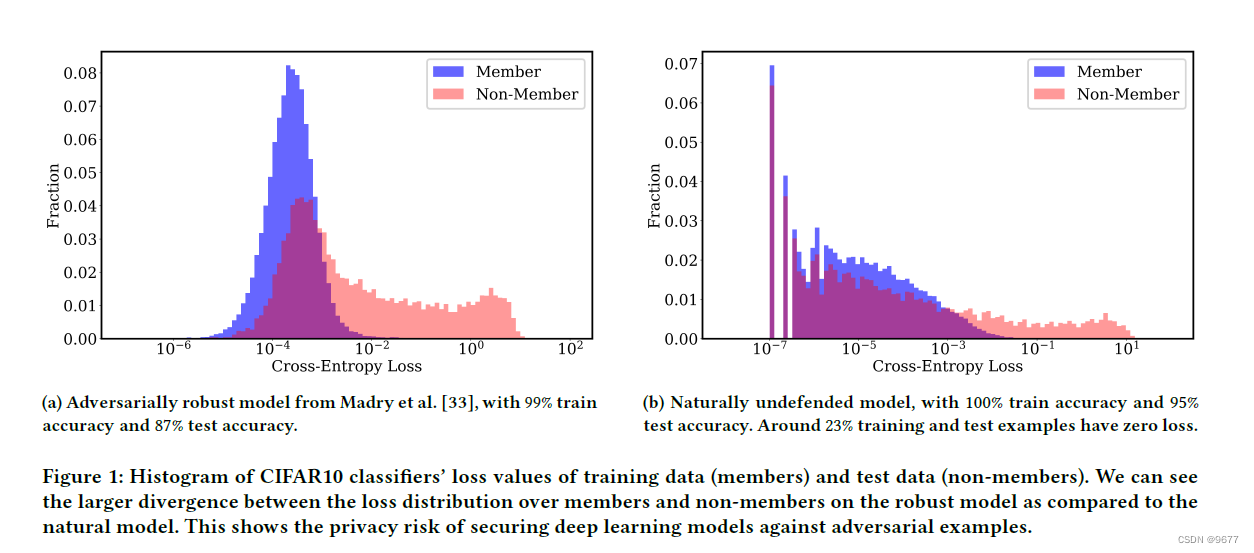
本文主要是介绍熵-entropy,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
熵用于度量空间大小,这里只考虑函数类 G
设 Q 为空间
可以记 ||g||pp,Q=∫|g|pdQ , g∈Lp(Q)
Lp(Q) 距离下的熵:
对于 δ>0 ,存在函数集 {g1,g2,...,gN} s.t.对任意的 g∈G 存在 j∈{1,2,...,N} 使得
||g−gj||p,Q
记 Np(δ,G,Q) 为满足上述条件的最小的 N ,称作δ− 覆盖数.称 Hp(δ,G,Q)=logNp(δ,G,Q) 为空间 G 在 Lp(Q) 距离下的 δ− 熵.
NOTE:若 Hp(δ,G,Q)<∞ 对所有的 δ>0 ,则称 G 是完全有界的,从而 G 的闭包是紧的.
Lp(Q) 距离下带括号的熵:
对于 δ>0 ,存在函数对的集 {[gLj,gUj]}Nj=1 , ||gUj−gLj||p,Q≤δ s.t.对任意的 g∈G 存在 j∈{1,2,...,N} 使得
gLj≤g≤gUj
记 NpB(δ,G,Q) 为满足上述条件的最小的 N ,称作带括号的δ− 覆盖数.称 HpB(δ,G,Q)=logNpB(δ,G,Q) 为空间 G 在 Lp(Q) 距离下带括号的 δ− 熵.
Bernstein 距离:记
ρ2K(g)=2K2∫(e|g|/K−1−|g|/K)dP,K>0
ρK(g1−g2) 为 g1,g2 之间的 Bernstein 距离.
带括号的广义熵:Bernstein 距离下带括号的熵
对于 δ>0 ,存在函数对的集 {[gLj,gUj]}Nj=1 , ρK(gUj−gLj)≤δ s.t.对任意的 g∈G 存在 j∈{1,2,...,N} 使得
gLj≤g≤gUj
记 NpB(δ,G,P) 为满足上述条件的最小的 N ,称作带括号的δ− 覆盖数.称 HpB(δ,G,P)=logNpB(δ,G,P) 为空间 G 在:Bernstein 距离下带括号的 δ− 熵.
这篇关于熵-entropy的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![[深度学习]交叉熵(Cross Entropy)算法实现及应用](https://img-blog.csdn.net/20171016095220792?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMzI1MDQxNg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)