本文主要是介绍从零对Transformer的理解(台大李宏毅),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
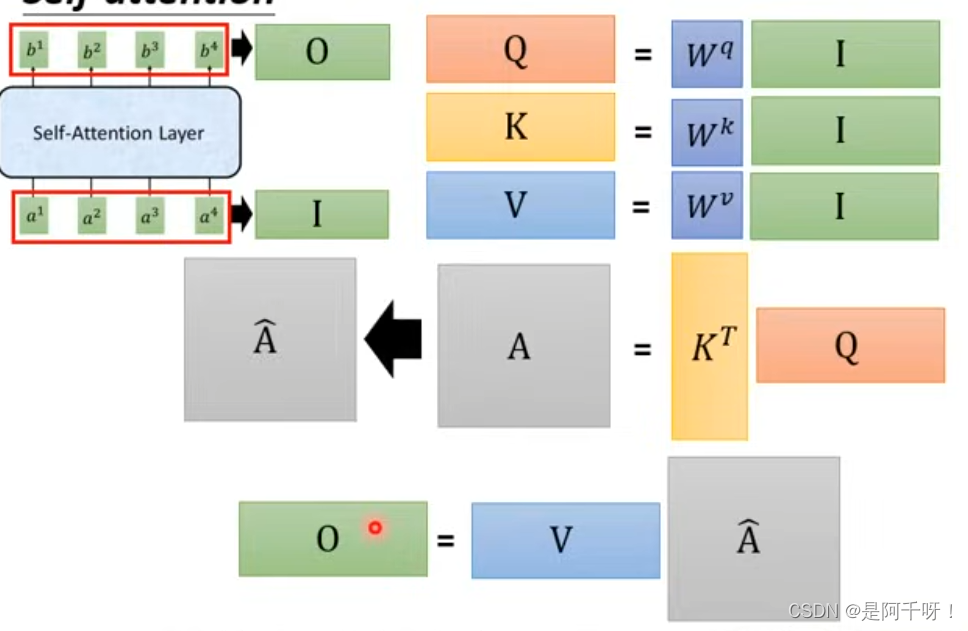
Self-attention layer自注意力
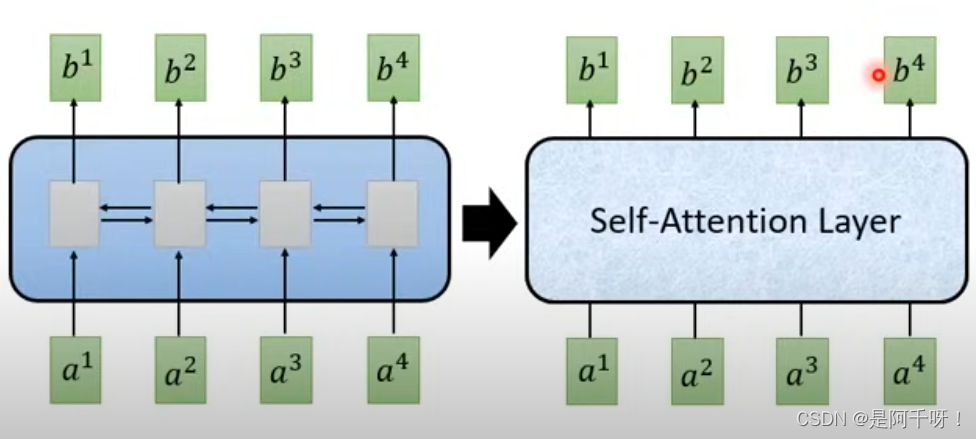 对比与传统cnn和rnn,都是需要t-1时刻的状态然后得到t时刻的状态。我不知道这样理解对不对,反正从代码上看我是这么认为的。而transformer的子注意力机制是在同一时刻产生。意思就是输入一个时间序列,在计算完权重后就直接得到状态。
对比与传统cnn和rnn,都是需要t-1时刻的状态然后得到t时刻的状态。我不知道这样理解对不对,反正从代码上看我是这么认为的。而transformer的子注意力机制是在同一时刻产生。意思就是输入一个时间序列,在计算完权重后就直接得到状态。
计算注意力机制的参数q,k,v
那么相信大家肯定看不懂上面的,接下来我来说说a(1,n)怎么计算(如图):

也就是q1 * kn(n=1,2,3,4)
但是相信大家疑惑的是为什么要除以根号d?
