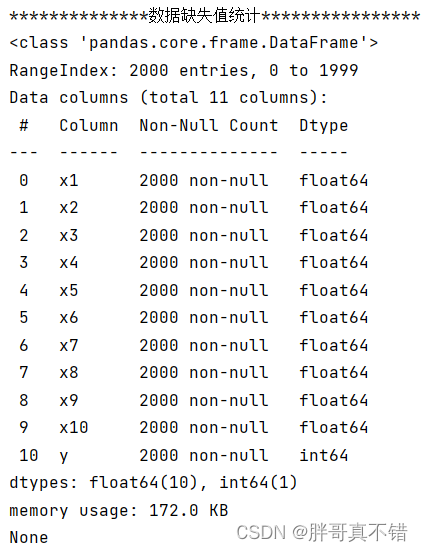
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
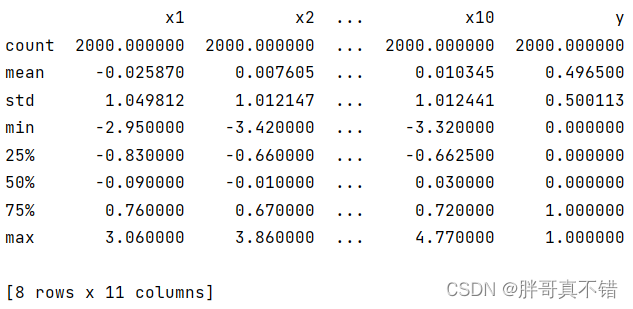
关键代码如下:

4.探索性数据分析
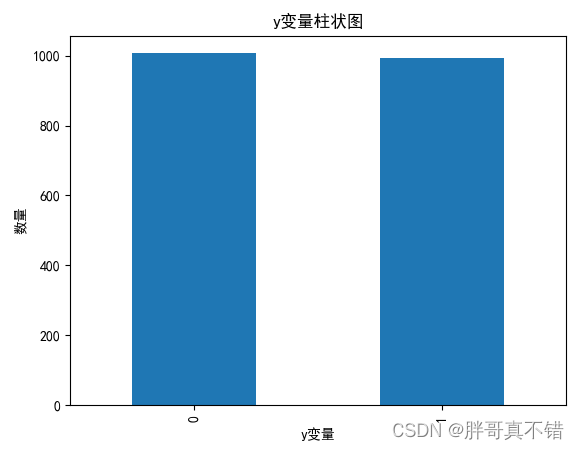
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:

4.3 相关性分析
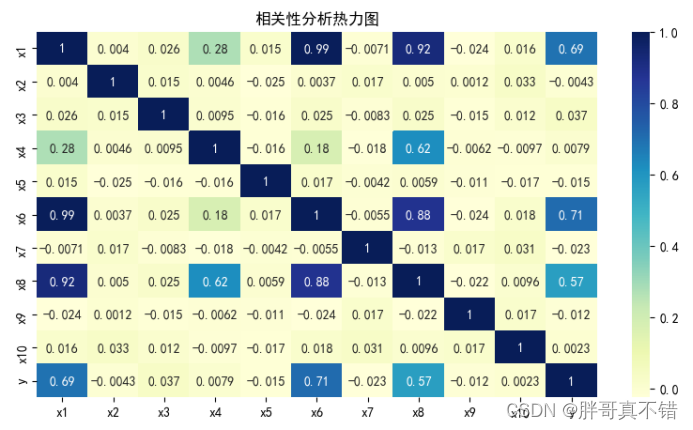
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
![]()
5.3 数据样本增维
数据样本增加维度后的数据形状:

6.构建BOA蝴蝶优化算法优化CNN分类模型
主要使用BOA蝴蝶优化算法优化CNN分类算法,用于目标分类。
6.1 BOA蝴蝶优化算法寻找最优参数值
最优参数:

6.2 最优参数值构建模型
| 编号 | 模型名称 | 参数 |
| 1 | CNN分类模型 | units=best_units |
| 2 | epochs=best_epochs |
6.3 最优参数模型摘要信息
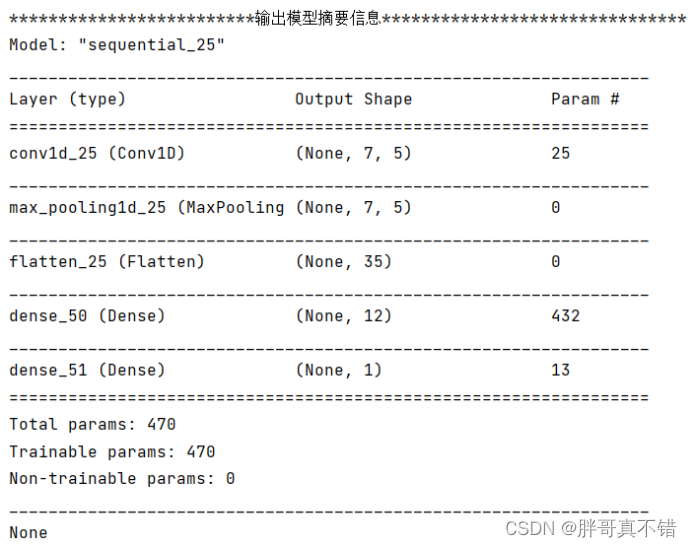
6.4 最优参数模型网络结构
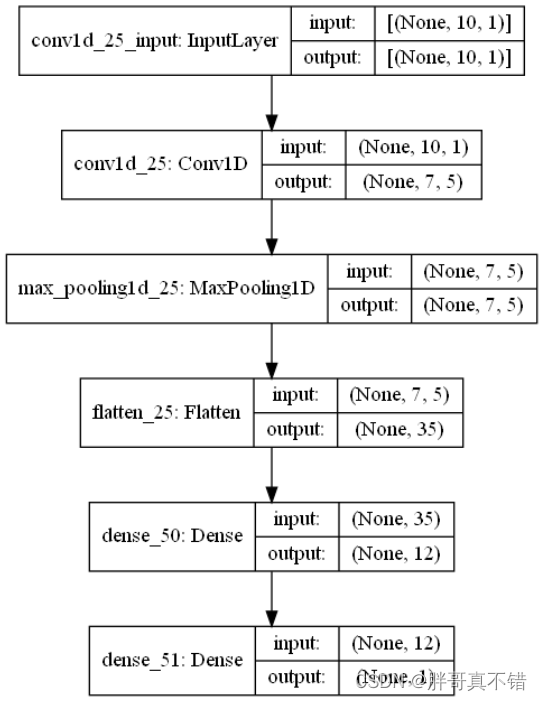
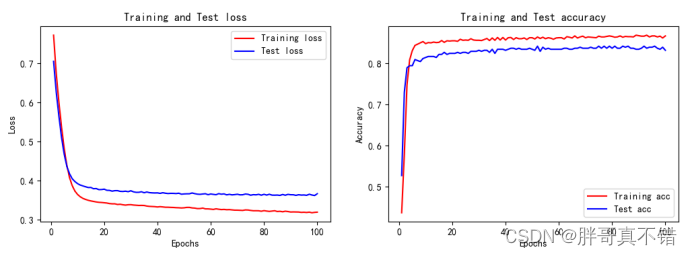
6.5 最优参数模型训练集测试集损失和准确率曲线图
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| CNN分类模型 | 准确率 | 0.8325 |
| 查准率 | 0.8626 | |
| 查全率 | 0.7889 | |
| F1分值 | 0.8241 | |
从上表可以看出,F1分值为0.8241,说明模型效果良好。
关键代码如下:

7.2 分类报告
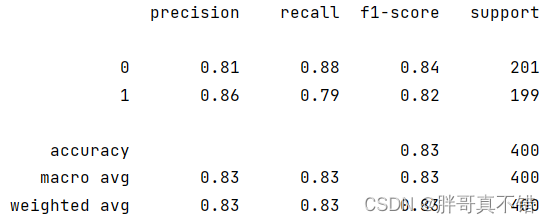
从上图可以看出,分类为0的F1分值为0.84;分类为1的F1分值为0.82。
7.3 混淆矩阵
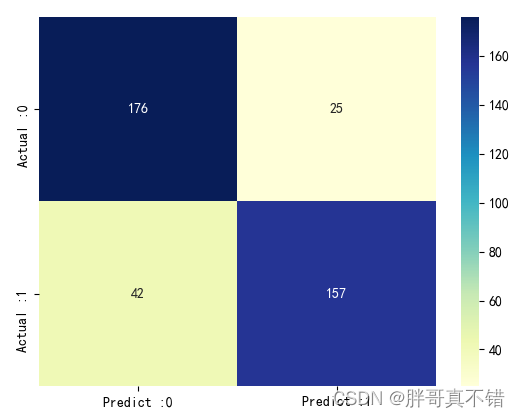
从上图可以看出,实际为0预测不为0的 有25个样本;实际为1预测不为1的 有42个样本,整体预测准确率良好。
8.结论与展望
综上所述,本文采用了BOA蝴蝶优化算法寻找CNN分类算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
# 本次机器学习项目实战所需的资料,项目资源如下:# 项目说明:# 获取方式一:# 项目实战合集导航:https://docs.qq.com/sheet/DTVd0Y2NNQUlWcmd6?tab=BB08J2# 获取方式二:链接:https://pan.baidu.com/s/1xvWJNro737r1GTtJbElvHg
提取码:1mlz这篇关于Python实现BOA蝴蝶优化算法优化卷积神经网络分类模型(CNN分类算法)项目实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





