本文主要是介绍Transformer的前世今生 day05(Self-Attention、,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Self-Attention
前情提要
- 注意力机制:我们在看一幅图的时候,不会去看它的所有信息,相反我们倾向于看一些重点,并把我们的焦点放到这些重要信息上,过程如下:
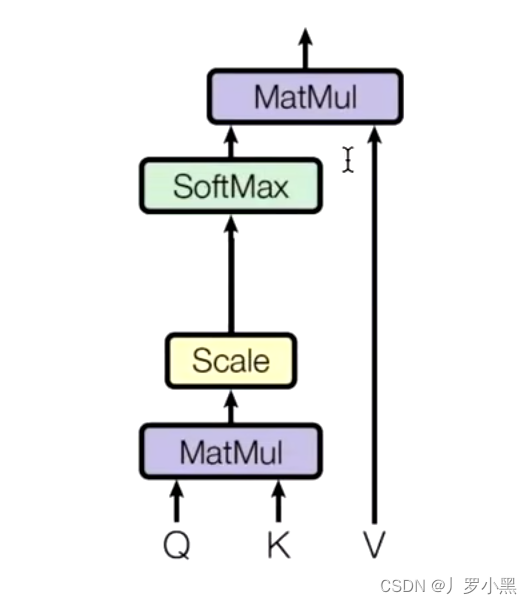
- 首先:Q、K相乘求相似度,并做一个Scale缩放(避免未来做softmax的时候出现极端情况),然后通过softmax得到概率,并与V做乘加操作得到新的V’,这个V‘包含了原本的Q中跟K很相似,很重要的信息,也就是新的V’包含了注意力信息
自注意力机制
- Selft-Attention的关键点在于: X K X_K XK ≈ \approx ≈ X V X_V XV ≈ \approx ≈ X Q X_Q XQ,这三者同源,都来自于同一个输入X
- 步骤如下:
- 通过 W Q W^Q WQ、 W K W^K WK、 W V W^V WV三个矩阵来获取 X K X_K XK ≈ \approx ≈ X V X_V XV ≈ \approx ≈ X Q X_Q XQ:
