yolo专题

烟火目标检测数据集 7800张 烟火检测 带标注 voc yolo
一个包含7800张带标注图像的数据集,专门用于烟火目标检测,是一个非常有价值的资源,尤其对于那些致力于公共安全、事件管理和烟花表演监控等领域的人士而言。下面是对此数据集的一个详细介绍: 数据集名称:烟火目标检测数据集 数据集规模: 图片数量:7800张类别:主要包含烟火类目标,可能还包括其他相关类别,如烟火发射装置、背景等。格式:图像文件通常为JPEG或PNG格式;标注文件可能为X
![[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别](https://i-blog.csdnimg.cn/direct/22c867ab717d44c78b985ed667169b42.png)
[数据集][目标检测]血细胞检测数据集VOC+YOLO格式2757张4类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2757 标注数量(xml文件个数):2757 标注数量(txt文件个数):2757 标注类别数:4 标注类别名称:["Platelets","RBC","WBC","sickle cell"] 每个类别标注的框数:
![[数据集][目标检测]智慧农业草莓叶子病虫害检测数据集VOC+YOLO格式4040张9类别](https://i-blog.csdnimg.cn/direct/4a9ca83db964467783f221a1fd15ab5b.png)
[数据集][目标检测]智慧农业草莓叶子病虫害检测数据集VOC+YOLO格式4040张9类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):4040 标注数量(xml文件个数):4040 标注数量(txt文件个数):4040 标注类别数:9 标注类别名称:["acalcerosis","fertilizer","flower","fruit","grey

【YOLO 系列】基于YOLOV8的智能花卉分类检测系统【python源码+Pyqt5界面+数据集+训练代码】
前言: 花朵作为自然界中的重要组成部分,不仅在生态学上具有重要意义,也在园艺、农业以及艺术领域中占有一席之地。随着图像识别技术的发展,自动化的花朵分类对于植物研究、生物多样性保护以及园艺爱好者来说变得越发重要。为了提高花朵分类的效率和准确性,我们启动了基于YOLO V8的花朵分类智能识别系统项目。该项目利用深度学习技术,通过分析花朵图像,自动识别并分类不同种类的花朵,为用户提供一个高效的花朵识别

水面垃圾检测数据集 3000张 水面垃圾 带标注 voc yolo
数据集概述 该数据集包含3000张图像,专注于水面垃圾的检测。数据集已经按照VOC(Visual Object Classes)和YOLO(You Only Look Once)两种格式进行了标注,适用于训练深度学习模型,特别是物体检测模型,用于识别水面上的各种垃圾。 数据集特点 多样性:包含3000张图像,涵盖了多种类型的水面垃圾,确保模型能够识别各种类型的垃圾。双标注格式:提供VO
![[数据集][目标检测]抽烟检测数据集VOC+YOLO格式22559张2类别](https://i-blog.csdnimg.cn/direct/cda7c7a3ea8348c5a8f4cddff90c679c.png)
[数据集][目标检测]抽烟检测数据集VOC+YOLO格式22559张2类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):22559 标注数量(xml文件个数):22559 标注数量(txt文件个数):22559 标注类别数:2 标注类别名称:["cig-pack","smoke"] 每个类别标注的框数: cig-pack 框数 = 2
![[数据集][目标检测]人脸口罩佩戴目标检测数据集VOC+YOLO格式8068张3类别](https://i-blog.csdnimg.cn/direct/088e80f82eb14e728a652ec9ba9fc6d4.png)
[数据集][目标检测]人脸口罩佩戴目标检测数据集VOC+YOLO格式8068张3类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):8068 标注数量(xml文件个数):8068 标注数量(txt文件个数):8068 标注类别数:3 标注类别名称:["face_with_mask","face_without_mask","mask"] 每个类别

