本文主要是介绍FOTS: Fast Oriented Text Spotting with a Unified Network-译文,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
偶然场景文本定位被认为是文献分析社区中最难最具挑战性的任务之一。大多数存在的方法将文本检测和识别看作分开的任务。在本文工作中,我们提出了一个统一的端对端训练的快速多方向文本定位网络同时检测和识别,在两个任务中共享计算和视觉信息。特殊的,引入RoIRotate来在检测和识别之间共享卷积特征。受益于卷积共享策略,我们的FOTS几乎没有比基础文本检测网络增加计算量,联合训练方法学习更通用的特征使得我们的方法优于那些两步的方法。在ICDAR2015、ICDAR2017MLT和ICDAR2013数据集上进行实验,提出的方法显著优于现在最好的方法,这进一步允许我们开发第一个实时多方向文本检测系统,在ICDAR2015文本定位任务上超过之前最好的结果多于5%,同时保持22.6fps。
- 引言
由于它在文献分析、场景理解、机器人导航和图片检索中的许多的实际应用,理解自然图像中的文本在计算机视觉社区已经越来越受到关注。尽管之前的工作在文本检测和文本识别都取得了重大的进步,但是由于文本形式的巨大变化和高复杂度的背景导致它仍是极具挑战性。
场景文本理解的最通用的方式是将其分为文本检测和文本识别,处理2个分开的任务。基于深度学习的方法在两部分都成为了主流。在文本检测中,通常卷积神经网络用来从场景图片提取特征map,然后用不同的解码器解码区域。在文本识别中,对于序列预测的网络是在文本区域上进行的,一个一个操作。对于有很多个文本区域的图片就会导致严重的时间消耗。另外一个问题是忽略了在检测和识别共享的视觉线索的相关性。

在本文中,我们提出同时考虑文本检测和识别。可以端对端训练的FOTS。和之前的两步文本定位对比,我们的方法通过卷积神经网络学习了更通用的特征,在文本检测和文本识别之间共享,两个任务之间的监督是互补的。因为特征提取通常需要更多的时间,它缩小了计算到一个单一的检测网络,如图1所示。连接检测和识别的关键是ROIRotate,它根据带方向的检测边界框来从特征map中获取合适的特征。

