本文主要是介绍【openGL4.x手册03】更加深刻、前瞻的顶点渲染,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录标题
- 一、说明
- 二、先决条件
- 2.1 渲染失败的原因
- 三、常见情况
- 3.1 原始重启
- 3.2 修复索引重启
- 四、直接渲染
- 4.1 基本绘图
- 4.1.1 glDrawArrays函数
- 4.1.2 glDrawElements
- 4.1.3 还有多个函数可以研究
- 4.2 多次绘制
- 4.3 基本索引
- 4.4 实例化
- 4.5 范围
- 4.6 组合
- 五、变换反馈渲染
- 5.1 变换反馈渲染
- 六、 间接渲染
- 七、条件渲染

一、说明
本页介绍顶点的绘制函数。如果您正在寻找有关如何定义此顶点数据来自何处的信息,请参阅顶点规范。顶点渲染是获取数组中指定的顶点数据并使用该顶点数据渲染一个或多个图元的过程。
二、先决条件
主条目:顶点规范
为了成功发出绘图命令,当前绑定的顶点数组对象必须已使用顶点属性数组正确设置,如此处定义。如果要使用索引渲染,则VAO 中的GL_ELEMENT_ARRAY_BUFFER绑定也必须绑定 一个缓冲区对象。
2.1 渲染失败的原因
由于多种原因,发出任何绘图命令时都可能会发生 GL_INVALID_OPERATION错误,其中大多数与实际绘图命令本身关系不大。以下表示发出绘图命令时必须确保有效的条件。
必须绑定非零顶点数组对象(尽管不必启用任何数组,因此它可以是新创建的顶点数组对象)。
当前帧缓冲区必须完整。默认帧缓冲区(如果存在)始终是完整的,因此这通常发生在帧缓冲区对象上。
当前程序对象或程序管道对象必须已成功链接并且对于当前状态有效。这包括:
- 如果存在活动的曲面细分评估着色器或几何着色器,则还必须存在活动的顶点着色器。
- 任何活动程序都不能具有与同一纹理图像单元关联的两个或多个不同类型的采样器变量。
- 任何活动程序不能有两个或多个与同一图像单元关联的不同类型的图像变量。
- 程序管道对象有附加规则。在统一程序的情况下,这些都将是链接器错误,但程序管道必须在渲染时检查:
- 来自一个程序对象的程序不能位于由不同程序对象定义的两个着色器阶段之间。因此,如果您的程序 A 具有顶点和片段着色器,则您无法将程序 B 放入管道中,并且它们之间有几何着色器。
- 所有图像中的活动采样器、图像、统一缓冲区和着色器存储缓冲区(如果适用)的数量不得超过实现定义的组合限制。这是由非单独程序的链接器静态检查的,但必须使用程序管道进行渲染时检查。
- 如果存在几何着色器和曲面细分评估着色器并且未链接到同一程序,则GS 的输入图元类型必须与TES 的补丁输出类型生成的图元匹配。
- 如果曲面细分控制着色器处于活动状态,则曲面细分评估着色器也必须处于活动状态。
- 当前程序的采样器和/或图像使用的纹理必须完整。
- 如果存在几何着色器,则馈送到 GS 的图元类型必须与 GS 的图元输入兼容。如果没有 TES 处于活动状态,则绘图命令中的模式图元类型必须匹配。
- 如果变换反馈处于活动状态,则变换反馈模式必须与适用的基元模式匹配。该模式确定如下:
- 如果几何着色器处于活动状态,则适用的图元模式是GS 的输出图元类型。
- 如果没有 GS 处于活动状态,但曲面细分评估着色器处于活动状态,则适用的图元模式是 TES 的输出图元类型。
- 否则,适用的图元类型是提供给绘图命令的图元模式。
- 当且仅当曲面细分评估着色器处于活动状态时,模式可以是GL_PATCHS。反之亦然。
- OpenGL 渲染调用读取或写入的缓冲区对象不得以非持久方式映射。这包括但不限于:
属性或索引数据的缓冲区边界。 - 当变换反馈处于活动状态时,缓冲区绑定为变换反馈。
- 当任何着色器从该缓冲区读取(或写入)时,该缓冲区将绑定到uniforms、着色器存储或原子计数器。
- 绑定为纹理或图像加载存储图像的缓冲区。
- 该列表并不全面。如果您知道更多,请在此处添加。
注意:不使用程序或程序管道进行渲染不会产生GL_INVALID_OPERATION错误。相反,这是未定义的行为。
三、常见情况