CVPR 2024最新论文分享┆YOLO-World:一种实时开放词汇目标检测方法
论文分享简介 本推文主要介绍了CVPR 2024上的一篇论文《YOLO-World: Real-Time Open-Vocabulary Object Detection》,论文的第一作者为Tianheng Cheng和Lin Song,该论文提出了一种开放词汇目标检测的新方法,名为YOLO-World。论文通过引入视觉-语言建模和大规模预训练解决了传统YOLO检测器在固定词汇检测中的局限性。论
![[数据集][目标检测]井盖丢失未盖破损检测数据集VOC+YOLO格式2890张5类别](https://i-blog.csdnimg.cn/direct/31cf5cd2f3cd4257a13e5fb30d7908a0.png)
[数据集][目标检测]井盖丢失未盖破损检测数据集VOC+YOLO格式2890张5类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2890 标注数量(xml文件个数):2890 标注数量(txt文件个数):2890 标注类别数:5 标注类别名称:["broke","circle","good","lose","uncovered"] 每个类别标

YOLO缺陷检测学习笔记(3)
文章目录 PCA主成分分析PCA的核心思想PCA的步骤PCA降维后的数据表达示例数据Step 1:标准化数据 Step 2:计算协方差矩阵Step 3:计算协方差矩阵的特征值和特征向量Step 4:选择主成分Step 5:将数据映射到主成分总结PCA的应用PCA的局限性 AUC和ROC1. ROC 曲线2. AUC 随机森林1. **随机森林的基本概念**2. **随机森林的优点**3. *

数据标注:PascalVOC模式到YOLO模式的一键转化
import osimport xml.etree.ElementTree as ETfrom decimal import Decimaldirpath = 'E:\\0911-0951最后一个文件夹\\20190215-211313 {3D675E7F-B913-41B0-B915-9381A662A919}(SHDT-0916(A))\\ZXB_LC01D\\xml' # 原来存放xm

宠物狗检测-目标检测数据集(包括VOC格式、YOLO格式)
宠物狗检测-目标检测数据集(包括VOC格式、YOLO格式) 数据集:链接:https://pan.baidu.com/s/1roegkaGAURWUVRR-D7OzzA?pwd=dxv6 提取码:dxv6 数据集信息介绍: 共有20580 张图像和一一对应的标注文件 标注文件格式提供了两种,包括VOC格式的xml文件和YOLO格式的txt文件。 标注的对象共有以下几种: 狗的类
![[数据集][目标检测]水面垃圾检测数据集VOC+YOLO格式2027张1类别](https://i-blog.csdnimg.cn/direct/1ed27bae75ad496fabf8bfd7346c315a.png)
[数据集][目标检测]水面垃圾检测数据集VOC+YOLO格式2027张1类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2027 标注数量(xml文件个数):2027 标注数量(txt文件个数):2027 标注类别数:1 标注类别名称:["trash"] 每个类别标注的框数: trash 框数 = 2974 总框数:2974 使用标注