结构如图2所示。首先用共享卷积提取特征map。基于FCN的文本检测分支是在特征图上来预测检测边界框。ROIRotate操作从特征map中提取对应检测结果的文本候选特征。文本候选特征再输入到文本识别的RNN编码器和CTC解码器。由于网络中所有的模块都是可微的,所以整个系统是可以进行端对端的训练。据我们所知,这是第一个针对多方向文本检测和识别的端对端训练的网络框架。我们发现网络可以很容易训练,不需要复杂的后处理和超参数调试。
本文贡献总结如下:
我们针对快速多方向文本定位提出了端对端的训练框架。通过共享卷积特征,网络可以在几乎不增加计算量的同时检测和识别文本,这可以实现实时要求。
我们引入 了RoIRotate,一种新的可微操作来从特征map中提取多方向文本区域。这个操作是文本检测和识别统一为一个端对端的算法流程。
没有铃声 和哨子,FOTS在多个文本检测和文本识别数据集上,包括ICDAR2015,ICDAR2017 MLT和ICDAR2013上都显著优于目前最好的方法。
2、相关工作
文本识别在计算机视觉和文献分析领域是一大活跃课题。在本不放呢,我们简单介绍相关工作,包括文本检测、文本识别和将二者组合在一起的文本识别。
2.1、文本定位
文本检测的大多数传统方法是将文本看作字符的组合。这些基于字符的方法首先需要定位一张图中的字符,然后将它们组合成单词或文本行。基于滑窗的方法和基于连通域的方法是传统方法中的两个表达范畴。
近些年,很多基于深度学习的方法被提出来直接用于图像中检测单词,Tian等人[49]采用了垂直anchor机制来预测固定宽度的proposals然后将它们连在一起。Ma等人[39]通过提出Rotation RPN和Rotation RoI pooling,引入了一种针对任意方向文本的新型基于旋转的框架。Shi等人[43]首次预测文本分割,然后用连接预测结果将其连接为完整的实例。在稠密预测和一步后处理基础上,Zhou等人[53]和He等人[15] 针对多方向场景文本检测提出深度直接回归方法。
2.2、文本识别
一般来说,场景文本识别旨在解码来自正常裁剪但长度可变的文本图片的标签序列。大多数先前的方法是捕获独立的字符,之后再细化分错的字符。除字符级别的方法之外,近期的文本区域识别方法可以分为三大类:基于单词分类、基于序列-标签解码的方法和基于序列-序列的方法。
Jaderberg等人[19]提出将单词识别问题看作是一个传统的多分类任务,有巨大的分类标签(大约90k 单词)。Su等人[48]将文本识别看作为序列标定问题,用HOG特征构建RNN采用CTC作为解码器。Shi等人[44]和He等人[14]提出深度循环模型来编码最大输出CNN特征以及采用CTC解码编码序列。Fujii等人[5]提出一种编码器和总结器网络来为CTC提供输入序列。Lee等人[31]用基于attention机制的序列-序列的结构自动聚焦提出的CNN特征上,并隐含的学习包含在RNN中的字符级别的语言模型。为了处理不规则输入图片,Shi等人[45]和Liu等人[37]引入了空间注意力机制来转换一个乱序的文本区域到一个合适识别的标准状态。
2.3、文本定位识别
多数之前的文本定位识别方法首先用文本检测模型生成文本proposals,然后用一个独立的文本识别模型来识别它们。Jaderberg等人[20]首先用一个高的召回率的模型来生成所有的文本proposals,然后用一个单词分类器来进行单词识别。Gupta等人[10]针对文本检测训练了一个全卷积回归网络,针对文本识别采用单词分类器[19]。Liao等人[34]用基于SSD[36]的方法进行文本检测,用CRNN进行识别。
最近Li等人提出端对端的文本定位识别方法,受RPN[41]启发用一个文本proposal网络进行文本检测,用带有attention机制的LSTM来进行文本识别。我们的方法和它们对比主要有两个优势:(1)我们引入了RoIRotate,用完全不同的文本检测算法来解决更加复杂和困难的情况,但他们的方法只适用于水平方向的文本。(2)我们的方法在速度和效果上都比他们的方法好很多,尤其是几乎不耗时的文本识别部分使得我们的文本定位识别系统可以有一个实时的速度,而他们的方法处理一张600*800大小的输入图像大概需要900ms。
3、方法论
FOTS是一个端对端训练的框架,同时检测和识别一张自然场景图片中的所有单词。它包括4部分:共享卷积,文本检测分支,RoIRotate操作和文本识别分支。
3.1、整理概览

我们框架的概览如图2所示。文本检测分支和识别分支共享卷积特征,共享网络的结构如图3所示。共享网络的基础网络是ResNet-50[12]。受FPN[35]启发,我们将低级特征图和高级语义特征图拼接。共享卷积的特征图分辨率为输入图像的1/4。检测分支产生多方向的文本区域proposals,然后提出的RoIRatate将对应的共享特征转为固定高度的表达同时保持原始高宽比。最后,文本识别分支识别区域proposals的单词。采用CNN和LSTM来编码文本序列信息,接着是CTC解码器。我们的文本识别分支的结构如表1所示。

