本文主要是介绍分类神经网络3:DenseNet模型复现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
DenseNet网络架构
DenseNet部分实现代码
DenseNet网络架构
论文原址:https://arxiv.org/pdf/1608.06993.pdf
稠密连接神经网络(DenseNet)实质上是ResNet的进阶模型(了解ResNet模型请点击),二者均是通过建立前面层与后面层之间的“短路连接”,但不同的是,DenseNet建立的是前面所有层与后面层的密集连接,其一大特点是通过特征在通道上的连接来实现特征重用,这让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能。DenseNet 网络的模型结构如下:

DenseNet 的网络结构主要由DenseBlock和Transition Layer组成。
DenseBlock:密集连接机制。互相连接所有的层,即每一层的输入都来自于它前面所有层的特征图,每一层的输出均会直接连接到它后面所有层的输入,这可以实现特征重用(即对不同“级别”的特征——不同表征进行总体性地再探索),提升效率。具体的连接方式如下图示:

在同一个DenseBlock当中,特征层的高宽不会发生改变,但是通道数会发生改变。可以看出,DenseBlock中采用了BN+ReLU+Conv的结构,然而一般网络是用Conv+BN+ReLU的结构。这是由于卷积层的输入包含了它前面所有层的输出特征,它们来自不同层的输出,因此数值分布差异比较大,所以它们在输入到下一个卷积层时,必须先经过BN层将其数值进行标准化,然后再进行卷积操作。通常为了减少参数,一般还会先加一个1x1 卷积来减少参数量。所以DenseBlock中的每一层采用BN+ReLU+1x1Conv 、Conv+BN+ReLU+3x3 Conv的结构。
Transition Layer:用于将不同DenseBlock之间进行连接,整合上一个DenseBlock获得的特征,并且缩小上一个DenseBlock的宽高,达到下采样的效果,实质上起到压缩模型的作用。Transition Layer中一般包含一个1x1卷积(用于调整通道数)和2x2平均池化(用于降低特征图大小),结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。
DenseNet网络的具体配置信息如下:
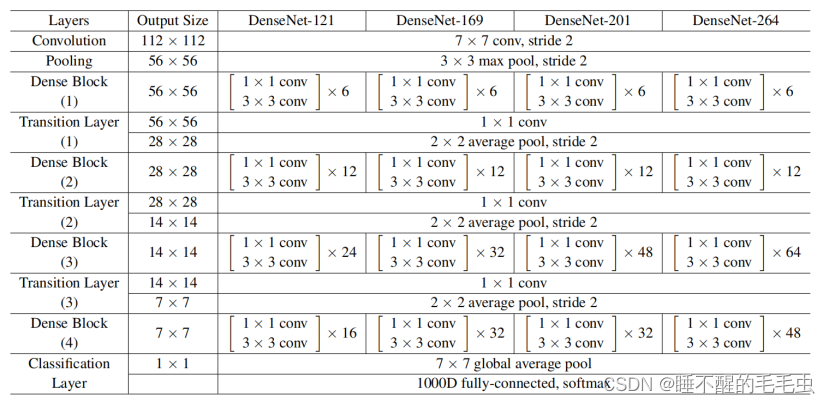
可以看出,一个DenseNet中一般有3个或4个DenseBlock,最后的DenseBlock后连接了一个最大池化层,然后是一个包含1000个类别的全连接层,通过softmax激活函数得到类别属性。
DenseNet部分实现代码
直接上干货
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from collections import OrderedDict__all__ = ["densenet121", "densenet161", "densenet169", "densenet201"]class DenseLayer(nn.Module):def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, memory_efficient = False):super(DenseLayer,self).__init__()self.norm1 = nn.BatchNorm2d(num_input_features)self.relu1 = nn.ReLU(inplace=True)self.conv1 = nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)self.norm2 = nn.BatchNorm2d(bn_size * growth_rate)self.relu2 = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)self.drop_rate = float(drop_rate)self.memory_efficient = memory_efficientdef bn_function(self, inputs):concated_features = torch.cat(inputs, 1)bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features)))return bottleneck_outputdef any_requires_grad(self, input):for tensor in input:if tensor.requires_grad:return Truereturn False@torch.jit.unuseddef call_checkpoint_bottleneck(self, input):def closure(*inputs):return self.bn_function(inputs)return cp.checkpoint(closure, *input)def forward(self, input):if isinstance(input, torch.Tensor):prev_features = [input]else:prev_features = inputif self.memory_efficient and self.any_requires_grad(prev_features):if torch.jit.is_scripting():raise Exception("Memory Efficient not supported in JIT")bottleneck_output = self.call_checkpoint_bottleneck(prev_features)else:bottleneck_output = self.bn_function(prev_features)new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))if self.drop_rate > 0:new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)return new_featuresclass DenseBlock(nn.ModuleDict):def __init__(self,num_layers,num_input_features,bn_size,growth_rate,drop_rate,memory_efficient = False,):super(DenseBlock,self).