本文主要是介绍2020-Point attention network for semantic segmentation of 3D point clouds,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Point attention network for semantic segmentation of 3D point clouds
Mingtao Fenga, Liang Zhangb, Xuefei Linc, Syed Zulqarnain Gilanid and Ajmal Miand*
年份:2020
期刊:Pattern Recognition
IF:7.196
1、创新
1)通过attention机制实现LAE-Convs 学习丰富的局部信息
2)point-wise spatial attention module学习点之间的上下文信息(全局信息)
这两种方式都是pointnet2缺少的,
1、pointnet2中的局部信息是通过简化版的pointnet实现的,最终聚合方式是采用的max函数,该方法对中心点周围的Kg个邻域点的权重在任意一个特征维度上都是[0,…1,…0]类似的排布。只采用最大的特征,而丢弃了其余的特征。
2、pointnet2没有对S个中心点的局部特征学习他们之间的关系,这对于同一个物体之间的信息没有办法相互加强。
2、具体实现
1)对于LAE-Convs(Local Attention-Edge Convolution)模块,不同于kNN和ballquery的邻域检索方式,采用了
multi-directional search method,在每一个方向内选取一个最近点,如果没有,就重复中心点。
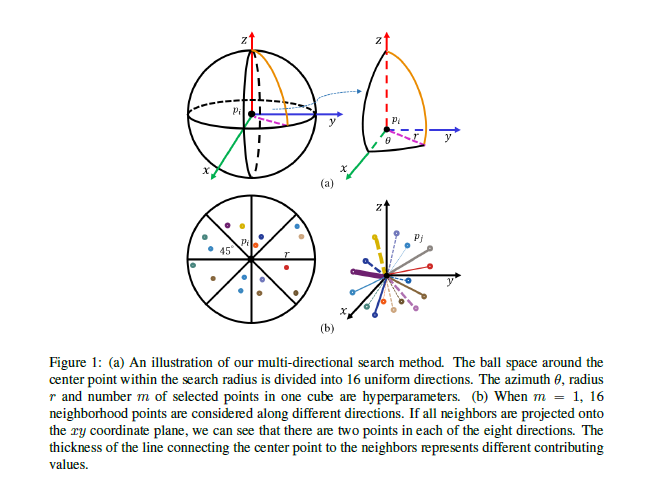
选取完邻域点之后,构建局部坐标系(平移邻域点),然后对每一个邻域点计算一个edge-weight,将16个邻域点的特征(聚合)加权求和到中心点上。
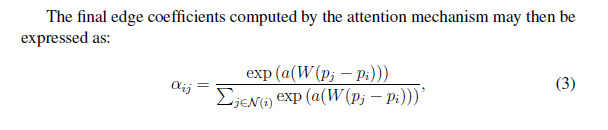
对聚合后的中心点再使用一次MLP,得到一个的local feature
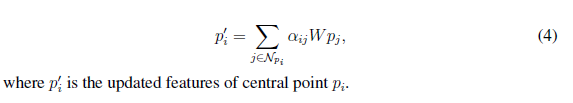
最后在对该local feature进行MLP,得到最终的lcoal feature。
该部分的算法如下:

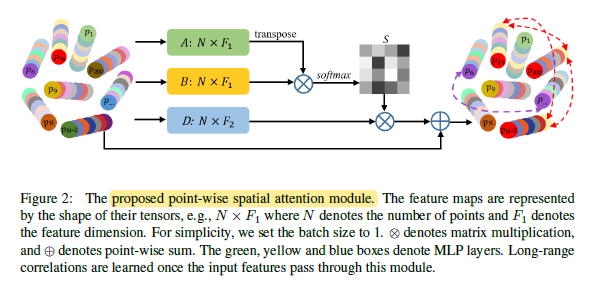
2)对于LAE-Convs输出的特征,都是local feature,这个local feature 很容易被距离所影响,为了加强同一个label的点集之间的关联度,为了获得他们这些local pointcloud的感受野之间的信息,也就是global信息,作者提出了一种point-wise spatial attention module以获取长距离之间的信息,使得feature不再受距离的影响。
流程如下,可以看到这是一个标准的attention模型,前两个代表Q、K,第三个代表V,通过计算Q和K之间的相识度,来更新V的值。
相识度计算:
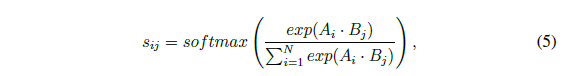
最终的特征计算:

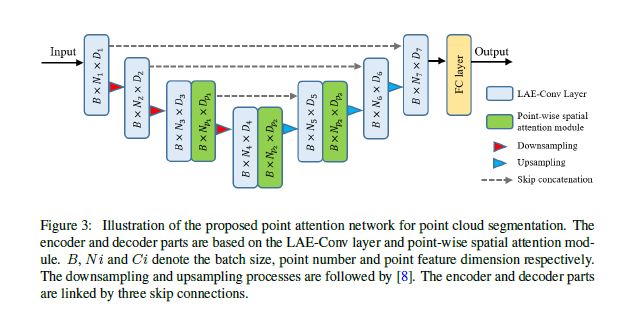
3)网络结构:
还是经典的encoder-decoder模型
3、实验结果
1、Scan Net
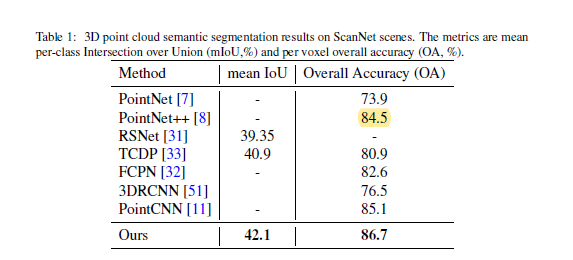
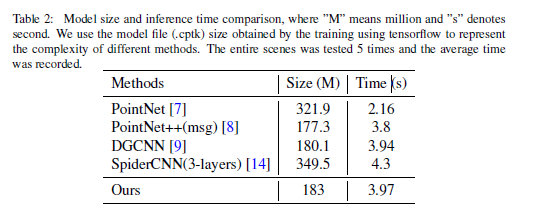
- 消融实验

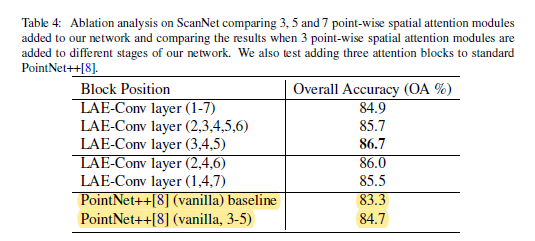
2、S3DIS
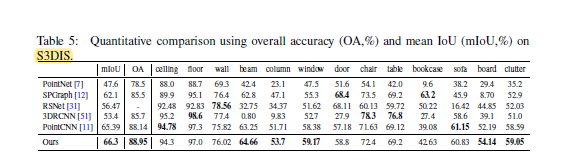
3、ShapeNet
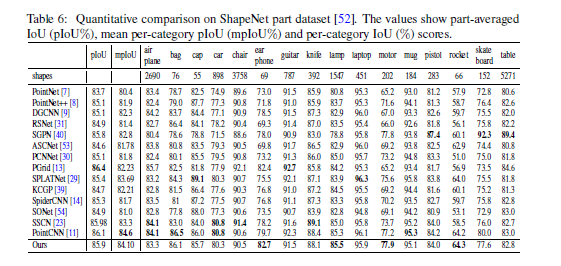
3、ShapeNet
这篇关于2020-Point attention network for semantic segmentation of 3D point clouds的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