很简单因为k和q的维度一样 但是k的行数越多(听不懂就理解k的变量越多)那么和q分别相加相乘后会导致变量变得很大,这个除以维度根号d也就是启平衡的作用。
接下来是进行和特征v相乘

看图可以知道 我们要输出的第一sequence的第一个向量是b1 ,但是我们是如何得到的呢,很简单,将我们上一步得到的a(1,n) *v[n]。看着很眼熟,是不是可以把它变成矩阵相乘类型。那这些有什么意义? 你看我们生成b1的时候我们考虑道路a1~a4所有的特征,并且假如我们不想考虑a1的特征的时候,我们只需要
如何把它变成矩阵相乘从而加速?
如图 将上述的乘法变成矩阵相乘
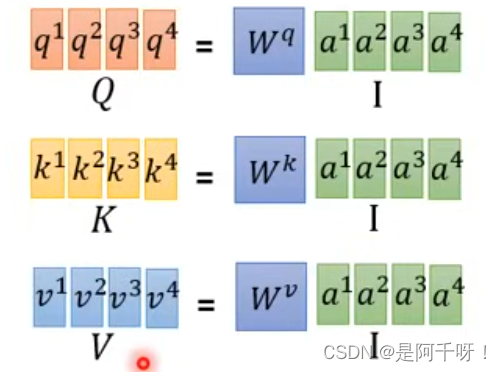
那么我们可能不懂这个W是干什么的?这个就是相对的特征参数。打个比方就是比如一个蛋糕怎么给三个人分,每个人分多少,也就是权重。
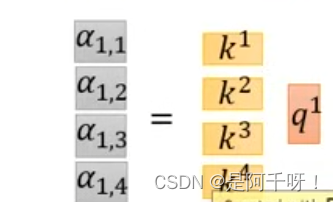
ok。理解之后我们开始做乘法,一开始我们是要用同q1乘以k1~k4得到a(1,n) ,如下图
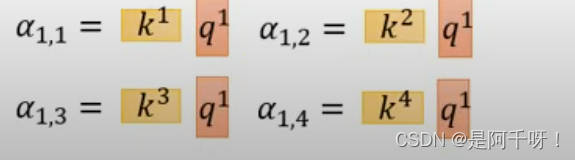
那么我们是不是可以这样
那么我们继续推导,假如我们要得到a(2,n),a(3,n)呢?是不是可以加q2,q3?然后对A矩阵进行softmax。
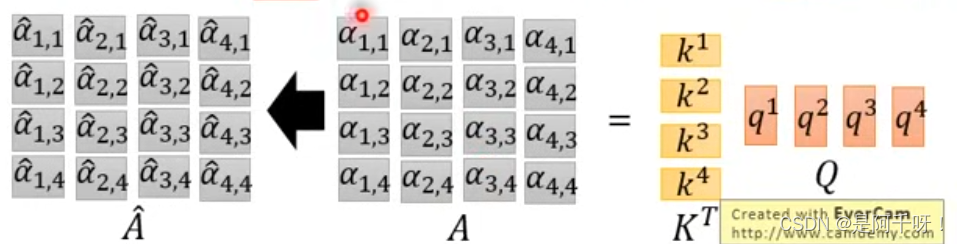
那么我要得到最后的b1~b4怎么做?是不是只需要做一个简单的行列相乘就行了。

那么我们总体可以得到

多头注意力机制
ok上面我们懂了什么是自注意力,那么这里我们来了解一下什么是多头?
