本文主要是介绍回归预测 | Matlab实现GSWOA-KELM混合策略改进的鲸鱼优化算法优化核极限学习机的数据回归预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
回归预测 | Matlab实现GSWOA-KELM混合策略改进的鲸鱼优化算法优化核极限学习机的数据回归预测
目录
- 回归预测 | Matlab实现GSWOA-KELM混合策略改进的鲸鱼优化算法优化核极限学习机的数据回归预测
- 效果一览
- 基本介绍
- 程序设计
- 参考资料
效果一览
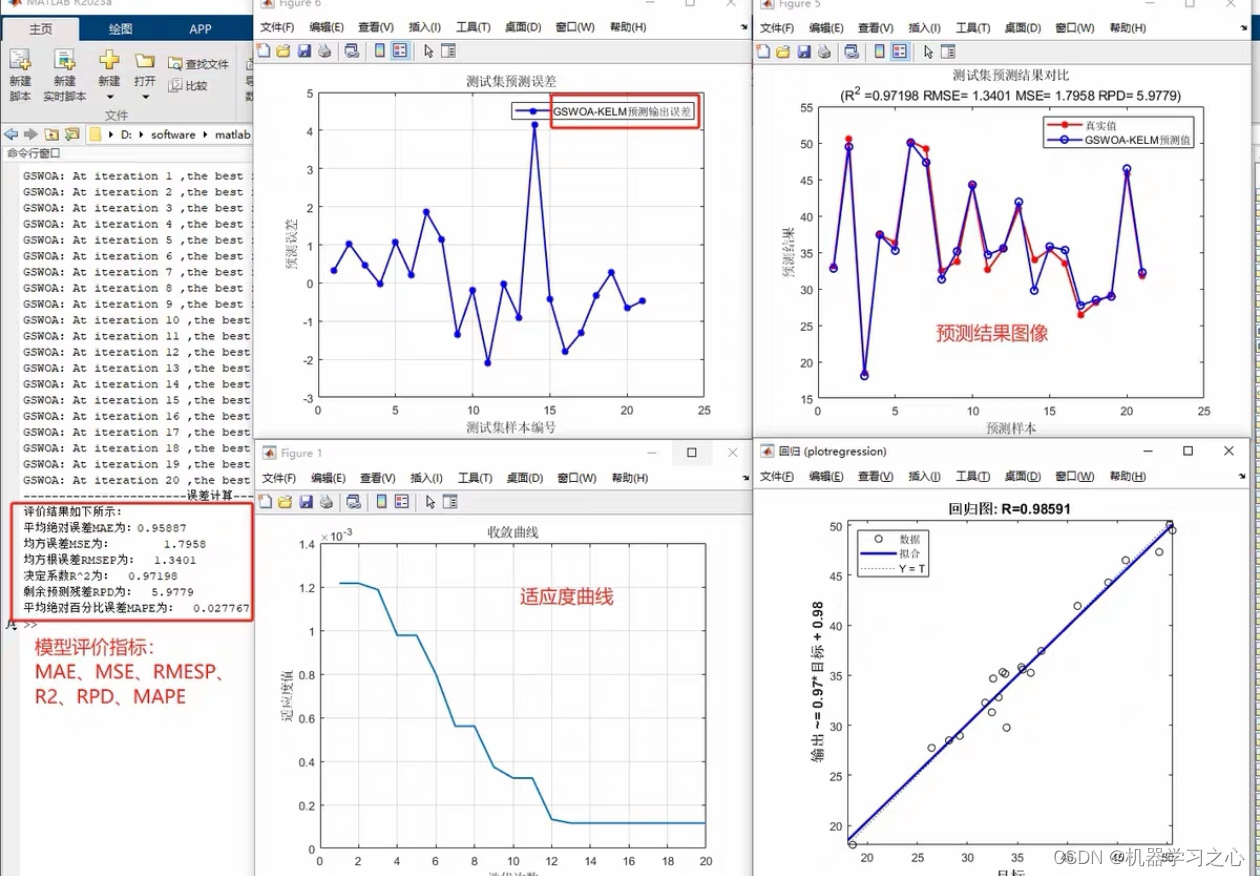
基本介绍
GSWOA-KELM多变量回归预测
基于三种策略改进的鲸鱼优化算法(GSWOA)优化核极限学习机(KELM)的数据回归预测模型
通过改进鲸鱼算法优化KELM的两个参数,避免了人工选取参数的主观盲目,有效提高预测精度。用的人还很少~
WOA改进点如下:
1.在鲸鱼位置更新公式中加入自适应权重,动态调节最优位置的影响力,改善算法收敛速度
2.使用变螺旋位置更新策略,动态调整螺旋的形状,提升算法全局搜寻能力
3.引入最优邻域扰动策略,避免算法陷入局部最优解,解决算法早熟现象。
直接替换数据即可用 适合新手小白~
附赠案例数据 可直接运行
程序设计
- 完整程序和数据资源私信博主回复Matlab实现GSWOA-KELM混合策略改进的鲸鱼优化算法优化核极限学习机的数据回归预测。
function Y = elmpredict(p_test, IW, B, LW, TF, TYPE)%% 计算隐层输出
Q = size(p_test, 2);
BiasMatrix = repmat(B, 1, Q);
tempH = IW * p_test + BiasMatrix;%% 选择激活函数
switch TFcase 'sig'H = 1 ./ (1 + exp(-tempH));case 'hardlim'H = hardlim(tempH);
end%% 计算输出
Y = (H' * LW)';%% 转化分类模式
if TYPE == 1temp_Y = zeros(size(Y));for i = 1:size(Y, 2)[~, index] = max(Y(:, i));temp_Y(index, i) = 1;endY = vec2ind(temp_Y);
endend
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/124864369
[2] https://blog.csdn.net/kjm13182345320/article/details/127896974?spm=1001.2014.3001.5502
这篇关于回归预测 | Matlab实现GSWOA-KELM混合策略改进的鲸鱼优化算法优化核极限学习机的数据回归预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





