本文主要是介绍基于MVO优化的Bi-LSTM多输入时序预测(Matlab)多元宇宙算法优化长短期神经网络时序预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、程序及算法内容介绍:
基本内容:
亮点与优势:
二、实际运行效果:
三、算法介绍:
四、完整程序下载:
一、程序及算法内容介绍:
基本内容:
-
本代码基于Matlab平台编译,将MVO(多元宇宙算法)与Bi-LSTM(双向长短期记忆神经网络)结合,进行多输入数据时序预测
-
输入训练的数据包含8个特征,1个响应值,即通过8个输入值预测1个输出值(多变量回归预测,输入输出个数可自行指定)
-
归一化训练数据,提升网络泛化性
-
通过MVO算法优化Bi-LSTM网络的学习率、神经元个数参数,记录下最优的网络参数
-
训练LSTM网络进行回归预测,实现更加精准的预测
-
迭代计算过程中,自动显示优化进度条,实时查看程序运行进展情况
-
自动输出多种多样的的误差评价指标,自动输出大量实验效果图片
亮点与优势:
-
注释详细,几乎每一关键行都有注释说明,适合小白起步学习
-
直接运行Main函数即可看到所有结果,使用便捷
-
编程习惯良好,程序主体标准化,逻辑清晰,方便阅读代码
-
所有数据均采用Excel格式输入,替换数据方便,适合懒人选手
-
出图详细、丰富、美观,可直观查看运行效果
-
附带详细的说明文档(下图),其内容包括:算法原理+使用方法说明

二、实际运行效果:

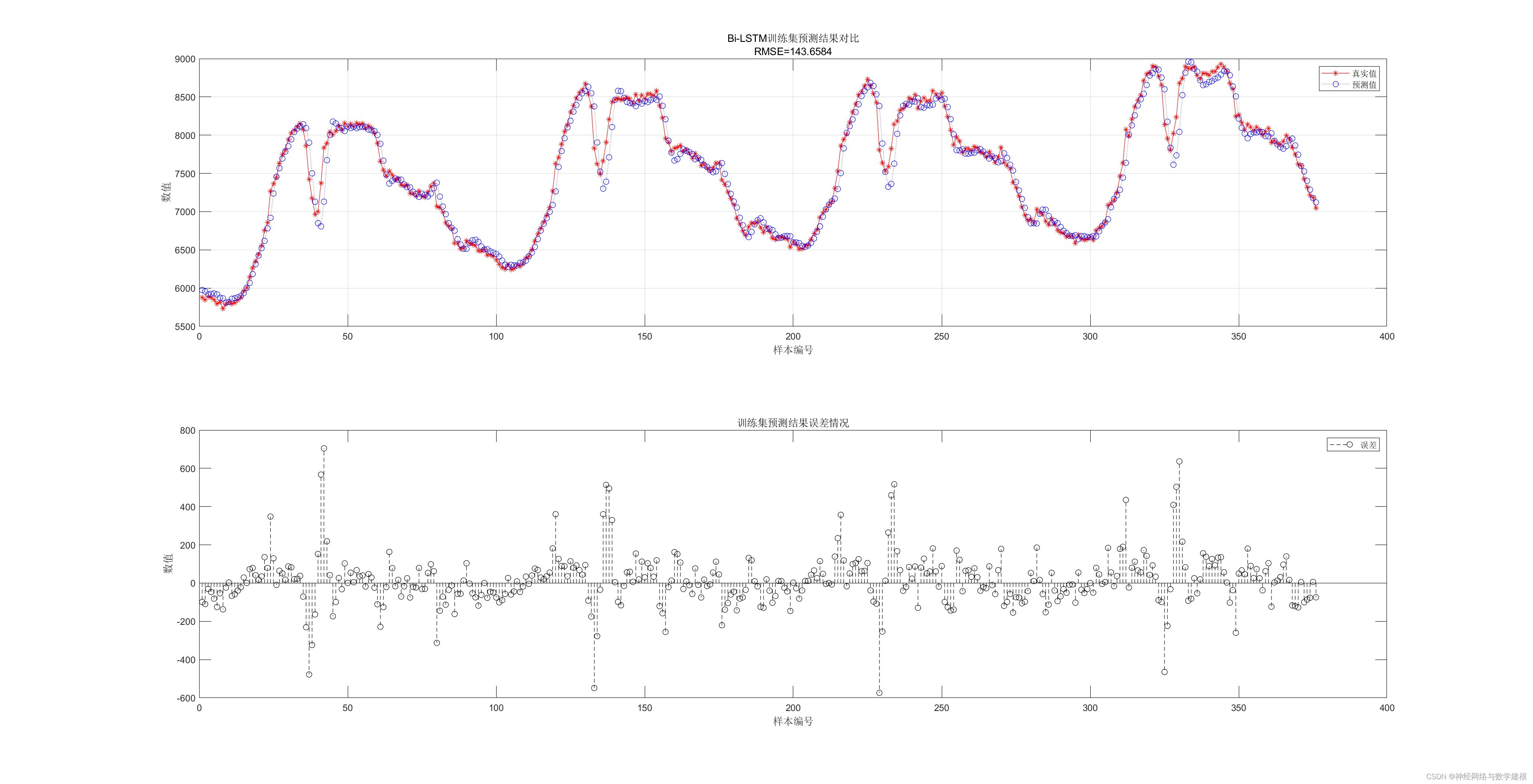

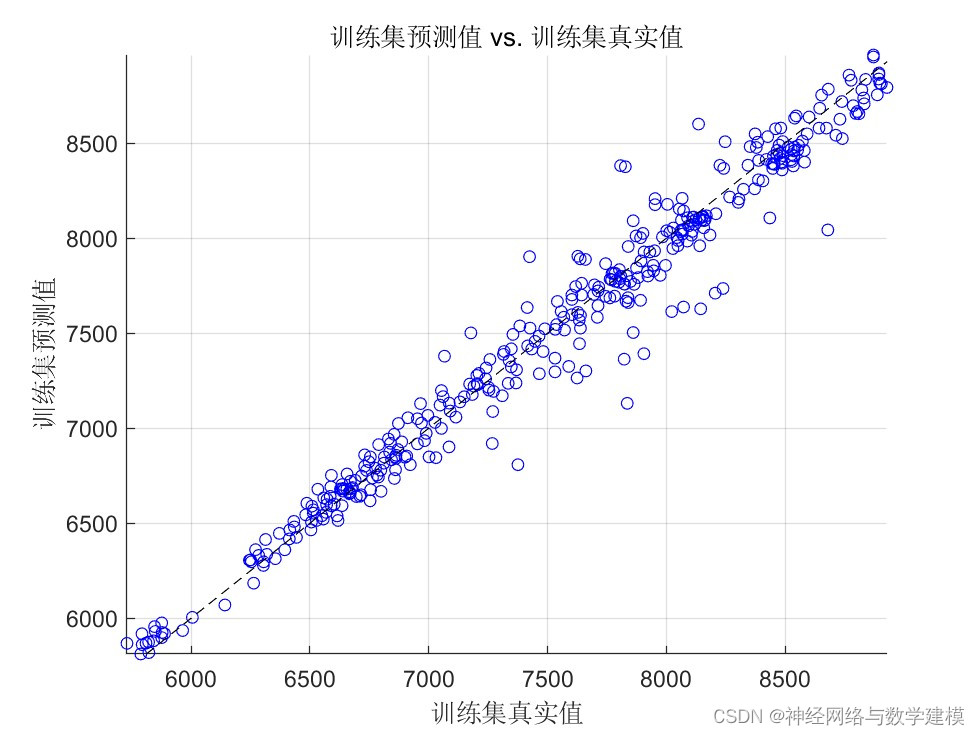