渲染可以以非索引渲染或索引渲染的方式进行。索引渲染使用元素缓冲区来决定从顶点数组中的哪个索引提取值。顶点规范文章对此进行了更详细的解释。
所有非索引绘图命令均采用glDrawArrays形式,其中值可以用不同的单词填充。所有索引绘图命令的形式均为glDrawElements*。
3.1 原始重启
基元重启功能允许您告诉 OpenGL 特定的索引值意味着,不要在该索引处获取顶点,而是从下一个顶点开始一个相同类型的新基元。本质上,它是glMultiDrawElements的替代品(见下文)。这允许您拥有一个包含多个三角形带或扇形(或基元的开始/结束具有特殊行为的类似基元)的元素缓冲区。
它的工作方式是使用函数glPrimitiveRestartIndex。该函数采用一个索引值。如果在索引数组中找到该索引,系统将不会获取顶点;相反,它将再次开始图元处理,就像发出了第二个绘图命令一样。如果您使用BaseVertex 绘图函数,则此测试是在将基础索引添加到重新启动之前完成的。使用该功能还需要使用glEnable(GL_PRIMITIVE_RESTART)来激活它,并使用相应的glDisable来关闭它。
这是一个例子。假设您有一个索引数组,如下所示:
{ 0 1 2 3 65535 2 3 4 5 }
如果通常将其渲染为三角形带,则会得到 7 个三角形。如果你在启用glPrimitiveRestartIndex(65535)和GL_PRIMITIVE_RESTART的情况下渲染它,那么你将得到 4 个三角形:
{0 1 2}、{1 2 3}、{2 3 4}、{3 4 5}
原始重启适用于任何索引渲染函数。即使是间接的。
注意: OpenGL 4.4 及更低版本定义了基元重新启动以使用所有绘图命令,包括非索引命令。然而,实现并没有实现这一点,并且规则本身没有任何意义,因此 GL 4.5 指定(OpenGL 4.5,第 10.6.3 节,第 342 页)重新启动状态对非索引绘图命令没有影响。
3.2 修复索引重启
原始重启固定索引
版本核心 4.6
核心自版本 4.3
核心ARB扩展 ARB_ES3_兼容性
为了与 OpenGL ES 3.0 兼容,OpenGL 4.3 允许使用GL_PRIMITIVE_RESTART_FIXED_INDEX。这个枚举器可以被启用和禁用,就像GL_PRIMITIVE_RESTART一样。如果两者都启用,则固定索引重新启动优先于用户指定的索引。
与常规重启不同,固定索引版本使用特定索引。即,索引绘图命令的类型可能的最大索引。因此,如果类型为GL_UNSIGNED_SHORT,则重新启动索引将为 65535 或 0xFFFF。
注意:在 OpenGL 4.5 之前,常规基元重新启动和固定索引重新启动之间存在另一个(技术)差异。也就是说,如果启用GL_PRIMITIVE_RESTART_FIXED_INDEX ,则数组绘制命令不会使用重新启动。如上所述,这在 GL 4.5 之前的版本中有所不同,因为数组渲染将遵循重新启动索引(尽管没有实现实际上支持这一点)。
兼容性注意:在兼容性配置文件中使用此功能时,仅当您使用实际采用类型的索引绘图命令之一时,才会使用重新启动索引。 因此,如果您通过glArrayElement对数组使用立即模式,那么根本不会有原始重新启动。同样,固定索引重启行为优先。
四、直接渲染
这些顶点绘制命令直接提供各种渲染参数作为传递给函数的参数。这与其他绘图命令(请参阅后面的部分)形成对比,其中一些参数是从 OpenGL 对象源中提取的。
4.1 基本绘图
基本绘图函数如下:
void glDrawArrays (GLenum mode, GLint first, GLsizei count) ;
void glDrawElements (GLenum mode, GLsizei number, GLenum type, void *index)
4.1.1 glDrawArrays函数
mode参数是Primitive类型。
GLint first 和GLsizei count计数值定义要从缓冲区中提取的元素的范围。
glDrawArrays 通过很少的子例程调用来指定多个几何基元。您可以预先指定单独的顶点、法线和颜色数组,并使用它们通过一次调用 glDrawArrays 来构造基元序列,而不是调用 GL 过程来传递每个单独的顶点、法线、纹理坐标、边缘标志或颜色。