3.2、文本检测分支
受[53,15]启发,我们采用一个全卷积网络作为文本检测器。由于在自然场景图像中有很多小的文本框,所以我们在共享卷积中将feature map从原始输入图像的1/32扩大至1/4。提取共享特征后,用了一层卷积来输出单词稠密每个像素点的预测。第一个通道计算每个像素是一个正样本的概率。和[53(EAST)]类似,正样本是原始文本区域收缩后的像素点。对于每个正样本,接下来的4个通道预测它到包含这个像素点的边界框的上、下、左、右边的距离,最后一个通道预测对应边界框的方向。最后的检测结果是通过对这些正样本进行阈值过滤和NMS得到的。
在我们的实验中,我们观察到很多类似文本笔画的很难分类,例如栅栏、格子等。我们采用在线难样本挖掘(OHEM)来更好的区分这些情况,同时也可以解决样本不均衡问题。这使得在ICDAR2015数据集上的F-score提升了大约2%。
检测分支的loss函数包括两部分:文本分类项和边界框回归项。文本分类项可以看作是一个下采样的分数map的像素分类loss。只有原始文本区域的收缩版本才被认为是正样本区域,同时在边界框和收缩版本之间的区域看作为“NOT CARE”,不参与分类的loss。注意在score map中通过OHEM选择的正样本元素的集合表示为![]() ,分类的loss函数的公式表示为如下:
,分类的loss函数的公式表示为如下:

这里![]() 是集合中的元素个数,
是集合中的元素个数,![]() 表示score map预测值
表示score map预测值![]() 和表示文本或非文本的二值标签
和表示文本或非文本的二值标签![]() 之间的交叉熵。
之间的交叉熵。
至于回归loss,我们采用[52]中的IoU loss,在[53]中的旋转角度loss,因为它们对目标的形状、大小和方向的变化都具有鲁棒性:
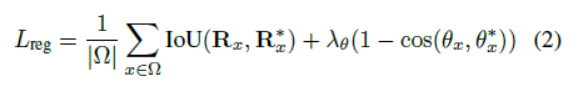
这里,![]() 是预测边界框
是预测边界框![]() 和ground truth
和ground truth ![]() 之间的IoU loss。第二项是旋转角度loss,这里
之间的IoU loss。第二项是旋转角度loss,这里![]() 分别表示预测角度和ground truth角度。在实验中我们将超参数
分别表示预测角度和ground truth角度。在实验中我们将超参数![]() 设为10。
设为10。
所以检测的整体loss可以写成:
![]()
这里超参数![]() 是平衡两个loss的,在我们的实验中设为1。
是平衡两个loss的,在我们的实验中设为1。
3.3、RoIRotate
RoIRotate在有方向的特征区域使用转换,获得轴方向对齐的特征map,如图4所示。在该工作中,我们固定输出的高度,并且保持宽高比不变,来处理变长文本。和RoI pooling[6]及RoIAlign[11]比较,RoIRotate为提取感兴趣区域的特征提供更一般的操作。我们也对比了在RRPN[39]中提出的RRoI pooling。RRoI pooling将旋转区域通过max-pooling转换到一个固定大小的区域,而我们用双线性插值来计算输出值。这个操作避免了RoI和提取特征之间的未对齐,额外它还使输出特征的长度可变,这对于文本识别更适用。

这个过程被分为两步。首先,通过预测的或ground truth的文本proposals的坐标来计算仿射变换的参数。然后,对每个区域分别使用这些仿射变换到共享特征图上,获得文本区域标准的水平特征map。第一步公式如下:

这里M是仿射变换矩阵。![]() 分别表示仿射变换后的feature map的高(在我们的设置中为8)和宽。
分别表示仿射变换后的feature map的高(在我们的设置中为8)和宽。![]() 分别表示在共享特征map的一点的坐标,
分别表示在共享特征map的一点的坐标,![]() 分别表示到文本proposal的上、下、左、右的距离,
分别表示到文本proposal的上、下、左、右的距离,![]() 为方向。
为方向。![]() 和
和![]() 是ground truth 或检测分支给出的。
是ground truth 或检测分支给出的。
有了变换参数,用放射变化很容易可以得到最终的RoI 特征:

