本文主要是介绍【YOLO v5 v7 v8 v9小目标改进】DWRSeg:优化的多尺度处理,传统的深度学习模型可能在不同尺度的特征提取上存在冗余,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DWRSeg:优化的多尺度处理,传统的深度学习模型可能在不同尺度的特征提取上存在冗余
- 提出背景
- 问题:实时语义分割需要快速且准确地处理图像数据,提取出有意义的特征来识别不同的对象。
- 小目标涨点
- YOLO v5 魔改
- YOLO v7 魔改
- YOLO v8 魔改
- YOLO v9 魔改
提出背景
论文:https://arxiv.org/pdf/2212.01173v3.pdf
现有的语义分割方法,如ESPNet (V2)、DABNet 和 CGNet,设计了基于多速率深度空间扩张卷积的模块来捕获单一输入特征图的多尺度上下文信息,以提高实时语义分割的特征提取效率。
然而,这些设计存在根本性的缺陷,导致深度扩张卷积中的大量权重很少被学习,特别是对于那些具有较大扩张率的权重,从而使得多尺度上下文信息无法有效地被提取。
比如一把特制的钥匙(深度扩张卷积),可以打开一系列不同大小和形状的锁(需要提取的特征信息)。
这把钥匙设计得非常独特,它的齿部可以伸缩(“扩张率”),理论上可以适应不同的锁孔。
但问题在于,这把钥匙尽管能够调整,却往往难以精确匹配所有类型的锁,尤其是那些特殊形状或大小的锁。
结果就是,虽然理论上这把钥匙能开很多锁,实际上它只能有效打开少数几种,而且很难对某些锁进行精确匹配。
这里的“锁”比喻了需要识别和分割的复杂特征,而“钥匙的齿部伸缩”则类似于深度学习中的深度扩张卷积操作,旨在捕捉不同尺度的特征。
但现有方法的问题在于,尽管这种设计允许模型理论上能处理多尺度的特征,实际上却很难精确地适应那些特别复杂或者大小极端的特征——就像那些特殊的锁无法被钥匙准确打开一样。
为了解决这个问题,本文提出了一种新的方法,可以想象为先用一组不同的小钥匙(区域残差化)去粗略匹配不同类型的锁,这样可以确定哪些锁是容易打开的,哪些是难以打开的。