当调用 glDrawArrays 时,它使用每个启用数组中的 count 个顺序元素来构造几何图元序列,首先从元素开始。模式指定构造什么类型的基元以及数组元素如何构造这些基元。
glDrawArrays 修改的顶点属性在 glDrawArrays 返回后具有未指定的值。未修改的属性仍保持良好定义。
| mode 选项: | – |
|---|---|
| GL_POINTS, | 散点 |
| GL_LINE_STRIP, | 条连线 |
| GL_LINE_LOOP | 循环连线 |
| GL_LINES | 线连 |
| GL_LINE_STRIP_ADJACENCY | |
| GL_LINES_ADJACENCY | 最近邻连接 |
| GL_TRIANGLE_STRIP | 三角环联 |
| GL_TRIANGLE_FAN | 三角伞形 |
| GL_TRIANGLES | 三角形 |
| GL_TRIANGLE_STRIP_ADJACENCY | 三角近邻环 |
| GL_TRIANGLES_ADJACENCY | 近邻三角 |
| GL_PATCHES | 路径 |
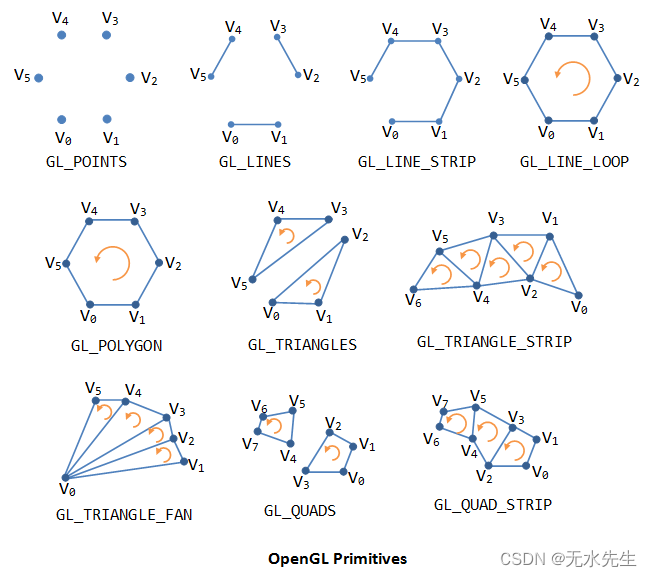
4.1.2 glDrawElements
glDrawElements 通过很少的子例程调用来指定多个几何基元。您可以预先指定单独的顶点、法线等数组,并使用它们通过一次调用构造基元序列,而不是调用 GL 函数来传递每个单独的顶点、法线、纹理坐标、边缘标志或颜色到 glDrawElements。
当调用 glDrawElements 时,它使用启用数组中的 count 个顺序元素,从索引开始构造几何图元序列。模式指定构造什么类型的基元以及数组元素如何构造这些基元。如果启用了多个阵列,则使用每个阵列。
glDrawElements 返回后,由 glDrawElements 修改的顶点属性具有未指定的值。未修改的属性保留其先前的值。
void glDrawElements(
GLenum mode,
GLsizei count,
GLenum type,
const void * indices);
- count和indices参数 定义索引的范围。count 定义要使用的索引数量。
- Index 定义索引缓冲区对象的偏移量(绑定到GL_ELEMENT_ARRAY_BUFFER,存储在 VAO 中)以开始读取数据。
- type 字段 描述了索引的类型:
GL_UNSIGNED_BYTE : 索引范围: [0, 255]
GL_UNSIGNED_SHORT : 索引范围: [0, 65535]
GL_UNSIGNED_INT:索引范围:[0, 2 32 - 1]。 - indexs参数是奇数。就像旧式顶点属性一样,它根本不是指针。它实际上是一个字节偏移量,伪装成一个指针。因此,您需要将字节偏移量放入索引缓冲区并将其转换为void*(使用reinterpret_cast<void*>或只是(void*))。
4.1.3 还有多个函数可以研究
glDrawArrays,
glDrawElementsInstanced,
glDrawElementsBaseVertex,
glDrawRangeElements
4.2 多次绘制
为了发送顶点进行渲染,您真正需要的就是基本的绘图函数。但是,有多种绘制方法可以优化某些渲染情况。
使用与上一个绘图命令不同的 VAO 进行渲染通常是一个相对昂贵的操作。许多优化机制都是基于将多个网格体的数据存储在具有相同顶点格式和其他 VAO 数据的相同缓冲区对象中。
绑定 VAO 或修改 VAO 状态通常是一项昂贵的操作。在很多情况下,您希望通过一次绘制调用来渲染多个不同的网格。所有网格必须位于相同的 VAO 中(因此具有相同的缓冲区对象和索引缓冲区)。当然,它们还必须使用具有相同统一值的相同着色器程序。
要一次从 VAO 渲染多个基元,请使用以下命令:
void glMultiDrawArrays( GLenum mode, GLint *first, GLsizei *count, GLsizei primcount);