其中![]()
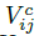
这里![]() 是位置(i,j)在通道c的输出值,
是位置(i,j)在通道c的输出值,![]() 是位于(n,m)通道c的输入值,
是位于(n,m)通道c的输入值,![]() 表示输入的高和宽,
表示输入的高和宽,![]() 是一个通用采样核
是一个通用采样核![]() 的参数,它定义了插值方法,在本文中是双线性插值。实际中,文本proposals的宽度可能变化,我们pad特征maps到最长的宽度,在识别loss函数中忽略padding部分。
的参数,它定义了插值方法,在本文中是双线性插值。实际中,文本proposals的宽度可能变化,我们pad特征maps到最长的宽度,在识别loss函数中忽略padding部分。
空间转换网络STN[21]用类似的方式应用仿射变换,但是通过不同的方法获得放射参数,主要用在图像领域,例如转化图像本身。RoIRotate以共享卷积生成的feature map作为输入,生成所有文本proposals的特征map,具有固定高度和不变的高宽比。
不同于目标分类,文本识别对检测噪音很敏感。在预测的文本区域一个小的错误可能切断几个字符,这对网络训练是很不好的,所以我们在训练过程用ground truth文本区域代替预测的文本区域。在测试过程中,在预测的文本区域使用阈值过滤和NMS。RoIRotate后,转换后的feature maps喂给文本识别分支。
3.4、文本识别分支
文本识别分支旨在用共享卷积提取的通过RoIRotate转换后的区域特征来预测文本标签。考虑到文本区域的标签序列的长度,通过来自原始图像的共享卷积的输入到LSTM的特征沿着宽度方向缩小两次(如3.2部分描述的1/4)。另外,在紧凑的文本区域的可分辨的特征,尤其那些很窄的字符,将被消除。我们的文本识别分支包括VGG-like[47]序列卷积,一个双向LSTM[42,16],一个全连接和一个最后的CTC解码器。
首先,空间特征输入到几个连续的卷积和池化层,沿着高度方向降维来提取更高层次的特征。为简单起见,这里基于VGG-like的连续层的所有公布结果如表1所示。
接下来,提取的更高层次的feature maps L属于![]() ,按时间在主的方式排序为一个序列
,按时间在主的方式排序为一个序列![]() ,输入到RNN的编码器。这里我们用一个双向LSTM,每个方向的输出通道D=256,来捕获依赖于输入序列范围的特征。然后,在两个方向每个时间点上计算的隐藏状态
,输入到RNN的编码器。这里我们用一个双向LSTM,每个方向的输出通道D=256,来捕获依赖于输入序列范围的特征。然后,在两个方向每个时间点上计算的隐藏状态![]()
![]() 求和,再输入到全连接中,这个给出每个状态在整个字符类S上它的分布
求和,再输入到全连接中,这个给出每个状态在整个字符类S上它的分布![]() 。为了避免在小的训练数据集上如ICDAR 2015出现过拟合,我们在全连接前边加了dropout层。最后,用CTC将每帧分类分数转换为标签序列。给出的每个
。为了避免在小的训练数据集上如ICDAR 2015出现过拟合,我们在全连接前边加了dropout层。最后,用CTC将每帧分类分数转换为标签序列。给出的每个![]() 在S上的概率分布
在S上的概率分布![]() ,和ground truth标签序列
,和ground truth标签序列![]() ,和[9]一样标签
,和[9]一样标签![]() 的条件概率是所有路径
的条件概率是所有路径![]() 的概率和:
的概率和:
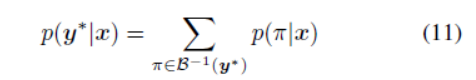
这里![]() 定义了来自有blanks和重复标签的可能的标定的集合到
定义了来自有blanks和重复标签的可能的标定的集合到![]() 的一个多对一的map。训练程序尝试在整个训练集上最大化等式11的和的似然对数。根据[9],识别loss可以表示为:
的一个多对一的map。训练程序尝试在整个训练集上最大化等式11的和的似然对数。根据[9],识别loss可以表示为:
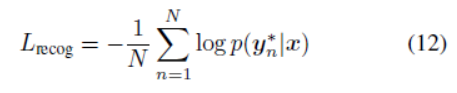
这里N是输入图像中文本区域的数量,![]() 是识别标签。
是识别标签。
和等式3中的检测loss组合,整个多任务loss函数为:
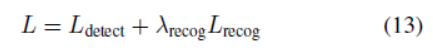
这里超参数![]() 控制两个loss的平衡,在我们的实验中设置为1。
控制两个loss的平衡,在我们的实验中设置为1。
3.5、实现细节
我们用在ImageNet数据集上训练的模型作为我们的预训练模型。训练过程包括两步:首先我们用Synth800k数据集训练网络10个epoch,然后用真实数据微调模型到收敛。对不同的任务用不同训练数据集,这将在第4部分讨论。在ICDAR2015和ICDAR2017 MLT数据集中标定为“DO NOT CARE”的一些模糊的文本区域,我们在训练时忽略它们。
数据增强对于深度神经网络的鲁棒性是很重要的,尤其当实际数据有限,像我们的情况。首先,图像较长的边resize到640-2560像素。图像在[-10°,10°]范围内随机旋转。然后,图像的高度rescale,宽度保持不变,宽高比从0.8到1.2。最后,从变换的图像中随机裁剪640*640大小的样本。
如第3.2部分中描述,我们采用OHEM获得更好的效果。对每张图,选择512个难分类负样本、512个随机负样本和所有的正样本用于分类。最终,正负比例从1:60增加到1:3。对于边界框回归,我们从每张图中选择128个难分类正样本和128个随机正样本用于训练。
在测试过程,从文本定位分支获得预测文本区域后,提出的RoIRotate在这些文本区域上使用了阈值过滤和NMS,然后将选择的文本特征输入到文本识别分支来获得最终的识别结果。对于多尺度测试,来自所有尺度的结果组合起来,再输入到NMS来获得最终的结果。
4、实验
ICDAR 2015 是ICDAR 2015 Robust Reading Competition中的第四个挑战,通常用于多方向场景文本检测和识别。该数据集包括1000张训练图片和500张测试图片。这些图是用Google glasses不关心位置捕获的,所以场景中的文本是任意方向的。对于文本识别任务,它提供了3个特征的单词表作为测试阶段的词汇表,称为“Strong”、“Weak”和“Generic”。“Strong”词典每张图提供了100个单词包括图中出现的所有的单词。“Weak”词典包括出现在整个测试集中的所有单词。“Generic”词典是一个90k的单词表。在训练中,我们首先用来自ICDAR2017 MLT的训练和验证数据集共9000张图来训练我们的模型,然后用ICDAR2015的训练数据集的1000张图和ICDAR2013的229张训练图片来微调我们的模型。
ICDAR2017 MLT 是一个大的多语种文本数据集,包括7200张训练图片、1800张验证图片和9000张测试图片。该数据集由来自9种语言的场景图像组成,数据集种的文本区域可以是任意方向的,所以它是更多变且具有挑战性。这个数据集没有文本识别任务所以我们只公布我们的检测结果。我们用训练和验证集训练我们的模型。
ICDAR 2013 包括229张训练图片和233张测试图片,和ICDAR2015类似,对于文本识别任务也提供了“Strong”、“Weak”和“Generic”词表。不同于上边的数据集,它仅包括水平文本。尽管我们的算法是为带方向的文本设计的,但在本数据集的结果表明提出的算法对水平文本也是适用的。由于这里太少的训练数据,我们首先用来自ICDAR2017 MLT训练和验证集的9000张图来训练一个预训练模型,然后用229张ICDAR2013的训练图片来微调。
4.2. 和两阶段的方法对比
不同于之前的工作,那些将文本检测和识别分为两个不相关的任务,我们的方法联合训练这两个任务,文本检测和识别互相受益于彼此。为了验证这一点,我们构建了一个two-stage系统,文本检测和识别模型是分开训练的。通过移除我们提出的网络中的识别分支来构建检测网络,同样地,从原始网络中移除检测分支来得到识别网络。对于识别网络,文本行从源图像中裁剪得到用作训练数据,和之前的文本识别方法[44,14,37]类似。
如表2,3,4所示,我们提出的FOTS显著优于two-stage方法在文本检测中的“Our Detection”和在文本识别任务中的“Our Two-Stage”。结果显示我们的联合训练策略使得模型参数到一个更好的收敛状态。