很简单,多头就是多个特征头,我们以两个头为例子,我们的q,k,v特征可以不仅仅是一个维度,可以是多维度,那么多个维度,我们用两个头来举例,q(n,1),q(n,2) n=(1,2,3,4)。但是我们相乘的话不能交叉?什么意思呢?打个比方,我们和某个人进行比较,我们不能拿我们体重的数据去对比人家的身高数据,这样做的意义不大。所以这里的q,k,v分出的头相乘还是只能跟自注意力机制一样q(n,1)*k(n,1),q(n,2)*k(n,2)这样进行(当然这里是矩阵相乘意思到位就行)。如图
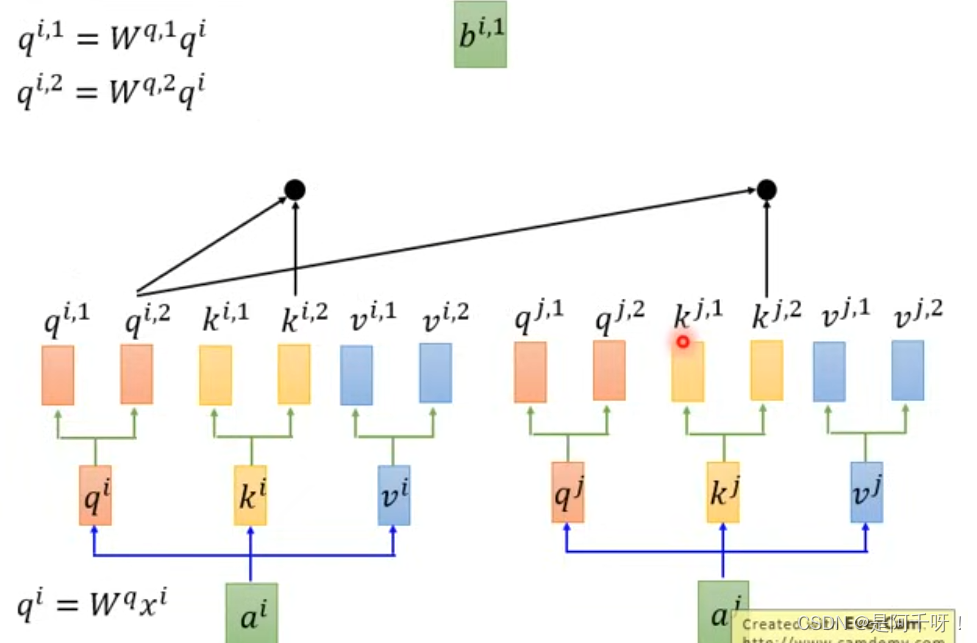
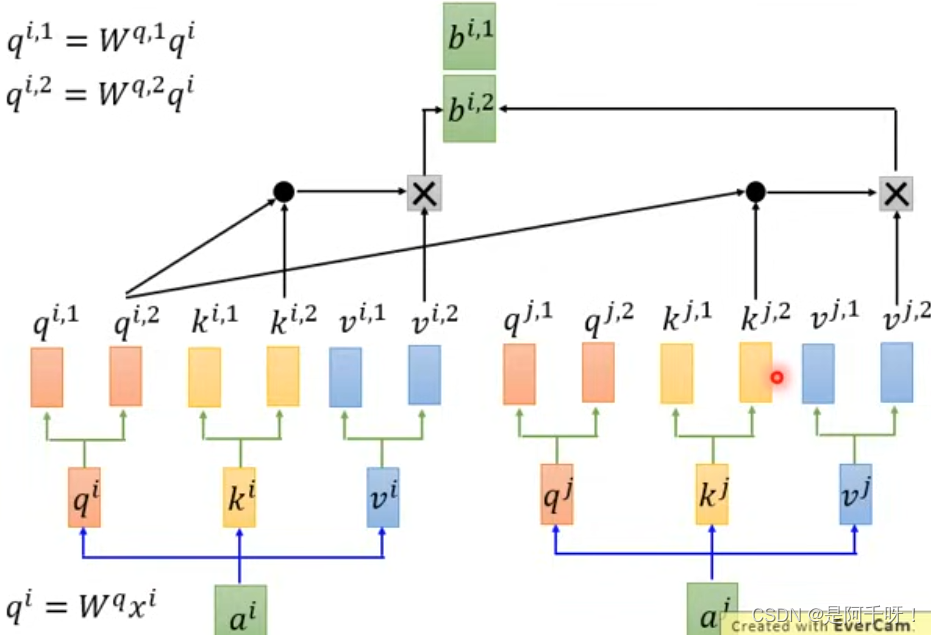
但是最后我们得到两个sequence之后呢,我们并不是简单的相加,我们也可以进行降维,这是什么意思呢?举个例子就是两个不同的男孩子去追同一个女孩,一个男孩子就喜欢关注女孩的外表从而得出女孩的特征,还一个男孩子就喜欢关注女孩子的内在而得到特征。所以我们的任务是调整这两个特征的权重,而达到我们预期效果。如图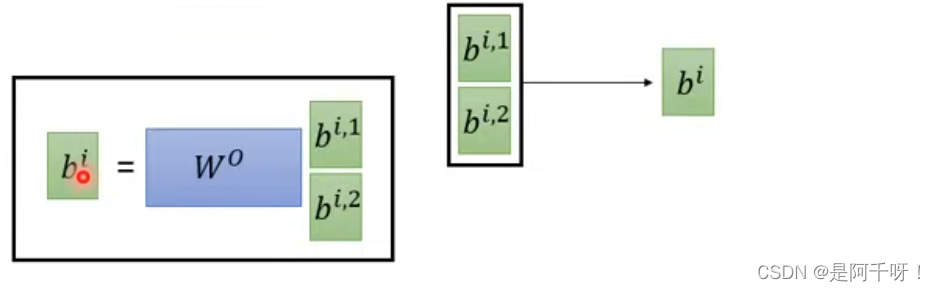
位置编码
其实我们仔细观察前面讲的自注意力 的时候发现了一个问题,就是说我们无论输入的序列怎么颠倒,但是我们获得的信息是一样的?为什么?因为我们对不同的q,k,v权重里面获得了固定的信息。不跟传统rnn一样需要上一个时刻的信息。那么这里我们提到了位置编码?