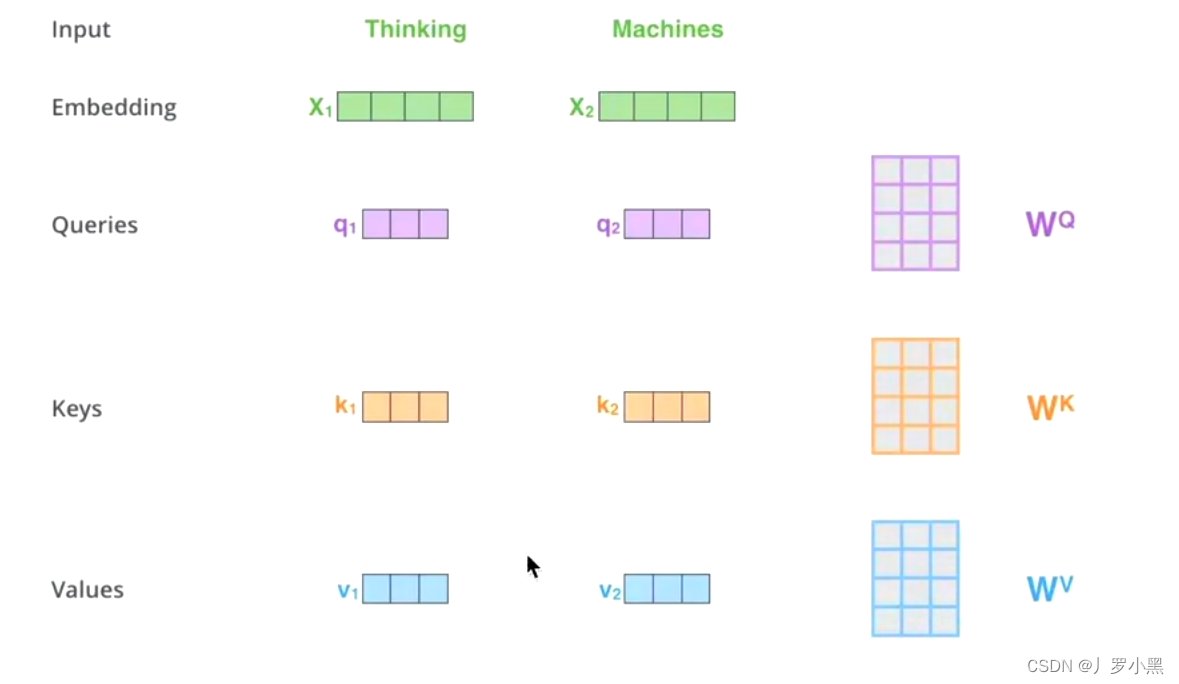
- 通过 W Q W^Q WQ、 W K W^K WK、 W V W^V WV三个矩阵来获取 X K X_K XK ≈ \approx ≈ X V X_V XV ≈ \approx ≈ X Q X_Q XQ:
- 之后的步骤和注意力机制一样
- q 1 q_1 q1和 k 1 k_1 k1点乘, q 1 q_1 q1和 k 2 k_2 k2点乘得到相似度s
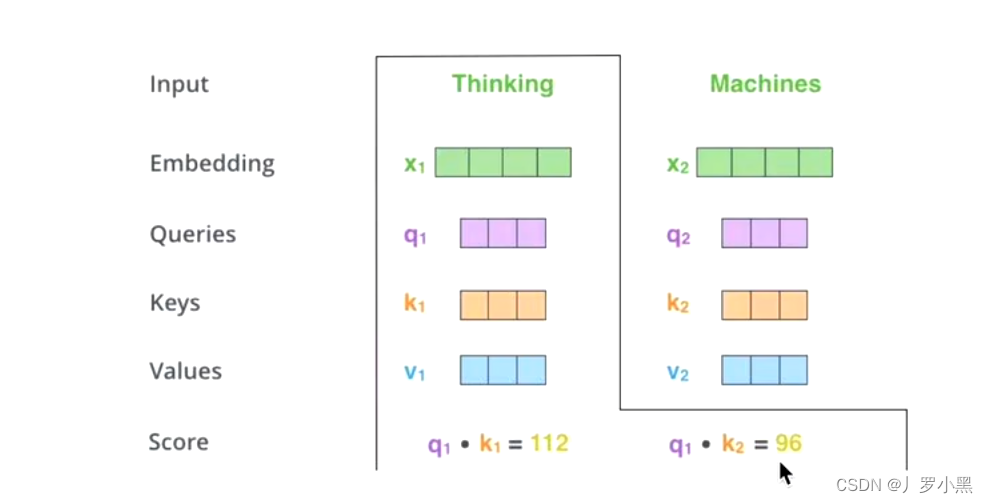
- 先做一个scale缩放,除 d k \sqrt{d_k} dk,再做softmax得到概率a
- 注意:由于 x 1 x_1 x1:Thinking和它本身显然要比和 x 2 x_2 x2:Machines更为相似,所以得到的概率也就更大
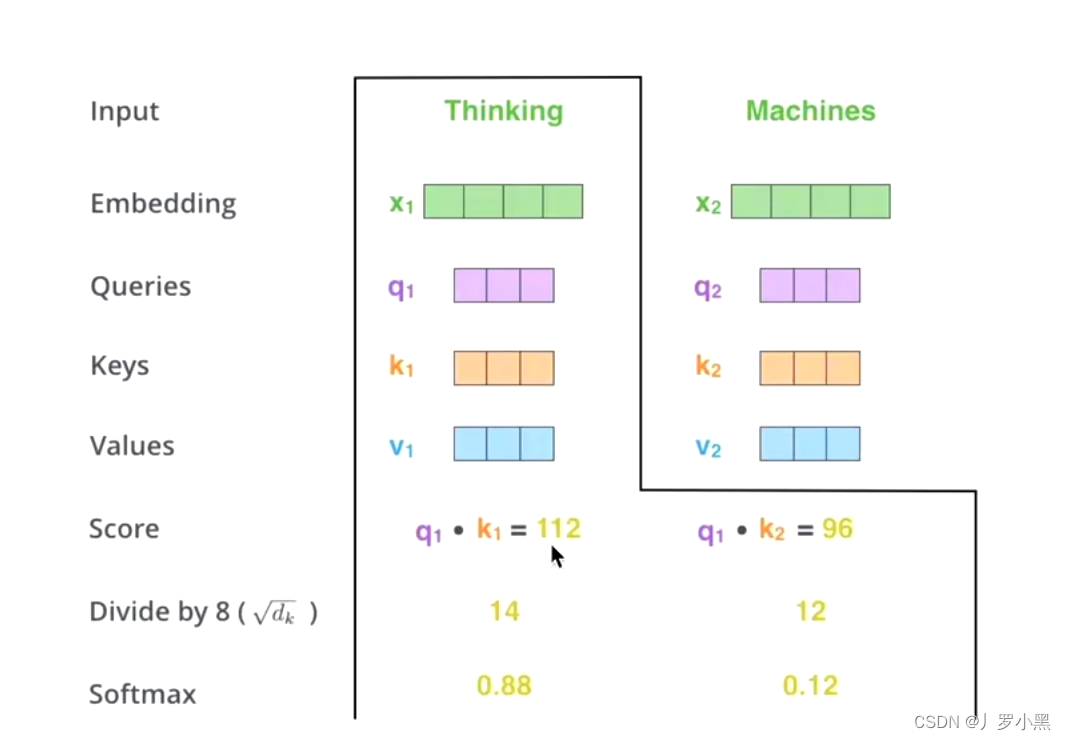
- 注意:由于 x 1 x_1 x1:Thinking和它本身显然要比和 x 2 x_2 x2:Machines更为相似,所以得到的概率也就更大
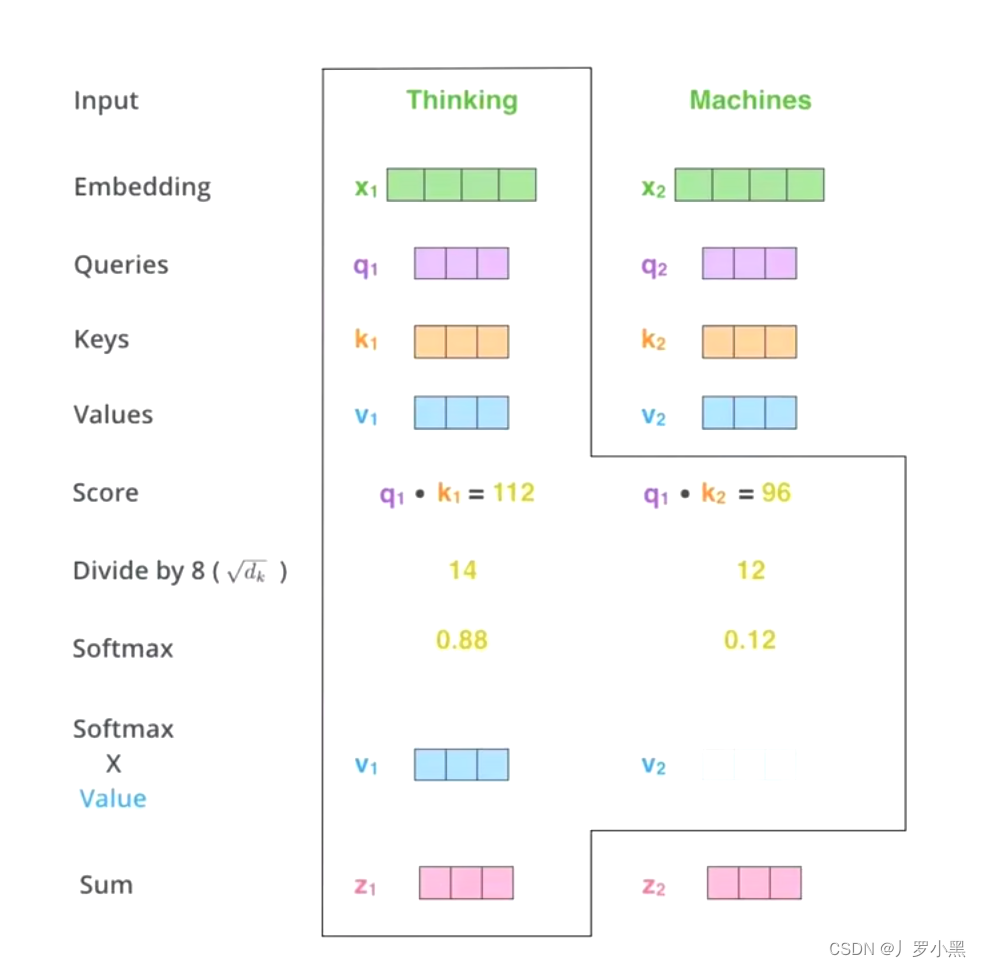
- 最后,将 q 1 q_1 q1中和每个K点乘得到的的概率,和V相乘,并求总和,得到 z 1 z_1 z1
- 而 z 1 z_1 z1就是Thinking这个输入的新的V’,且包含了每一个单词和Thinking的相似度,包括Thinking本身。
- 换句话说:如果我们的输入 x 1 x_1 x1为Thinking的初始词向量,那么我们通过Self-Attention得到的 Z 1 Z_1 Z1仍然是Thinking的词向量,只不过这个词向量包含了Thinking Machines这句话中的每个词跟Thinking的相似度
- 使用Self-Attention的示例如下:
- 由于its和law、application相似,所以使用Self-Attention后得到的its词向量,会包含一定的law、application信息,即包含了一定的全局关系。
- 而如果不做自注意力机制,its的词向量就是单纯的its,没有任何的附加信息

参考文献
- 10 Self-Attention(自注意力机制)
这篇关于Transformer的前世今生 day05(Self-Attention、的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!