由于文本识别的监督有助于网络学习更细节的字符级别特征,使得FOTS在检测中表现更好。为了详细分析,我们总结了四种文本检测的通常的解决方案,Miss:漏检一些文本区域,False:将一些非文本区域错误的看作是文本区域,Split:错误的将一个完整的文本区域分为多个独立的部分,Merge:错误的将几个独立的文本区域合并在一起。如图5所示,与“Our Detection”方法对比,FOTS减少了这四种错误。特别地,“Our Detection”方法聚焦在整个文本区域特征而不是字符级别的特征,所以这种方法当在文本区域内有较大变化或背景有更小的情况表现不好。由于文本识别监督聚焦模型考虑字符级别的粒度细节,FOTS学习了一个有不同形式的单词中不同的字符的语义信息。它也增强了小的形式下字符和背景的不同。如图5所示,对于Miss情况,“Our Detection”方法漏检了文本区域,由于它们的颜色和背景相似。对于False情况,“Our Detection”方法错误的将背景区域识别为文本,由于它有类文本形式(如具有高对比度的重复结构纹理),与此同时FOTS在用识别loss训练后在生成区域时考虑了字符的细节而避免了这种错误。对于Split情况,“Our Detection”方法将一个文本区域分为了两个,因为文本区域的左边和右边有不同的颜色,而同时由于文本区域的字符形式时连续和相似的,FOTS预测该区域作为一个完整的。对于Merge情况,“Our Detection”方法错误的将两个相邻的文本边界框合并在了一起,由于它们太近且有相似的形式,但FOTS利用文本识别提供的字符级别的信息捕获了两个单词之间的空隙。