什么是位置编码?为什么要位置编码?
打个比方,我们清楚一件事,就是一个句子的主谓宾很重要,比如我爱你和你爱我完全两个意思,在你追女孩的时候你更想听到你爱我而不是我爱你。所以我们需要对我们输入的向量的对应位置进行编码,论文做法就是加位置编码e[n]。

还一个问题,为什么是加而不是concat?
我们加的话不会导致它的特征混淆找不到吗?
这里我们给出解释:
我们假设有一个one-hot编码向量p(i),不知道one-hot的可以自己去学一下
p(i)的i代表着第i维是1其他维度是零。这里我们把p(i),因为e(i)是位置编码,我们可以用one-hot编码来表示词的位置。接着我们将其concat后与权重W相乘得到我们对应的q,k,v。如下图
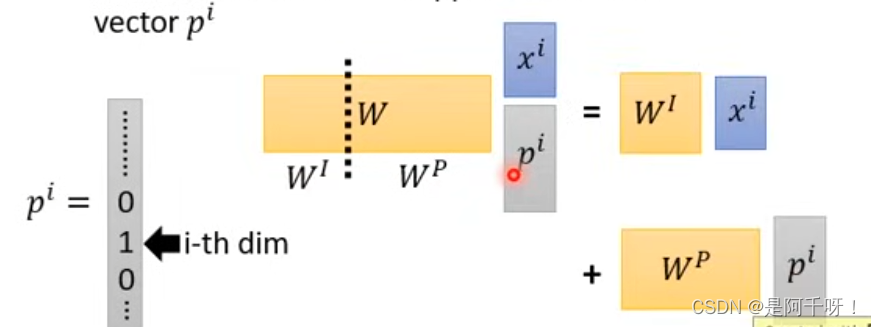
学过线性代数的我们可以把w堪称wi和wp分别和我们的xi和pi矩阵进行相乘,然后相加。所以相加和concat效果是一样的。但是concat增加了维度,反而会影响训练速度,所以我们选择相加来提高训练速度,不必要做无谓的空间浪费。
Encoder层
我们的编码层做的事情肯定是编码了。

1.看上这个结构是不是不懂? 不懂就对了。我们来仔细讲讲,首先是Input这里
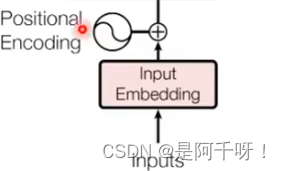
这里我们之前讲过的position编号起到作用,意思是我们输入进去的序列需要加上位置信息(也可以成为语序信息)。