__init__()for i in range(num_layers):layer = DenseLayer(num_input_features + i * growth_rate,growth_rate=growth_rate,bn_size=bn_size,drop_rate=drop_rate,memory_efficient=memory_efficient,)self.add_module("denselayer%d" % (i + 1), layer)def forward(self, init_features):features = [init_features]for name, layer in self.items():new_features = layer(features)features.append(new_features)return torch.cat(features, 1)class Transition(nn.Sequential):"""Densenet Transition Layer:1 × 1 conv2 × 2 average pool, stride 2"""def __init__(self, num_input_features, num_output_features):super(Transition,self).__init__()self.norm = nn.BatchNorm2d(num_input_features)self.relu = nn.ReLU(inplace=True)self.conv = nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False)self.pool = nn.AvgPool2d(kernel_size=2, stride=2)class DenseNet(nn.Module):def __init__(self,growth_rate = 32,num_init_features = 64,block_config = None,num_classes = 1000,bn_size = 4,drop_rate = 0.,memory_efficient = False,):super(DenseNet,self).__init__()# First convolutionself.features = nn.Sequential(OrderedDict([("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),("norm0", nn.BatchNorm2d(num_init_features)),("relu0", nn.ReLU(inplace=True)),("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),]))# Each denseblocknum_features = num_init_featuresfor i, num_layers in enumerate(block_config):block = DenseBlock(num_layers=num_layers,num_input_features=num_features,bn_size=bn_size,growth_rate=growth_rate,drop_rate=drop_rate,memory_efficient=memory_efficient,)self.features.add_module("denseblock%d" % (i + 1), block)num_features = num_features + num_layers * growth_rateif i != len(block_config) - 1:trans = Transition(num_input_features=num_features, num_output_features=num_features // 2)self.features.add_module("transition%d" % (i + 1), trans)num_features = num_features // 2# Final batch normself.features.add_module("norm5", nn.BatchNorm2d(num_features))# Linear layerself.classifier = nn.Linear(num_features, num_classes)# Official init from torch repo.for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.constant_(m.bias, 0)def forward(self, x):features = self.features(x)out = F.relu(features, inplace=True)out = F.adaptive_avg_pool2d(out, (1, 1))out = torch.flatten(out, 1)out = self.classifier(out)return outdef densenet121(num_classes):"""Densenet-121 model"""return DenseNet(32, 64, (6, 12, 24, 16),num_classes=num_classes)def densenet161(num_classes):"""Densenet-161 model"""return DenseNet(48, 96, (6, 12, 36, 24), num_classes=num_classes)def densenet169(num_classes):"""Densenet-169 model"""return DenseNet(32, 64, (6, 12, 32, 32), num_classes=num_classes)def densenet201(num_classes):"""Densenet-201 model"""return DenseNet(32, 64, (6, 12, 48, 32), num_classes=num_classes)if __name__=="__main__":# from torchsummaryX import summarydevice = 'cuda' if torch.cuda.is_available() else 'cpu'input = torch.ones(2, 3, 224, 224).to(device)net = densenet121(num_classes=4)net = net.to(device)out = net(input)print(out)print(out.shape)# summary(net, torch.ones((1, 3, 224, 224)).to(device))
希望对大家能够有所帮助呀!
这篇关于分类神经网络3:DenseNet模型复现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








