本文主要是介绍CVPR2017 DenseNet, Refiner,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
师兄给我安利了CVPR2017的两篇最佳论文,就瞄了两眼;发觉最佳论文真的是简单易懂,特别是DenseNet感觉看图就可以了= =
越发觉越厉害的东西表述起来越简单,,ԾㅂԾ,,
首先是DenseNet,其实还是很意外是一个CNN的分类模型,因为传统去做分类模型感觉真的不受宠了,主要是很多指标太难再往上刷了,而且很少看到一个新的且普适的idea,我之前看到的最新的idea是face++的shuffleNet,加入了shuffle的操作,但它又不算是传统的分类,它的目标是移动端,很精巧(参数少)。
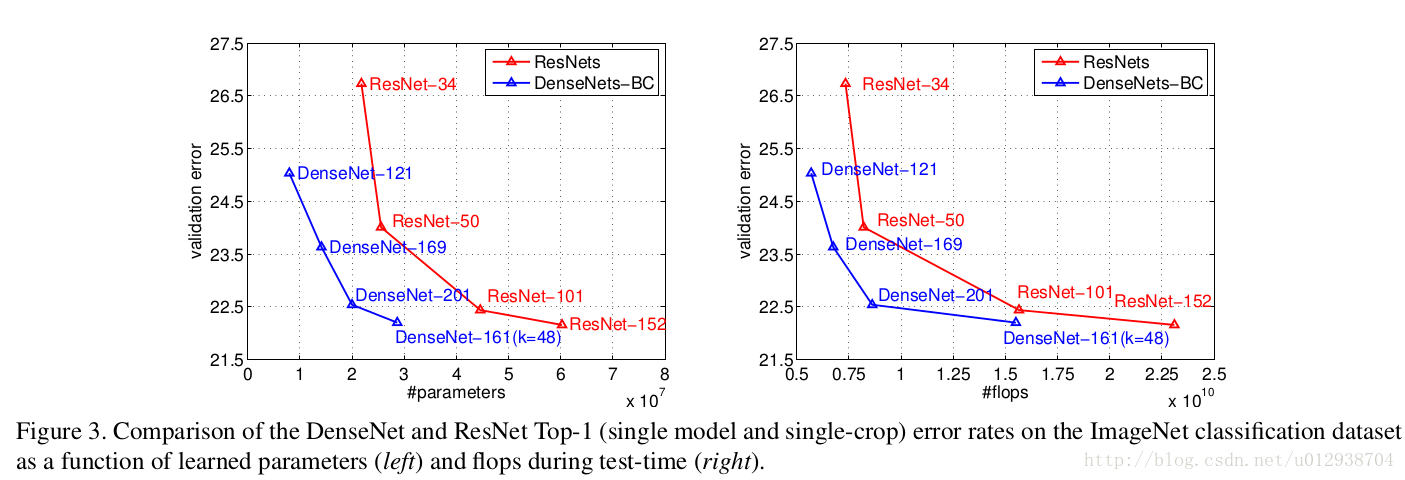
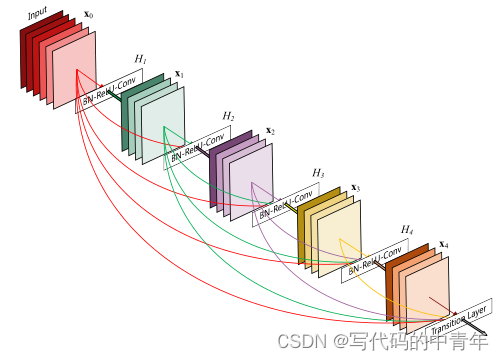
DenseNet的想法很暴力,像是ResNet的变种(ShuffleNet也像是它的变种),它的构建建立在卷积层如果离输入层/输入层更近,那么它更容易收敛,所以它的做法比ResNet更暴力,ResNet只是前后两层之间的输出做sum,而这个则是要求各个层之间都有关联,即原来的网络如果有L层,则有L-1个连接,而现在每两个层之间都有一个连接,即L*(L+1)/2个连接,就问你怕不怕,,ԾㅂԾ,,
啥?怎么连接的,我们看看源码
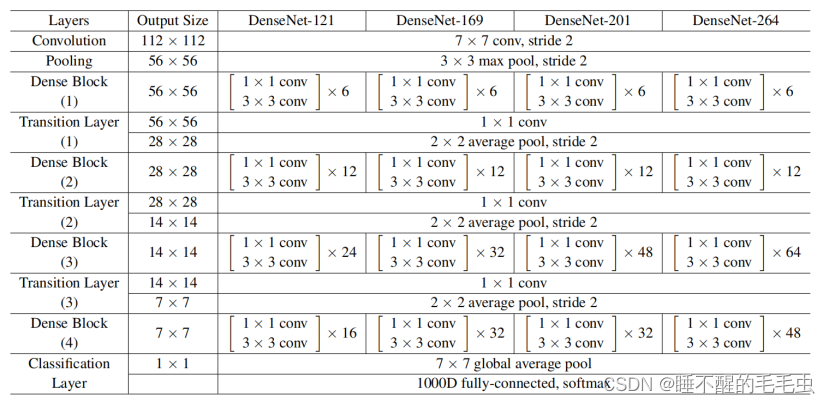
def dense_block(x, stage, nb_layers, nb_filter, growth_rate, dropout_rate=None, weight_decay=1e-4, grow_nb_filters=True):''' Build a dense_block where the output of each conv_block is fed to subsequent ones# Argumentsx: input tensorstage: index for dense blocknb_layers: the number of layers of conv_block to append to the model.nb_filter: number of filtersgrowth_rate: growth ratedropout_rate: dropout rateweight_decay: weight decay factorgrow_nb_filters: flag to decide to allow number of filters to grow'''eps = 1.1e-5concat_feat = xfor i in range(nb_layers):branch = i+1x = conv_block(concat_feat, stage, branch, growth_rate, dropout_rate, weight_decay)concat_feat = merge([concat_feat, x], mode='concat', concat_axis=concat_axis, name='concat_'+str(stage)+'_'+str(branch))if grow_nb_filters:nb_filter += growth_ratereturn concat_feat, nb_filter就concat到一起啊= =这样做的结果肯定是参数太大了,为了解决这个问题,我们再次引入百搭的1*1卷积核来压缩一下我们的tensor方便再后面再搞事情,当然没压缩的tensor也保留下来,pooling, relu, BN也不要停
这样反复来几次,于是乎denseNet的模型就搭建好了
这里将所有的feature联合起来,再我理解像是结合所有尺度的feature来做判断,而且相比resnet/highway net更加直观,无论从结果还是原理都是make sense的
而另外一篇苹果大佬的论文则是基于GAN的优化
GAN的大火似乎是必然的,因为它不仅有趣,且确实能解决很多问题
像我自己在做医疗图像,知道医疗数据集的标注是多么耗时耗力的一件事情,所以当时看到GAN就想着能不能作为data augmentation的手段之一
说回来,苹果大佬的这篇相对而言没有让我感觉辣么厉害,可能还是太连青(◐﹏◐)
它的重点是在生成器G和判别器D中间多整出一个refiner neural network,而这个网络的训练也非常的易于理解
首先说说refiner的意义何在,它就类似于一个加工器,我们不直接将生成器生成的图片作为输出,而是再生成图片的基础上再做一次加工使其更加逼真,所以refiner的输入是生成器的输出,输出是判别器的输入
于是乎,文章觉得这个起到逼真作用的refiner要达到两个目的:1)混淆判别器,让判别器分不出来;2)保留生成器生成图片的信息;
于是乎,作者大笔一挥给出了这个网络的损失函数