YOLO标注文件清洗案例代码-学习篇
背景简介 YOLO标注文件清洗 训练一个人工智能算法需要一个庞大的数据集,这个数据集需要进行人为标注 但由于出现意外,造成部分数据丢失,使得标注文件和图片文件的文件名前缀不能一一对应 需要写一段代码将可以文件名前缀一一对应的文件保存到一个新的文件夹中,已完成数据的清洗 问题背景 待清洗的文件目录,images中是图片,labels中是txt标注文件,标注后images和labels中的文件名
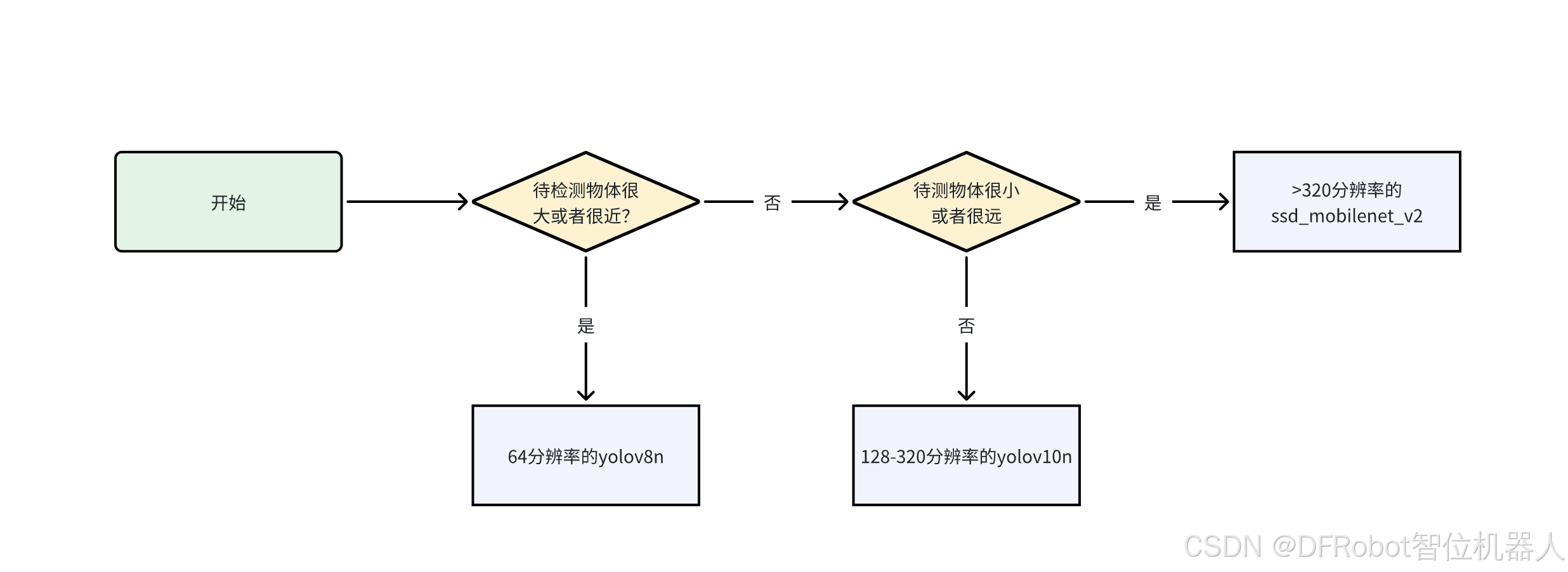
行空板上YOLO和Mediapipe视频物体检测的测试
Introduction 经过前面三篇教程帖子(yolov8n在行空板上的运行(中文),yolov10n在行空板上的运行(中文),Mediapipe在行空板上的运行(中文))的介绍,我们对如何使用官方代码在行空板上运行物体检测的AI模型有了基本的概念,并对常见的模型进行了简单的测试和对比。 在行空板上YOLO和Mediapipe图片物体检测的测试(中文)中我们对于行空板上使用YOLO和Medi
![[数据集][目标检测]西红柿缺陷检测数据集VOC+YOLO格式17318张3类别](https://i-blog.csdnimg.cn/direct/f55fa1e09fbd4ca49a337acaacc017b6.png)
[数据集][目标检测]西红柿缺陷检测数据集VOC+YOLO格式17318张3类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):17318 标注数量(xml文件个数):17318 标注数量(txt文件个数):17318 标注类别数:3 标注类别名称:["Bad","Good","Unripe"] 每个类别标注的框数: Bad 框数 = 102
![[数据集][目标检测]轮胎缺陷检测数据集VOC+YOLO格式2154张4类别](https://i-blog.csdnimg.cn/direct/5aca09e6aa35438e8bbaad0f14eee84e.png)
[数据集][目标检测]轮胎缺陷检测数据集VOC+YOLO格式2154张4类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):2154 标注数量(xml文件个数):2154 标注数量(txt文件个数):2154 标注类别数:4 标注类别名称:["debris","ground","side","side_cut"] 每个类别标注的框数: d
![[数据集][目标检测]机油泄漏检测数据集VOC+YOLO格式43张1类别](https://i-blog.csdnimg.cn/direct/5d6f12625ae54956b400a0d56d7d1ff5.png)
[数据集][目标检测]机油泄漏检测数据集VOC+YOLO格式43张1类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):43 标注数量(xml文件个数):43 标注数量(txt文件个数):43 标注类别数:1 标注类别名称:["engineoil"] 每个类别标注的框数: engineoil 框数 = 44 总框数:44 使用标注工具
![[数据集][目标检测]汽油检泄漏检测数据集VOC+YOLO格式237张2类别](https://i-blog.csdnimg.cn/direct/c94b917c554b499692e34ba541bd7e44.png)
[数据集][目标检测]汽油检泄漏检测数据集VOC+YOLO格式237张2类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):237 标注数量(xml文件个数):237 标注数量(txt文件个数):237 标注类别数:2 标注类别名称:["petrol","water"] 每个类别标注的框数: petrol 框数 = 212 water 框
![[数据集][目标检测]智慧牧场猪只检测数据集VOC+YOLO格式16245张1类别](https://i-blog.csdnimg.cn/direct/30f3f1f068204b89b6f55bc98b6dc162.png)
[数据集][目标检测]智慧牧场猪只检测数据集VOC+YOLO格式16245张1类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):16245 标注数量(xml文件个数):16245 标注数量(txt文件个数):16245 标注类别数:1 标注类别名称:["pig"] 每个类别标注的框数: pig 框数 = 28514 总框数:28514 使用标
![[数据集][目标检测]轮胎检测数据集VOC+YOLO格式4629张1类别](https://i-blog.csdnimg.cn/direct/2857c086fdc44da29d3c36213fc10cd6.png)
[数据集][目标检测]轮胎检测数据集VOC+YOLO格式4629张1类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):4629 标注数量(xml文件个数):4629 标注数量(txt文件个数):4629 标注类别数:1 标注类别名称:["tire"] 每个类别标注的框数: tire 框数 = 16132 总框数:16132 使用标注

