本文主要是介绍32.网络游戏逆向分析与漏洞攻防-游戏网络通信数据解析-网络数据分析原理与依据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动!
如果看不懂、不知道现在做的什么,那就跟着做完看效果
内容参考于:易道云信息技术研究院VIP课
上一个内容:31.其它消息的实现与使用优化
这是新的一个篇章(工具终于写完了)里的第一个章,如果没有写工具直接去上一个内容里找码云把代码下载下载,然后自行编译,然后根据上一个内容里的内容配置上配置数据,或者直接使用百度网盘下载,百度网盘里的是编译好的,双击就可以用,没有任何的坑,这个工具后面要用,这可能需要一点C++语言的知识,但是不知道C++语言也没事,因为主线是逆向(分析的部分),c++是次要的,涉及c++的部分当看个乐子,也就是写代码的部分当个乐子看,逆向搞好再随便搞一两个星期C++就能全接上了
网络数据分析与逆向有很大的区别,逆向根据线索一步一步的找,它是一个每操作一步都能得到及时反馈的一个事情,而网络通信就不是这样,网络通信是可能方向错了可能找不到方向,接下来写的就是解决这个问题,分析网络的原理和依据到底是什么,也就是搞清楚分析网络数据包这件事情本质上是在做一件怎样的事情。
首先在网络通信中一定是有发送方和接收方,发送方和接收方它俩发送方发送一个数据接收方收到一个数据,想要接收方明白发送方的意思,它俩就要知道数据该怎样解读,也就是说本质上来讲,它们必须在发送和接收之前,提前知道这个数据该怎样去读或者该怎样解析,比如说可以约定好 01代表什么02代表什么,这样收到数据之后01执行对应的操作02执行对应的操作,也就是说发送方和接收方提前就有这么一套规则(编码规则),而做通信分析,做数据包分析,它的本质就是通过分析数据包,来确定它的规则。
编码解码的形式有两种:
1.数据结构约定
2.数据解析约定
首先假设下方是数据结构体:结合 数据结构约定 下面的文字看
struct chat_data{
char Id;
char Pid;
char Name[0x20];
short len;
char buff[0x100];
}
数据结构约定:
数据结构约定就是它数据组织的形式,组织的时候就有一个结构(结构体)这个结构体就是一个数据结构,但是这个数据结构我们不知道,接收方和发送方当时写代码的时候就定义在了一个头文件(头文件是写C++语言用的文件)里面,游戏用的时候就直接用了,比如一个聊天的数据 Id代表了消息序号,Pid代表聊天的频道(比如私聊还是什么)Name是目标的名字,len代表长度,buff代表说话的内容,就这样的一个结构,游戏在组织数据的时候比如id=01,Pid=02,然后内存对齐加两个00,然后目标名字是12345,然后Name有20个字节所以后面有15个0,然后就是len代表的聊天数据的长度,如下图的编码(数据包)
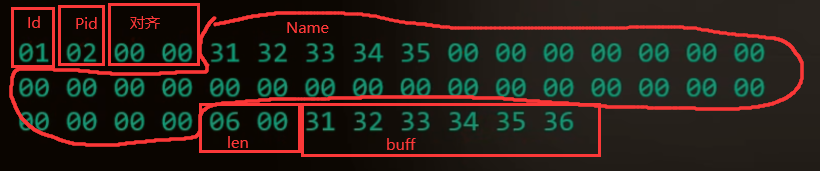
然后结构里有很多数据没有用完,所以它不可能全部发过去,这个时候就会发现,接收到的数据包就是下图的样子

然后就能通过之前写的分析工具来确定,下图红框的内容了,其它的地方的内容确定不了,通过不停的多发送,多更换目标,下图红框的内容就可以解码了,如果仔细的分析还可以发现06是字符串的长度

字符串这个东西要么末尾以0(这个0不是阿拉伯数字的0,是阿斯克码表里的0,如下图)结尾
要么就前面来个数字告诉我们字符串的长度是多少,基本来讲都是这样的情况,有时0会被处理,让它看起来像一个正常的字符,但这个东西签名的你认识后面的不认识,这样就能判断出这个字符串是以什么结尾了。
然后01和02也能通过数据包的比对就能发现它们是什么,数据包比对是一个很重要的方法,最后就通过这些数据写成上方的 chat_data 结构体,然后我们的任务也就完成了,只要有了数据结构,以后面对这样的数据,只要把它对应进去,也就能解析它的内容了,这样的话对于游戏来讲,它每一个里面每一个通信都有一个数据结构,接下来要做的就是把每一个数据结构都给解读出来,解读的越多就对它网络的控制能力也就越强,这就是基于数据结构约定。
数据解析约定或者叫数据解码约定:
首先还是一个结构体
struct chat_data2{
char Id;
char Pid;
char Name[0x20];
short len;
char buff[0x100];
}
就是没有数据结构,然后给发送的数据,它就是一段数据,比如用01代表char类型,02代表short类型,03代表bool类型,04代表int类型,05代表float类型,06代表double类型,07代表long long类型,08代表char[]类型,09代表wchar_t[]类型,这时就不用结构体来搞了,它是比如发送的是 chat_data2 这样的一个结构,然后它的数据包就是01 01 08 02 08 01 02 05 00 31 32 33 34 35 06 00 31 32 33 34 35 36,前面的 01 01 08 02 08 01代表的数据结构(01代表char、08代表char[]、02代表short),01 01 08 02 08 01后面的数据是基于 01 01 08 02 08 01来解读的,这种后面的数据基于前面的数据来解读的方式,就是解析约定,就是提前定义好怎样解,然后把解析的关键点布局图给游戏(接收方)然后根据这个布局图就能知道后面的数据该怎样读。
无非俩将就是 数据结构约定 和 数据解析约定这两种形式,也就的是混着用的,不管是哪一种,只要通过数据包分析工具确定关键内容,然后对于 数据解析约定 这种方式它的前面是不会变的,它也不能变,如果变量后面的数据会跟不上,唯一变的地方就是代表长度的地方,代表长度的地方通过数据包比对也能发现它,数据解析约定这种操作来讲其实不如数据结构约定,对于分析人员来讲,数据结构约定,需要把所有的数据结构都解出来,数据解码约定只要把解码规则搞明白,虽然解码规则没有那么好搞,但实际上也没有那么难搞,还是能够得到的,得到之后整个网络的系统解析就被掌握住了,所以在实际的开发中要用数据结构约定这种方式,后面就开始分析靶场(如果想用靶场需要花钱,自行联系易道云信息技术研究院,如果实在找不到易道云信息技术研究院联系方式可以私聊我)这个程序它是用的什么约定,首先要切入的点就是登陆的环节

这篇关于32.网络游戏逆向分析与漏洞攻防-游戏网络通信数据解析-网络数据分析原理与依据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