2.然后是到多头注意力和残差结构和Norm计算这里我们之前说过了多头注意力这里就不多提
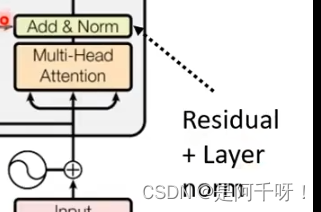
然后Residual层是残差层,然后norm层是进行序列的计算。具体做法就是求出一个序列的平均然后除以标准差如下图。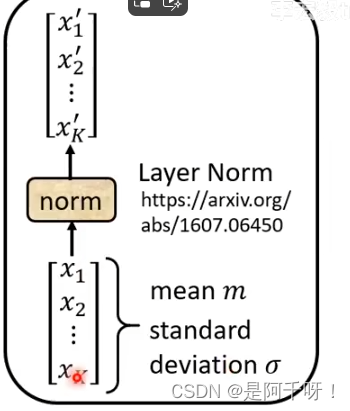
做完这些后再进入全连接层后再进行norm和残差就得到我们的一个block的处理。但实际我们有N个encoder叠加进行的,这也是N的意思。

Decoder层
我们得到Encoder的输出后,再输入到Decoder层作为输入
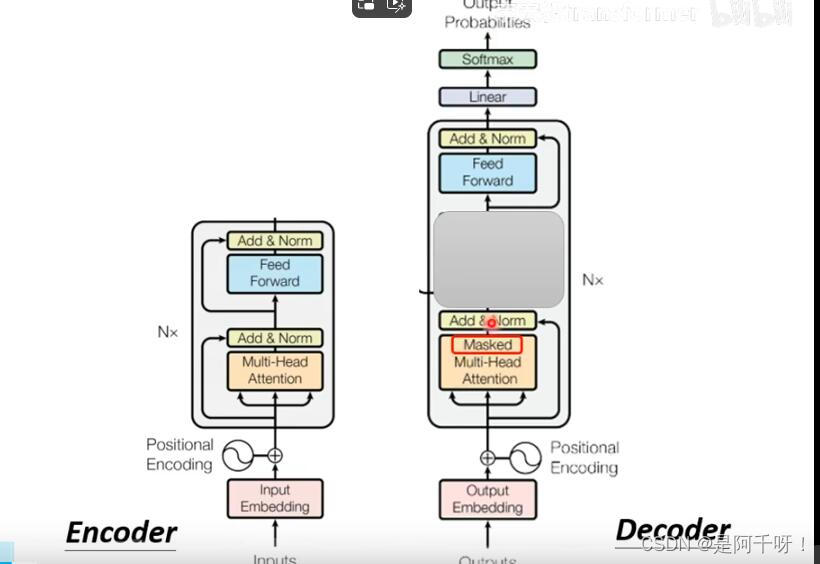
我们看其实发现我们的Decoder层和我们的Encoder层在主题上差不多(在遮住中间的部分的时候)
但是我们发现有个不同的地方(除去中间遮住的部分),那就是Masked。那我们仔细看看它做了什么
Decoder的功能(以一个序列为例子)
我们看到“机器学习”这四个字,我们Masked做了什么呢?在我们的自注意力机制上面,我们知道我们假如要从输入a1得到b1 那么我们会其他a2-an的qkv进行自注意力计算然后在输出b1,但是我们的Masked却只是计算a1一个人的qkv特征得到b1,b2也只能用a1和a2的特征进行计算得到。一句话就是只能看左边,并且得到的输出会变成下一个词的输入。可能大家还是不懂,看下面的图。
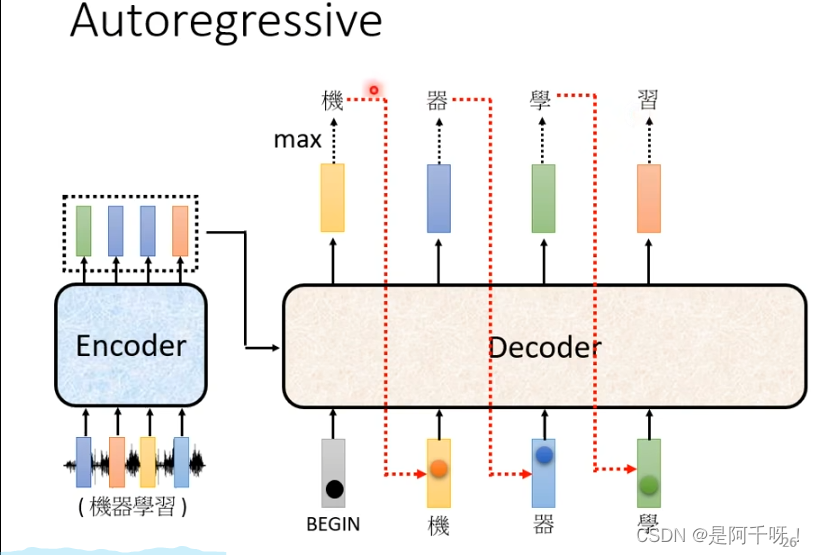
