本文主要是介绍常见卷积神经网络总结:Densenet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
常见卷积神经网络总结
- DenseNet
最近时间没那么紧张了,准备把之前没看的论文总结一下,
DenseNet
DenseNet是CVPR2017的最佳论文,可见这篇论文还是很厉害的,DenseNet主要是借鉴了Resnet的思想,采取了一种全新的网络连接方式,最近的卷积神经网络主要是从深度和宽度上进行思考的,加深宽度或者加深深度,但这篇文章另辟蹊径,采取了一种新的结构,取得了很好地效果。
首先来看一下整个网络的结构,如下图所示,借鉴了Resnet的思想,Resnet是将输入和输出进行shortcut连接,而DenseNet可以看成是Resnet的极限形式,在同一个denseblock中,每一层的输入是之前所有层的输出。下图为Densenet中一个Denseblock的形状。

对比DenseNet和Resnet的公式,更有助于理解DenseNet:
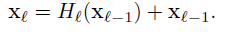
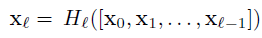
Resnet的输出是上一层的输出加上这一层非线性变换之后的输出,而DenseNet某一层的输入是0~l-1层的输出的concat。这里需要注意,Resnet是做的加法,而Densenet的输入是concat,channel的数量不变。并且,在Densenet中,非线性变换的顺序是BN,ReLu,卷积。
Densenet的优点是网络更窄,参数少,每个卷积层输出的featuremap数都很小。另外这种连接方式使得特征和梯度的传递更加有效,网络也更加容易训练。由于全连接和紧密的连接,梯度可以轻易的从loss传递到任意一层,减轻了梯度消失的问题。另外这种denseconnection还有定的抑制过拟合的作用。
下图是Densenet的结构图

Densenet分为多个denseblock,各个Denseblock内的featuremap的size统一,这样做concat不会用size问题。

Table1为网络的结构图,k为growth rate,表示每个denseblock中每层输出的feature map的个数,作者采用的k都比较小,可见Densenet的参数量并不是很大,根据denseblock的设计,每个层的输入是前面层输出的concat,所以输入的channel还是很大的。在每个3×3的卷积前面,都存在1×1的卷积操作,这就是bottleneck layer,目的是减少输入的feature map数量,既能降维减少参数计算量,又能融合各个通道的信息。另外,另一个增加参数的方式是在两个denseblock之间加了transition layer,该层的1×1的卷积输出channel默认是输入channel的一半。
以Densenet169为例,包含32个层,每层的输入是之前层输出的concat,如果不做bottleneck,每层输出是32channel,concat之后最后的层输入都达到上千了,而1×1卷积将channel变为growth rate*4。在transition layer中,是放在两个denseblock之间的,因为上一个block的最后一层虽然只有32层输出,但是还会concat之前所有层的输出,所有channel数还是很大的,因此需要用1×1的卷积来降维,transition lay降维的比例reduction是0.5(默认)
总结:Densenet的核心思想在于在不同层之间建立连接关系,充分利用了特征,同时减少了梯度消失的问题,另外利用bottleneck结构和transition layer以及较小的channel数以减少参数,参数减少,有效抑制了过拟合。
这篇关于常见卷积神经网络总结:Densenet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