接着,对于那些难以打开的锁,再使用一把能够精确调整的特制钥匙(语义残差化)去细致地适应和打开。
这种方法更有效,因为它不是盲目地尝试用一把万能钥匙去打开所有锁,而是先根据锁的类型和大小选择合适的钥匙,然后再进行精细的调整,这样就大大提高了打开锁的效率和成功率。
问题:多速率深度空间扩张卷积在同一特征图上同时应用多个接收场可能导致某些接收场失效。
- 解法:区域残差化(粗调)+ 语义残差化(精调)
- 之所以使用这个解法,是因为直接在每个特征图上应用具有多个接收场的深度扩张卷积可能导致一些接收场无效,因为不是每个特征图都需要所有接收场。
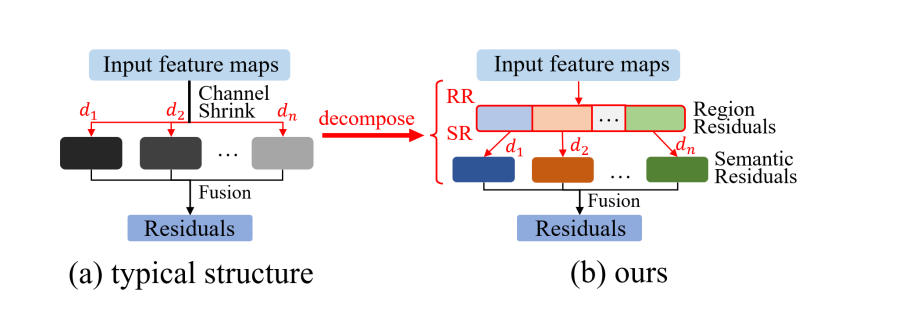
上图是,传统多尺度上下文信息提取结构与提出的新结构之间的对比。
它说明了传统方法是如何通过不同扩张率的扩张卷积处理输入特征,然后结合它们的。
而新方法则包括两个独特的阶段:区域残差化和语义残差化,随后进行融合以产生最终的残差。
与传统的多尺度上下文信息提取结构相比,提出的新结构通过将信息提取流程分解为区域残差化和语义残差化两个独立阶段,从而实现了对输入特征的更有效处理。
这种方法的主要优势在于它能够更加精确和有效地利用深度扩张卷积,因为它避免了不必要的计算和冗余的接收场大小,确保了更加高效的特征提取。
从粗加工(DWR模块)到细加工(SIR模块),最后通过简化的组装过程(编解码器设计)完成,DWRSeg网络(本文提出的方法)能够高效且准确地完成实时语义分割任务。
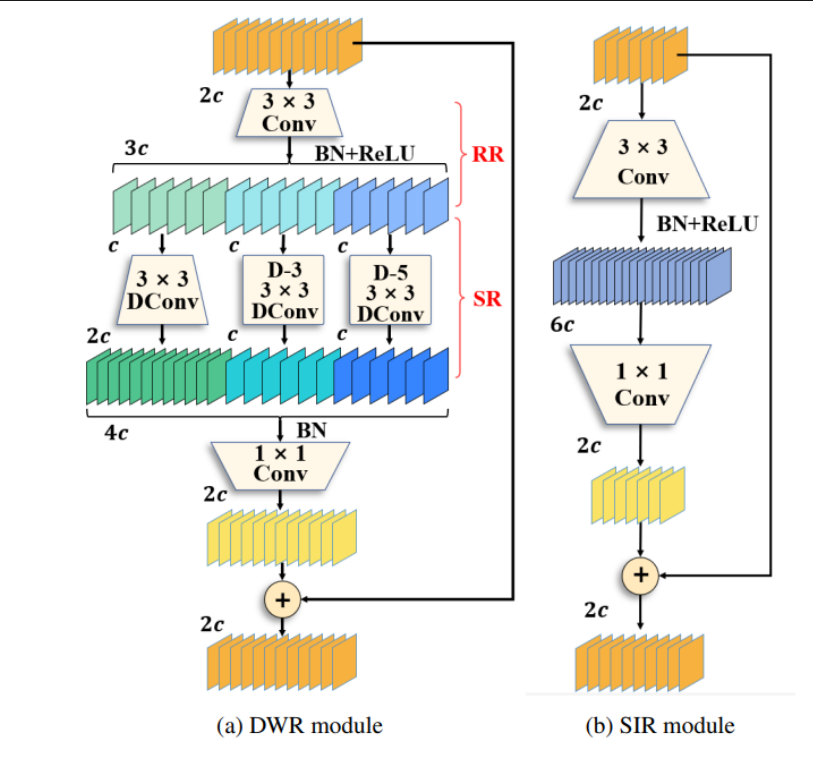
DWR模块利用多尺度扩张卷积来捕获不同尺度的上下文信息。
SIR模块是早期阶段的简化版本,适用于较小的接收场。
这两种模块都旨在高效提取特征,然后传递给解码器。
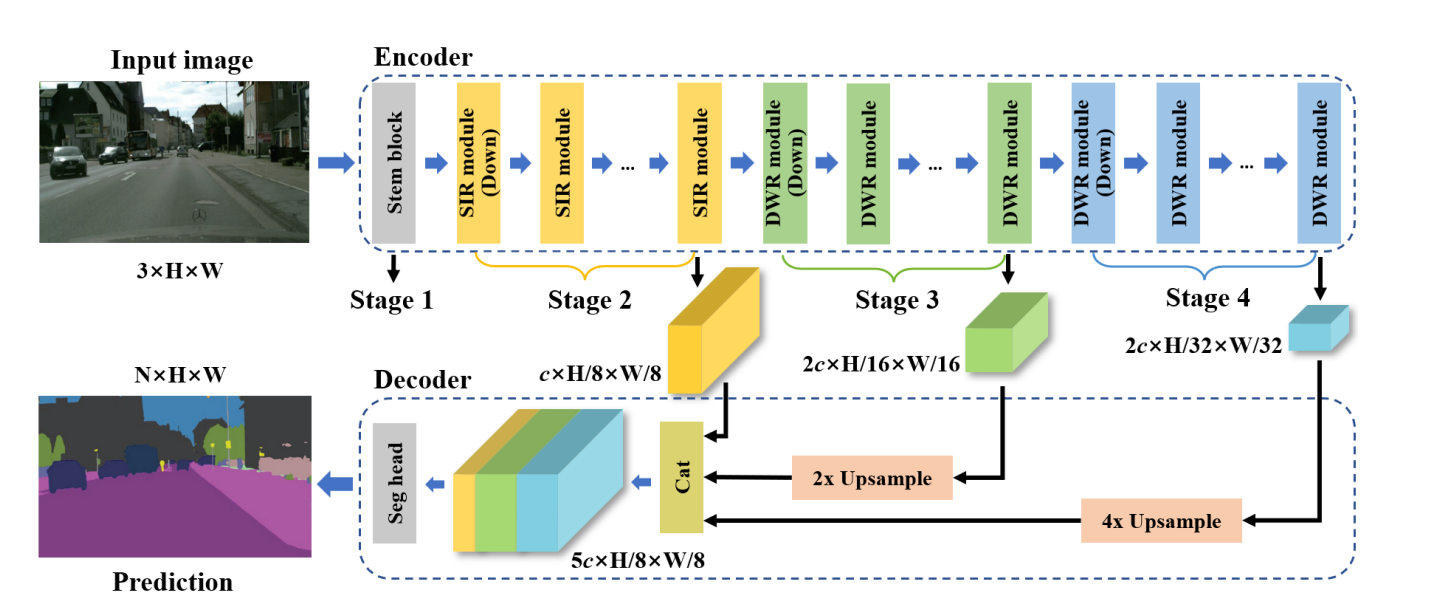
上图展示了整个网络结构的概览,包括编码器中的初始块(stem block)、SIR模块和DWR模块,以及将不同阶段的信息整合成最终预测结果的解码器。
这为图像数据如何从输入到输出通过网络流动提供了直观的视图。