大佬就是这么任性,1)式作为refiner的损失函数,前部分l_real用来混淆判别器,后部分l_reg保留生成图片信息

2)是判别器的损失函数,右边yi为真实样本,左边的~xi为refiner加工过的假样本,为了使判别器分不出来,那我们就要最大化这个损失;
于是乎1)式的前部分就可以从2)式来改写:

最小化3)式的损失就能达到最大化2)式的效果
紧接着作者又一段骚操作给出了整个损失函数

后面为了保留原来图片的信息最小化差值没有问题,但是为什么是L1范数不是L2范数我没想通,希望有大佬能够解答
另外它这里的refiner网络是一个全卷积网络,相当于就是flatten之后的全连接网络,嗯,还是get不到为啥是L1范数
还有几波骚操作不能不提
1)它这里的判别器不仅仅是判别器判别整个图像,而(应该是,我理解的是)是一个判别器判断多个Local patch(即判断特定位置),文章的的解释是这样更能增加判别器的判别能力(增加了训练样本,且限制了卷积核大小)(限制卷积核的大小可能是为了减少参数?为什么限制了卷积核的大小更有助于增强判别器的精度,这里也没懂=,=
2)判别器对于过去已经被标注为假的样本应该时刻铭记,不应该好了伤疤忘了痛,所以我们要反复戳伤疤,哦, 不,反复把以前的refiner造出来的样本和现在的样本结合起来塞进去训练

像上面这样有一个buffer用于存储以前refiner生成过的图片
唠完了,我决定去尝试一下DenseNet(:逃
参考文献:
Shrivastava A, Pfister T, Tuzel O, et al. Learning from Simulated and Unsupervised Images through Adversarial Training[J]. 2016.
Huang G, Liu Z, Weinberger K Q. Densely Connected Convolutional Networks[J]. 2016.
这篇关于CVPR2017 DenseNet, Refiner的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!