本文主要是介绍CV预测:快速使用DenseNet神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI预测相关目录
AI预测流程,包括ETL、算法策略、算法模型、模型评估、可视化等相关内容
最好有基础的python算法预测经验
- EEMD策略及踩坑
- VMD-CNN-LSTM时序预测
- 对双向LSTM等模型添加自注意力机制
- K折叠交叉验证
- optuna超参数优化框架
- 多任务学习-模型融合策略
- Transformer模型及Paddle实现
- 迁移学习在预测任务上的tensoflow2.0实现
- holt提取时序序列特征
- TCN时序预测及tf实现
- 注意力机制/多头注意力机制及其tensorflow实现
- 一文解析AI预测数据工程
- FITS:一个轻量级而又功能强大的时间序列分析模型
- DLinear:未来预测聚合历史信息的最简单网络
- LightGBM:更好更快地用于工业实践集成学习算法
- 面向多特征的AI预测指南
- 大模型时序预测初步调研【20240506】
- Time-LLM :超越了现有时间序列预测模型的学习器
- CV预测:快速使用LeNet-5卷积神经网络
- CV预测:快速使用ResNet深度残差神经网络并创建自己的训练集
- CV预测:快速使用DenseNet神经网络
文章目录
- AI预测相关目录
- DenseNet简介
- 代码
DenseNet简介
DenseNet在ResNet基础上做出了改进,其主要优势点如下:
- 1.提出了稠密连接的思想。将一个稠密块中的所有层直接相互连接,确保了网络中各层之间最大的信息流。同时减轻了梯度弥散的问题,增强了特征传播,鼓励了特征重用。
- 2.采用了过渡层进行下采样。这一点和ResNet有明显的区别。
- 3.提出了增长率k,指的是每个瓶颈层H,产生的特征图个数。相对较小的增长率(比如K=12)就足以在测试的数据集上获得最先进的结果。
- 4.每个稠密块之后,使用压缩因子0对特征图通道数进行压缩。
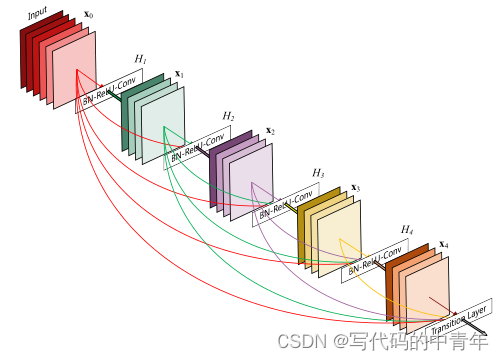
基本设计如上图所示:
传统的卷积神经网络:将第1- 1层的输出作为第1层的输入,用公式可表示为: x= H(x1-1)
深度残差网络ResNet:ResNets添加了一个捷径连接,该连接使用恒等映射绕过了非线性变换H用公式可表示为:x= H(x-1)+ x1-1
稠密卷积网络DenseNet:为了进一步改善各层之间的信息流,提出了一种不同的连接模式–稠密连接:引入了从任何层到所有后续层的直接连接。该网络以前馈方式将每一层连接到其他每一层。对于每一层,所有先前层的特征图都用作输入,而其自身的特征图则用作所有后续层的输入。这种连接方式确保了网络中各层之间最大的信息流。
稠密连接的优点:
1.减轻了梯度弥散,增强了特征传播,鼓励了特征重用
2.在整个网络中改善了信息流和梯度,使得模型更易于训练
3.稠密连接具有正则化效果,减少了训练集较小任务的过度拟合
代码
MODEL
import tensorflow as tf
from tensorflow.keras import layers# 瓶颈层,相当于每一个稠密块中若干个相同的H函数
class BottleNeck(layers.Layer):# growth_rate对应的是论文中的增长率k,指经过一个BottleNet输出的特征图的通道数;drop_rate指失活率。def __init__(self, growth_rate, drop_rate):super(BottleNeck, self).__init__()self.bn1 = layers.BatchNormalization()self.conv1 = layers.Conv2D(filters=4 * growth_rate, # 使用1*1卷积核将通道数降维到4*kkernel_size=(1, 1),strides=1,padding="same")self.bn2 = layers.BatchNormalization()self.conv2 = layers.Conv2D(filters=growth_rate, # 使用3*3卷积核,使得输出维度(通道数)为kkernel_size=(3, 3),strides=1,padding="same")self.dropout = layers.Dropout(rate=drop_rate)# 将网络层存入一个列表中self.listLayers = [self.bn1,layers.Activation("relu"),self.conv1,self.bn2,layers.Activation("relu"),self.conv2,self.dropout]def call(self, x):y = xfor layer in self.listLayers.layers:y = layer(y)# 每经过一个BottleNet,将输入和输出按通道连结。作用是:将前l层的输入连结起来,作为下一个BottleNet的输入。y = layers.concatenate([x, y], axis=-1)return y# 稠密块,由若干个相同的瓶颈层构成
class DenseBlock(layers.Layer):# num_layers表示该稠密块存在BottleNet的个数,也就是一个稠密块的层数Ldef __init__(self, num_layers, growth_rate, drop_rate=0.5):super(DenseBlock, self).__init__()self.num_layers = num_layersself.growth_rate = growth_rateself.drop_rate = drop_rateself.listLayers = []# 一个DenseBlock由多个相同的BottleNeck构成,我们将它们放入一个列表中。for _ in range(num_layers):self.listLayers.append(BottleNeck(growth_rate=self.growth_rate, drop_rate=self.drop_rate))def call(self, x):for layer in self.listLayers.layers:x = layer(x)return x# 过渡层
class TransitionLayer(layers.Layer):# out_channels代表输出通道数def __init__(self, out_channels):super(TransitionLayer, self).__init__()self.bn = layers.BatchNormalization()self.conv = layers.Conv2D(filters=out_channels,kernel_size=(1, 1),strides=1,padding="same")self.pool = layers.MaxPool2D(pool_size=(2, 2), # 2倍下采样strides=2,padding="same")def call(self, inputs):x = self.bn(inputs)x = tf.keras.activations.relu(x)x = self.conv(x)x = self.pool(x)return x# DenseNet整体网络结构