起始模块作为网络的入口,处理初始图像数据;分割头(Segmentation head)用于解码器中产生最终的分割图像。
问题:实时语义分割需要快速且准确地处理图像数据,提取出有意义的特征来识别不同的对象。
解法:DWRSeg网络采用编解码器结构,利用了DWR模块和SIR模块来提高特征提取的效率和精度。
-
子特征1:区域残差化
- 作用:为了在不同区域的特征提取中实现专门化处理,它通过3x3卷积和批归一化(BN)生成更加集中的特征表达。
- 原因:某些特征区域的复杂性要求使用更专注的处理方法,从而使得特征表达更加简明和直接,减少了后续处理的复杂度。
-
子特征2:语义残差化
- 作用:在区域残差化的基础上,通过不同扩张率的深度分离卷积进行语义上的细节捕捉,提取更加丰富的上下文信息。
- 原因:图像中的不同对象需要不同尺度的上下文理解,通过调整扩张率,能够更精确地捕获对应的特征信息。
-
子特征3:DWR模块的创新设计
- 作用:DWR模块融合了多个不同扩张率的卷积过程,允许在高级网络阶段处理更广泛的上下文信息。
- 原因:在网络的高阶段,需要更全面的视野来理解图像,以获得足够的上下文信息进行精确的分割。
-
子特征4:SIR模块的简化设计
- 作用:SIR模块针对较小的接收场景进行了优化,适用于对细节敏感的低阶段特征提取。
- 原因:在网络的初级阶段,细节特征更为重要,通过SIR模块可以在不牺牲性能的前提下,加速对这些细节的处理。
-
子特征5:编解码器的高效结构
- 作用:使用类似全卷积网络(FCN)的简化解码器结构,有效地将不同阶段的特征图进行融合,形成最终的预测。
- 原因:为了将从不同模块提取的特征有效地结合起来,形成最终的高质量输出,需要一个高效的信息合并和上采样机制。
小目标涨点
更新中…
YOLO v5 魔改
YOLO v7 魔改
YOLO v8 魔改
YOLO v9 魔改
这篇关于【YOLO v5 v7 v8 v9小目标改进】DWRSeg:优化的多尺度处理,传统的深度学习模型可能在不同尺度的特征提取上存在冗余的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