我们得到机的时候是通过begin得到的(这里说一下,因为我们一个序列要一直做,所以我们会增加begin和end标签),那么我们得到机的时候又把机作为输入得到“器”,但是这个时候的“机”字却包含了之前的begin,以此类推,感觉这个类似rnn。
下面这两张图是对比自注意力和Masked自注意力区别,第一张为自注意力,第二张为Masked自注意力
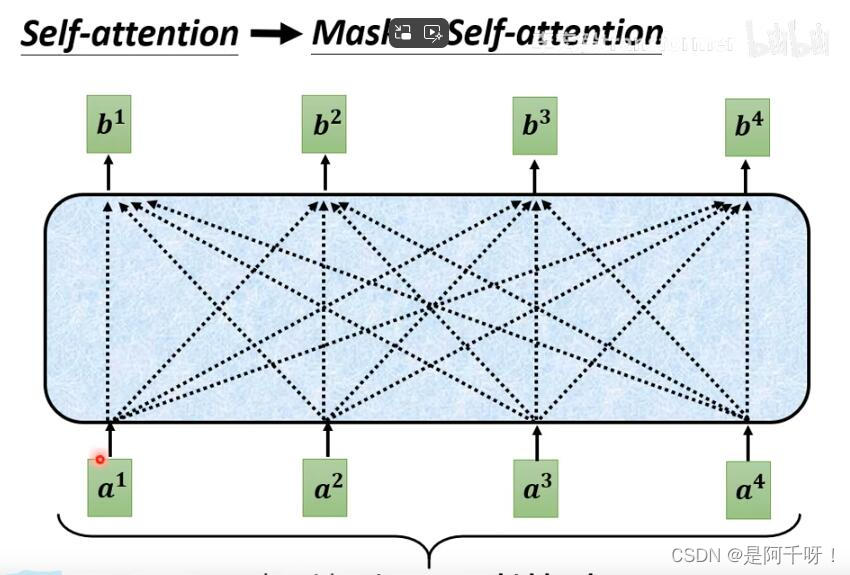
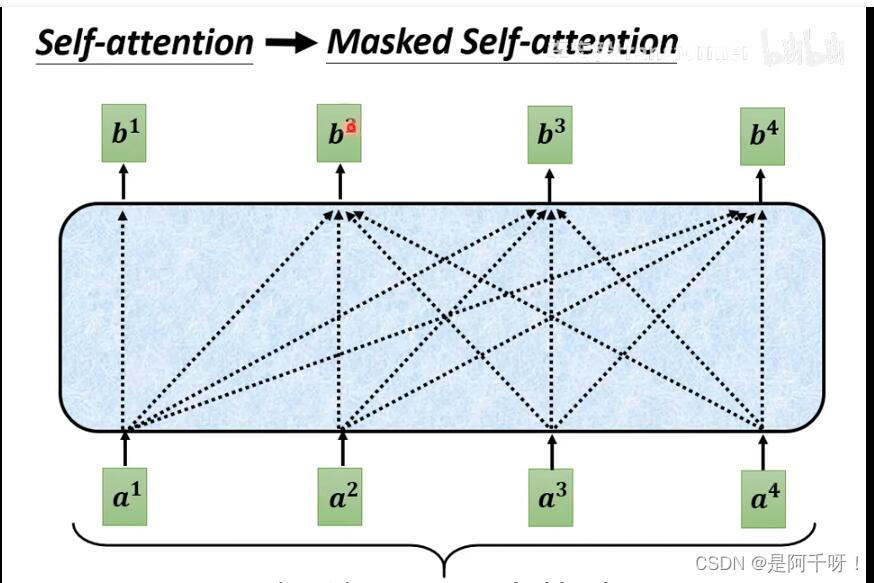
那么中间的部分是什么?
CrossAtention!
它的目的很简单就是把encoder的输出和我们decoder的Masked那一层的输出结合进行crossatention后得到我们的结果。
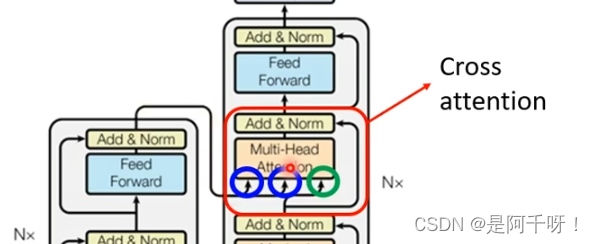
具体是这样,从encoder的一个block中获得特征和decoder的Masked提取的特征进行自注意力机制的运算

最后说一下训练的时候和验证的时候用的损失函数
训练的时候用的交叉熵(也就是一个一个的单词对比),测试的时候用的是bule score 也就是生成的句子和测试的句子之前的对比得分。为什么不在训练的时候用bule score呢?因为不知道怎么用。


这篇关于从零对Transformer的理解(台大李宏毅)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