该函数在概念上实现为:
void glMultiDrawArrays( GLenum mode, GLint *first, GLsizei *count, GLsizei primcount )
{for (int i = 0; i < primcount; i++){if (count[i] > 0)glDrawArrays(mode, first[i], count[i]);}
}
当然,你可以自己编写这个函数。然而,由于这一切都发生在一次 OpenGL 调用中,因此实现有机会对其进行优化,超出您可以编写的范围。
还有一个索引形式:
void glMultiDrawElements( GLenum mode, GLsizei *count, GLenum type, void **indices, GLsizei primcount );
同样,这在概念上实现为:
void glMultiDrawElements( GLenum mode, GLsizei *count, GLenum type, void **indices, GLsizei primcount )
{for (int i = 0; i < primcount; i++){if (count[i]) > 0)glDrawElements(mode, count[i], type, indices[i]);}
}
当您知道要绘制许多使用相同着色器的相同类型的单独图元时,多重绘制非常有用。通常,这将是一个您始终以相同方式绘制在一起的单个概念对象。您只需将所有顶点数据打包到相同的 VAO 和缓冲区对象中,使用各种偏移量在它们之间进行挑选即可。
4.3 基本索引
所有glVertexAttribPointer调用都定义顶点的格式。即顶点数据存储在缓冲区对象中的方式。改变这种格式在性能方面有些昂贵。
如果您有多个共享相同顶点格式的网格体,那么能够将它们一个接一个地放入一组缓冲区对象中将会非常有用。如果我们有两个网格 A 和 B,那么它们的数据将如下所示:
[A00 A01 A02 A03 A04…A nn B00 B01 B02…B毫米]
B 的网格数据紧接着 A 的网格数据,中间没有中断。
glDrawArrays调用需要一个起始索引。如果我们使用无索引渲染,那么这就是我们所需要的。我们调用一次glDrawArrays,以 0 作为起始索引,以nn作为数组计数。然后我们再次调用它,以nn作为起始索引,mm作为数组计数。
索引渲染通常对于节省内存和提高性能非常有用。因此,如果我们在使用索引渲染时能够保留这种性能节省优化,那就太好了。
在索引渲染中,每个网格也有一个索引缓冲区。glDrawElements在索引缓冲区中获取一个偏移量,因此我们可以使用相同的机制来选择要使用的索引集。
问题在于这些索引的内容。网格 B 的第三个顶点在技术上是索引 02。但是,实际索引是由该顶点相对于定义格式的位置的位置确定的。由于我们试图避免重新定义格式,因此格式仍然指向缓冲区的开头。因此网格 B 的第三个顶点实际上位于索引 02 + nn处。
事实上,我们可以通过这种方式将这些索引存储在索引缓冲区中。我们可以遍历网格 B 的所有索引并将nn添加到其中。但我们不必这样做。
相反,我们可以使用这个函数:
void glDrawElementsBaseVertex( GLenum mode, GLsizei count,GLenum type, void *indices, GLint basevertex);
这与glDrawElements 的工作原理相同,只是在从顶点数据中提取之前将basevertex添加到每个索引中。因此,对于网格 A,我们传递 0 的基顶点(或仅使用glDrawElements ),对于网格 B,我们传递nn的基顶点。
注意:与原始 restart结合使用时,重新启动测试发生在将基本索引添加到索引之前。
4.4 实例化
能够在不同位置渲染同一网格的多个副本通常很有用。如果您使用较小的数字(例如 5-20 左右)执行此操作,则多个绘制命令之间具有着色器统一更改(以判断哪个命令位于哪个位置)的性能相当快。但是,如果您使用大量网格(例如 5,000 多个左右)执行此操作,则可能会出现性能问题。