将语义分割的标签转换为实例分割(yolo)的标签
语义分割的标签(目标处为255,其余处为0) 实例分割的标签(yolo.txt),描述边界的多边形顶点的归一化位置 绘制在原图类似蓝色的边框所示。 废话不多说,直接贴代码; import osimport cv2import numpy as npimport shutildef img2label(imgPath, labelPath, imgbjPath, seletName)
![[数据集][目标检测]灭火器检测数据集VOC+YOLO格式3255张1类别](https://i-blog.csdnimg.cn/direct/133fa174bfd048449969767f1e9ba8a4.png)
[数据集][目标检测]灭火器检测数据集VOC+YOLO格式3255张1类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):3255 标注数量(xml文件个数):3255 标注数量(txt文件个数):3255 标注类别数:1 标注类别名称:["miehuoqi"] 每个类别标注的框数: miehuoqi 框数 = 6185 总框数:618

改进YOLO的群养猪行为识别算法研究及部署(小程序-网站平台-pyqt)
概述 群养猪的运动信息和行为信息与其健康状况息息相关,但人工巡视费时费力,本实验提出采用行为识别算法于群养猪的养殖管理中,识别群养猪drink(饮水)、stand(站立)和lie(躺卧)行为,为自动化养殖提供基础。本项目最终以三种不同的形式进行部署,分别为: 网站平台微信小程序PyQt应用程序 实验流程 下图是基于改进YOLOv5s的群养猪行为识别模型建立流程,可概括为以下几个阶段:数
![[数据集][目标检测]玉米病害检测数据集VOC+YOLO格式6000张4类别](https://i-blog.csdnimg.cn/direct/e89fab521f8f45929f1ca4743f1b81de.png)
[数据集][目标检测]玉米病害检测数据集VOC+YOLO格式6000张4类别
数据集格式:Pascal VOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):6000 标注数量(xml文件个数):6000 标注数量(txt文件个数):6000 标注类别数:4 标注类别名称:["Corn","Damaged Corn","Maize","Plaga"] 每个类别标注的框数:

(已开源-CVPR 2024)YOLO-World: Real-Time Open-Vocabulary Object Detection
169期《YOLO-World Real-Time Open-Vocabulary Object Detection》 You Only Look Once (YOLO) 系列检测模型是目前最常用的检测模型之一。然而,它们通常是在预先定义好的目标类别上进行训练,很大程度上限制了它们在开放场景中的可用性。为了解决这一限制,本文引入了 YOLO-World,通过视觉语言建模和大规模数