4.3、和目前最好的结果对比
在这部分,我们对比FOTS和目前最好的方法。如表2、3、4所示,我们的方法在所有数据集都明显优于其他。因为ICDAR2017 MLT没有文本识别任务,我们仅仅公布我们的检测结果。在ICDAR2013中的所有文本区域时用水平边界框标定的,其中很多是轻微倾斜的。优于我们的模型是用ICDAR2017 MLT数据进行预训练的,它可以预测文本区域的方向。为了更好的效果我们最后的文本识别结果保持预测方向,由于评估工具的限制,我们的检测结果是网络预测的最小水平外接矩形。值得一提的是,在ICDAR2015文本识别任务中,我们的方法在F-meature上比之前最好的方法[43,44]高了超过15%。
对于单一尺度的测试,FOTS将ICDAR2015、ICDAR2017 MLT和ICDAR2013的输入图片的较长边分别resize到2240、1280、920来获得最好的结果,同时我们对于多尺度测试采用3-5个scales。

4.4、速度和模型大小
如表5所示,得益于我们的卷积共享策略,和单一的文本检测网络对比,FOTS可以用很少的计算量和存储量的增加,来联合检测和识别文本(7.5fps vs 7.8fps,22fps vs23.9fps),同时它几乎比“Our Two-Stage”方法快乐两倍(7.5 fps vs 3.7 fps,22.0fps vs 11.2fps)。因此,我们的方法获得了最好的效果同时保证了实时的速度。
所有的方法都是在ICDAR2015和ICDAR2013测试集上测试的。这些数据集有68个文本识别标签,我们评估所有的文本图像,计算平均速度。对于ICDAR2015,FOTS用2240*1260大小的图像作为输入,“Our Two-Stage”方法用2240*1260大小的图片来检测,裁剪高32的文本区域切片来识别。对于ICDAR2013,我们将输入图像较长的值resize到920,用高32的图像切片来识别。为了获得实时速度,“FOTS RT”用ResNet-34替换了ResNet-50,用1280*720作为输入。表5中的所有结果是在修改的caffe版本[23]上用TITAN-Xp GPU上测试的。

5、总结
在本文中,我们提出了FOTS,对于带方向的场景文本识别的可端对端训练的网络框架。提出一个新的RoIRotate操作来将检测和识别统一到一个端对端的算法流程。通过共享卷积特征,文本识别步骤几乎不耗时,这使我们的系统达到实时的速度。在标准数据集的实验证明我们的方法在效率和效果上都明显优于之前的方法。
这篇关于FOTS: Fast Oriented Text Spotting with a Unified Network-译文的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!