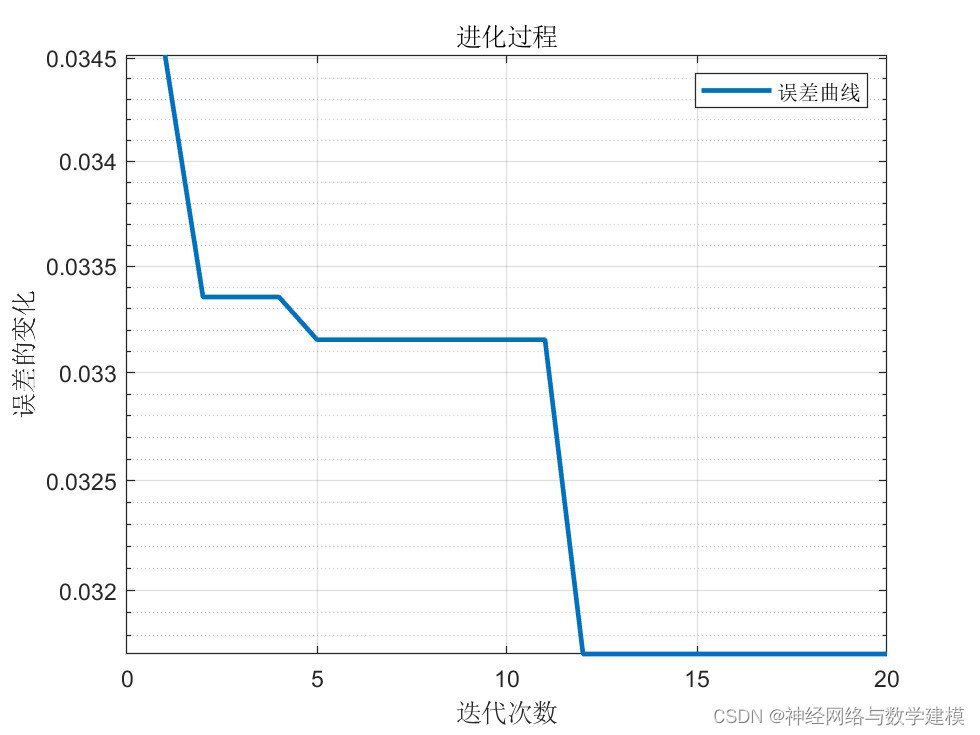

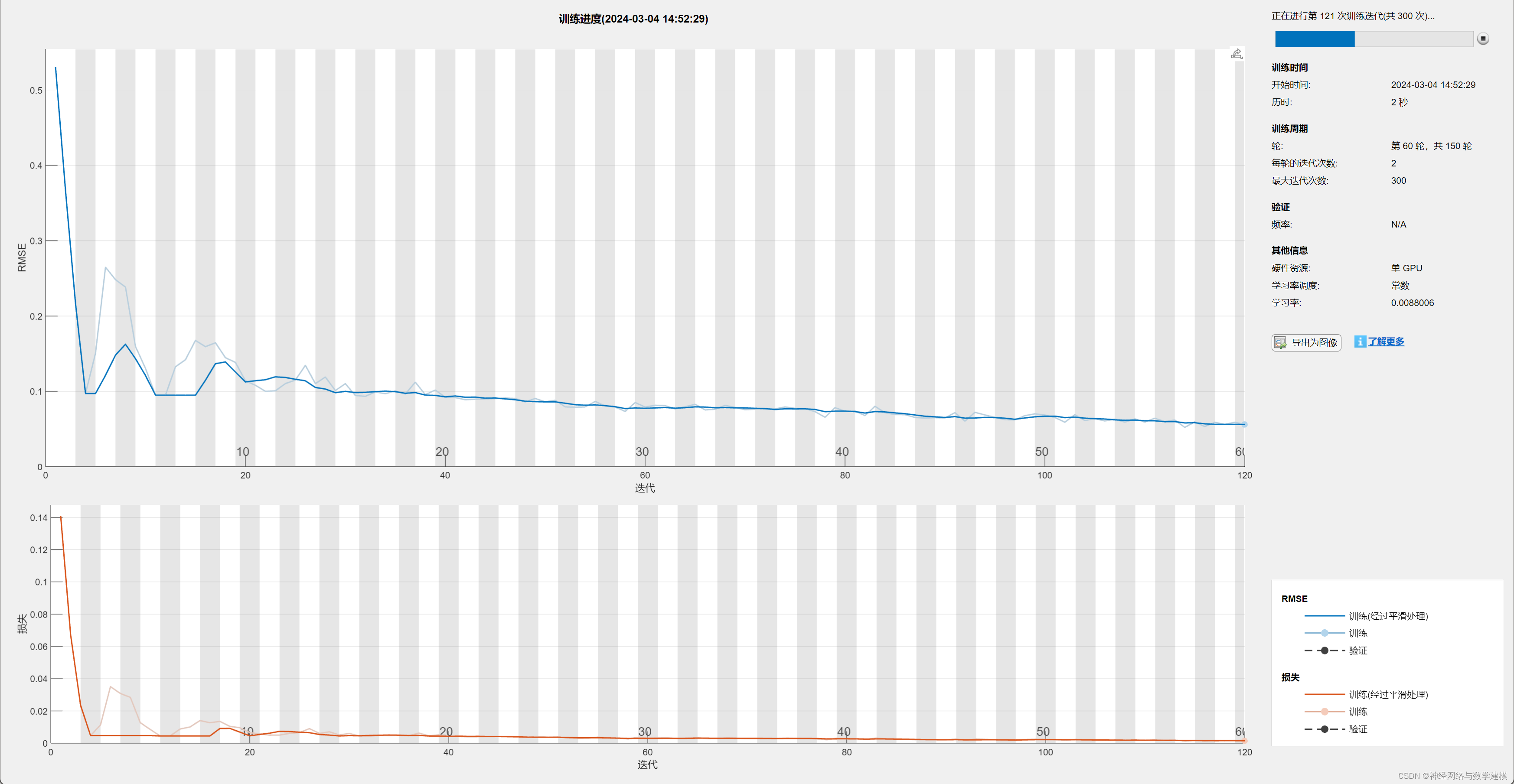
三、算法介绍:
多元宇宙优化算法(MVO):是一种启发式优化算法,它源于天文学中的多元宇宙假说,模拟了多个宇宙的演化过程。该算法通过不断地移动“多元宇宙”,将每个宇宙视为一个解空间,在多个目标函数之间寻找最优解。具体实现中,算法首先初始化一个包含多个宇宙的种群,然后每个宇宙内部随机生成一些初始粒子,并使用粒子群算法搜索最优解。接着,通过交换和融合操作使所有宇宙在全局范围内搜索最优解。这个过程可以重复多次,直到达到预定停止条件或最大迭代次数。多元宇宙优化算法具有参数少、结构简单、效率高等优点,适用于多目标优化问题的求解。
双向长短期记忆神经网络(BiLSTM):是一种特殊的循环神经网络(RNN)结构,用于处理序列数据并保持长期记忆。与传统的RNN模型不同,BiLSTM同时考虑了过去和未来的信息,使得模型能够更好地捕捉序列数据中的上下文关系。BiLSTM结构由两个独立的LSTM网络组成,分别从序列的起始和末尾开始处理输入。这两个网络分别称为前向LSTM和后向LSTM。前向LSTM从序列的起始位置开始处理输入序列,而后向LSTM则从序列的末尾开始处理。每个LSTM单元内部由单元状态(cell state)和各种门控机制(如遗忘门、输入门和输出门)组成,以控制信息的流动和记忆的更新。
四、完整程序下载:
这篇关于基于MVO优化的Bi-LSTM多输入时序预测(Matlab)多元宇宙算法优化长短期神经网络时序预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