实例化是解决这个问题的一种方法。这个想法是,你的顶点着色器有一些内部机制来根据单个数字来决定渲染网格的每个实例的去向。也许它有一个表(存储在Buffer Texture或Uniform Buffer Object中),它使用当前顶点的实例编号进行索引,以获取所需的每个实例数据。也许它对某些属性使用属性除数,为每个实例提供不同的值。或者它可能有一个简单的算法来根据实例编号计算实例的位置。
无论采用何种机制,如果您想要进行实例化渲染,请调用:
void glDrawArraysInstanced( GLenum mode, GLint first,GLsizei count, GLsizei instancecount );void glDrawElementsInstanced( GLenum mode, GLsizei count, GLenum type, const void *indices, GLsizei instancecount );
它将发送相同的顶点实例计数次数,就好像您在实例计数长度的循环中调用glDrawArrays/Elements一样。然而,顶点着色器被赋予一个特殊的输入值:gl_InstanceID。它将根据正在渲染的网格实例接收半开范围 [0, instancecount )上的值。gl_InstanceID和使用实例化属性数组是能够区分实例的唯一机制。
在 OpenGL 4.2 或ARB_base_instance中,可以使用“BaseInstance”命令指定起始实例,如下所示:
void glDrawArraysInstancedBaseInstance( GLenum mode, GLint first,GLsizei count, GLsizei instancecount, GLuint baseinstance );void glDrawElementsInstancedBaseInstance( GLenum mode, GLsizei count, GLenum type, const void *indices, GLsizei instancecount, GLuint baseinstance );
基实例指定第一个实例。instancecount仍然代表实例的数量。属性除数使用的实例受基本实例的影响。也就是说,它从基本实例开始,每个实例加 1。所以基础实例会影响属性除数。
警告:输入gl_InstanceID 不遵循基本实例。 gl_InstanceID始终落在半开范围 [0, instancecount )内。因此,基本实例仅在使用实例化数组时才有用。使用 OpenGL 4.6或ARB_shader_draw_parameters,您可以访问gl_BaseInstance,它是渲染命令中使用的基本实例值。
4.5 范围
OpenGL 的实现通常会发现了解缓冲区对象中使用了多少顶点数据很有用。对于非索引渲染,这很容易确定:Arrays 函数的第一个和计数参数为您提供了适当的信息。对于索引渲染,这更加困难,因为索引缓冲区可以使用不超过其大小的任何索引。
仍然出于优化目的,实现了解索引渲染数据的范围很有用。实现方式甚至可以手动读取索引数据来确定这一点。
glDrawElements命令的“Range”系列允许用户指定此索引渲染调用永远不会导致获取给定值范围之外的索引。该调用的工作原理如下:
void glDrawRangeElements( GLenum mode, GLuint start, GLuint end, GLsizei count, GLenum type, void *indices );
与“Arrays”函数不同,start和end参数指定此绘制调用将使用的最小和最大索引值(来自元素缓冲区)(而不是第一个和计数样式)。如果您尝试违反此限制,您将得到实现行为(即:渲染可能正常工作,否则可能会得到垃圾)。
在由start 和end 限定的区域之外允许有一个索引:原始重启索引。如果设置并启用原始重启,则它不必在给定的边界内。