class DenseNet(tf.keras.Model):# num_init_features:代表初始的通道数,即输入稠密块时的通道数# growth_rate:对应的是论文中的增长率k,指经过一个BottleNet输出的特征图的通道数# block_layers:每个稠密块中的BottleNet的个数# compression_rate:压缩因子,其值在(0,1]范围内# drop_rate:失活率def __init__(self, num_init_features, growth_rate, block_layers, compression_rate, drop_rate):super(DenseNet, self).__init__()# 第一层,7*7的卷积层,2倍下采样。self.conv = layers.Conv2D(filters=num_init_features,kernel_size=(7, 7),strides=2,padding="same")self.bn = layers.BatchNormalization()# 最大池化层,3*3卷积核,2倍下采样self.pool = layers.MaxPool2D(pool_size=(3, 3), strides=2, padding="same")# 稠密块 Dense Block(1)self.num_channels = num_init_featuresself.dense_block_1 = DenseBlock(num_layers=block_layers[0], growth_rate=growth_rate, drop_rate=drop_rate)# 该稠密块总的输出的通道数self.num_channels += growth_rate * block_layers[0]# 对特征图的通道数进行压缩self.num_channels = compression_rate * self.num_channels# 过渡层1,过渡层进行下采样self.transition_1 = TransitionLayer(out_channels=int(self.num_channels))# 稠密块 Dense Block(2)self.dense_block_2 = DenseBlock(num_layers=block_layers[1], growth_rate=growth_rate, drop_rate=drop_rate)self.num_channels += growth_rate * block_layers[1]self.num_channels = compression_rate * self.num_channels# 过渡层2,2倍下采样,输出:14*14self.transition_2 = TransitionLayer(out_channels=int(self.num_channels))# 稠密块 Dense Block(3)self.dense_block_3 = DenseBlock(num_layers=block_layers[2], growth_rate=growth_rate, drop_rate=drop_rate)self.num_channels += growth_rate * block_layers[2]self.num_channels = compression_rate * self.num_channels# 过渡层3,2倍下采样self.transition_3 = TransitionLayer(out_channels=int(self.num_channels))# 稠密块 Dense Block(4)self.dense_block_4 = DenseBlock(num_layers=block_layers[3], growth_rate=growth_rate, drop_rate=drop_rate)# 全局平均池化,输出size:1*1self.avgpool = layers.GlobalAveragePooling2D()# 全连接层,进行10分类self.fc = layers.Dense(units=10, activation=tf.keras.activations.softmax)def call(self, inputs):x = self.conv(inputs)x = self.bn(x)x = tf.keras.activations.relu(x)x = self.pool(x)x = self.dense_block_1(x)x = self.transition_1(x)x = self.dense_block_2(x)x = self.transition_2(x)x = self.dense_block_3(x)x = self.transition_3(x,)x = self.dense_block_4(x)x = self.avgpool(x)x = self.fc(x)return xdef densenet():return DenseNet(num_init_features=64, growth_rate=32, block_layers=[2,2,2,2], compression_rate=0.5, drop_rate=0.5)# return DenseNet(num_init_features=64, growth_rate=32, block_layers=[4, 4, 4, 4], compression_rate=0.5, drop_rate=0.5)
mynet=densenet()
TRAIN
import tensorflow as tf
from model import mynet
import matplotlib.pyplot as plt# 数据集准备
# (x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = x_train.reshape((60000, 28, 28, 1)).astype('float32') / 255
x_test = x_test.reshape((10000, 28, 28, 1)).astype('float32') / 255mynet.compile(loss='sparse_categorical_crossentropy',optimizer=tf.keras.optimizers.SGD(),metrics=['accuracy'])history = mynet.fit(x_train, y_train,batch_size=64,epochs=5,validation_split=0.2)
# test_scores = mynet.evaluate(x_test, y_test, verbose=2)plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.legend(['training', 'validation'], loc='upper left')
plt.show()
这篇关于CV预测:快速使用DenseNet神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