实现可能对索引范围有一个特定的“最佳点”,使得使用该范围内的索引将具有更好的性能。他们使用一对glGetIntegerv枚举器公开此类值。为了获得最佳性能,end - start 应小于或等于GL_MAX_ELEMENTS_VERTICES,并且count (渲染的索引数)应小于或等于GL_MAX_ELEMENTS_INDICES。
4.6 组合
结合这些优化技术通常很有用。原始重启可以与其中任何一个结合使用,只要它们使用索引渲染即可。在 BaseVertex 调用的情况下,基元重新启动比较测试是在将基础索引添加到网格中的索引 之前完成的。
基础顶点可以与 MultiDraw、Range 或 Instancing 中的任何一种组合。这些功能是:
void glMultiDrawElementsBaseVertex ( GLenum mode ,GLsizei *count, GLenum type, void **index,GLsizei primcount , GLint * basevertex ) ;
void glDrawRangeElementsBaseVertex ( GLenum mode ,GLuint start、 GLuint end、 GLsizei coint、 GLenum type、void *index, GLint * basevertex) ;
void glDrawElementsInstancedBaseVertex ( GLenum mode ,GLsizei count, GLenum type, const void * index,GLsizei instance_count、 GLint * basevertex) ;
在 MultiDraw 的情况下,basevertex参数 是一个数组,因此每个图元都可以有自己的基本索引。
BaseVertex 和实例化也可以与 OpenGL 4.2 中的 BaseInstance或ARB_base_instance结合使用,从而产生大量命名的:
void glDrawElementsInstancedBaseVertexBaseInstance( GLenum mode, GLsizei count, GLenum type, const void *indices, GLsizei instancecount, GLint basevertex, GLuint baseinstance);
其他功能均不能相互组合。所以 Range 不与 MultiDraw 结合使用。
五、变换反馈渲染
5.1 变换反馈渲染
版本核心 4.6
核心自版本 4.0
核心ARB扩展 ARB_transform_feedback2、ARB_transform_feedback3、ARB_transform_feedback_instanced
当使用变换反馈生成用于渲染的顶点时,您通常使用异步查询对象来获取图元的数量,然后在适当的情况下 使用该数字来计算glDrawArrays或glDrawArraysInstanced调用的顶点数量。
然而,为此使用查询对象需要 GPU->CPU->GPU 传输信息。您必须从 CPU 上的查询对象中读取信息,然后将该信息传输到绘图调用。
此功能允许绕过此功能。这些函数允许用户绘制在变换反馈操作期间渲染的所有内容,而 CPU 无需显式读回该值。
注意:这些函数唯一做的就是发出渲染调用。它们不绑定变换反馈缓冲区。它们不会修改任何VAO 状态。从变换反馈对象中提取的唯一内容是渲染到该流的图元数量。您有责任在进行这些调用之前设置用于实际渲染的顶点数组。
要从变换反馈对象执行非实例渲染,请使用以下函数:
void glDrawTransformFeedback(GLenum mode, GLuint id);
void glDrawTransformFeedbackStream(GLenum mode, GLuint id, GLuint stream);
mode是通常的原始类型。id是要从中绘制的变换反馈对象。流是反馈对象中用于获取顶点计数的流。请注意,glDrawTransformFeedback相当于使用零流 调用glDrawTransformFeedbackStream 。
如果 GL 4.2 或 ARB_transform_feedback_instanced 可用,则可以使用这些函数的实例化版本:
void glDrawTransformFeedbackInstanced(GLenum mode, GLuint id, GLsizei instancecount);
void glDrawTransformFeedbackStreamInstanced(GLenum mode, GLuint id, GLuint stream, GLsizei instancecount);
这些函数作为glDrawArraysInstanced。这些没有 BaseInstance 版本。
六、 间接渲染
间接渲染
版本核心 4.6
核心自版本 4.0
核心ARB扩展 ARB_draw_indirect、ARB_multi_draw_indirect、ARB_base_instance
间接渲染是向 OpenGL 发出绘图命令的过程,只不过该命令的大部分参数来自Buffer Object提供的 GPU 存储。例如,glDrawArrays采用基元类型、顶点数和起始顶点。当使用间接绘制命令glDrawArraysIndirect时,起始顶点和要渲染的顶点数将存储在缓冲区对象中。
这样做的目的是允许 GPU 进程填充这些值。这可以是计算着色器、专门设计的几何着色器与变换反馈相结合,或者是 OpenCL/CUDA 进程。这个想法是避免GPU->CPU->GPU往返;GPU 决定渲染的顶点范围。CPU 所做的只是决定何时发出绘图命令,以及该命令使用 哪个原语。
间接渲染函数从当前绑定到GL_DRAW_INDIRECT_BUFFER绑定的缓冲区获取数据。因此,如果没有缓冲区绑定到该绑定,则这些函数中的任何一个都将失败。
所有间接渲染函数都具有以下功能:
- 索引渲染
- 基础顶点(用于索引渲染)
- 实例化渲染
- 基础实例(如果 OpenGL 4.2或ARB_base_instance可用)。不需要渲染多个实例. 因此,它们充当受支持实现的最大功能组合。
对于非索引渲染,与glDrawArraysInstancedBaseInstance的间接等效是这样的:
void glDrawArraysIndirect(GLenum mode, const void *indirect);
模式是通常的原始类型。间接是GL_DRAW_INDIRECT_BUFFER中的偏移量,用于查找数据的开头。
数据的提供就像在具有以下定义的 C 结构体中一样:
typedef struct {
GLuint count;
GLuint instanceCount;
GLuint first;
GLuint baseInstance;
} DrawArraysIndirectCommand;
这表示绘制调用相当于:
glDrawArraysInstancedBaseInstance(mode, cmd->first, cmd->count, cmd->instanceCount, cmd->baseInstance);
注意:如果OpenGL 4.2或ARB_base_instance不可用,则baseInstance字段必须为0或未定义的行为结果。
如果 OpenGL 4.3或ARB_multi_draw_indirect可用,则可以在一次调用中发出多个间接数组绘制命令:
void glMultiDrawArraysIndirect(GLenum mode, const void *indirect, GLsizei drawcount, GLsizei stride);
drawcount是要发出的间接绘图命令的数量;步幅是从一个绘图命令到下一个绘图命令的字节偏移量。可以设置为零;如果是这样,则假定间接命令数组是紧密支持的(即:16 字节跨度)。步幅必须 是 4 的倍数。
对于索引渲染,与glDrawElementsInstancedBaseVertexBaseInstance的间接等效是这样的:
void glDrawElementsIndirect(GLenum mode, GLenum type, const void *indirect);
mode和type参数的工作方式与常规glDrawElements样式函数中的工作方式相同。与其他间接函数一样,间接函数是GL_DRAW_INDIRECT_BUFFER中的字节偏移量,以查找间接数据结构。
在索引渲染中,结构体定义如下:
typedef struct {
GLuint count;
GLuint instanceCount;
GLuint firstIndex;
GLuint baseVertex;
GLuint baseInstance;
} DrawElementsIndirectCommand;
这表示绘制调用相当于:
glDrawElementsInstancedBaseVertexBaseInstance(mode, cmd->count, type,
cmd->firstIndex * size-of-type, cmd->instanceCount, cmd->baseVertex, cmd->baseInstance);
其中size-of-type 是type 的大小(以字节为单位) 。
注意:如果 OpenGL 4.2或ARB_base_instance不可用,则baseInstance字段必须为 0 或未定义的行为结果。
如果 OpenGL 4.3或ARB_multi_draw_indirect可用,则可以在一次调用中发出多个间接索引绘图命令:
void glMultiDrawElementsIndirect(GLenum mode, GLenum type, const void *indirect, GLsizei drawcount, GLsizei stride);
drawcount是要发出的间接绘图命令的数量;步幅是从一个绘图命令到下一个绘图命令的字节偏移量。可以设置为零;如果是这样,则假定间接命令数组是紧密支持的(即:20 字节跨度)。步幅必须 是 4 的倍数。
七、条件渲染
条件渲染是一种使一个或多个渲染命令的执行以遮挡查询操作的结果为条件的机制。此功能允许您渲染一些廉价的对象,然后使用遮挡查询来查看其中是否有任何可见。如果是,那么您可以渲染昂贵的对象,但如果不是,那么您可以节省时间和性能。
请注意,条件渲染允许有条件地执行 任何 渲染命令,而不仅仅是本页列出的绘图命令。
这是通过以下函数完成的:
glBeginConditionalRender(GLuint id , GLenum mode)
glEndConditionalRender ();
仅当id指定的遮挡条件被测试为 true 时,才会执行在这两个函数的边界内发出的所有渲染命令。对于GL_SAMPLES_PASSED查询,如果样本数不为零,则将其视为 true(因此执行渲染命令)。
可以调节的命令有:
提到的每个功能。IE,所有形式为glDraw或glMultiDraw的函数。
glClear和glClearBuffer。
glDispatchCompute和glDispatchComputeIndirect。
mode参数决定如何执行渲染函数的丢弃。它可以是以下之一:
- GL_QUERY_WAIT : OpenGL会等待查询结果返回,然后决定是否执行渲染命令。这确保了只有在查询失败时渲染命令才会被丢弃。请注意,等待的是 OpenGL,而不是(必然)CPU。
- GL_QUERY_NO_WAIT : OpenGL 无论如何都可以执行渲染命令。它不会等待查看查询测试是否为真。如果查询测试和渲染命令执行之间的时间太短,这用于防止管道停顿。
- GL_QUERY_BY_REGION_WAIT:OpenGL会等待查询结果返回,然后决定是否执行渲染命令。但是,渲染结果将被裁剪为在遮挡查询中实际光栅化的样本。因此,渲染结果永远不会出现在遮挡查询区域之外。
- GL_QUERY_BY_REGION_NO_WAIT:同上,只是它可能不会等到遮挡查询完成。区域剪裁仍然有效。
请注意,这种情况下的“等待”并不意味着glEndConditionalRender本身将在 - CPU 上停止。这意味着在查询返回之前,GPU 不会执行条件渲染范围内的第一个命令。因此CPU将继续处理,但GPU本身可能会出现管道停顿。
这篇关于【openGL4.x手册03】更加深刻、前瞻的顶点渲染的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







