本文主要是介绍AD9226 65M采样 模数转换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用 vivado 写的
AD9220_ReadTEST
module AD9220_ReadTEST(
input clk,
input rstn,output clk_driver, //模块时钟管脚
input [12:0]IO_data, //模块数据管脚output [11:0]ADC_Data,//12位ADC数据
output ADC_OTR //信号过压标志位
);wire areset, pll260m_lockedPIN;
wire pll_260M;
assign areset = ~rstn;/*
锁相环:
用于产生240M时钟
*/pll260m U0_pll260m_inst (.clk_in1 ( clk ),.clk_out1 ( pll_260M ),.locked ( pll260m_lockedPIN ));/*
AD9226控制器:
将输入的260M时钟4分频(在AD9220_ReadModule.V中定义)后,用于驱动AD9226模块,并采集信号电压数据。
数据输入电压对应关系(受信号调理电路器件值公差影响,不同模块可能有微小差异):
信号(-10V)~(+10V):数据(0~4095)
*/
AD9220_ReadModule U1_AD9220_ReadModule(
.clk(pll_260M),
.rstn(rstn),.clk_driver(clk_driver),
.IO_data(IO_data),.ADC_Data({ADC_OTR, ADC_Data})
);endmodule
AD9220_ReadModule
module AD9220_ReadModule(
input clk,
input rstn,output reg clk_driver,
input [12:0]IO_data,output reg [12:0]ADC_Data
);`define clkOutPeriod 4 //模块驱动时钟分频,clk_driver = clk/4 = 260M/4 = 65M
reg [31:0]clkCnt;
always @(posedge clk or negedge rstn)if(!rstn)clkCnt <= 32'd0;else if(clkCnt == (`clkOutPeriod-1)) beginclkCnt <= 32'd0;endelse beginclkCnt <= clkCnt + 32'd1;endalways @(posedge clk or negedge rstn)if(!rstn) beginclk_driver <= 1'd0;ADC_Data <= 13'd0;endelse if(clkCnt == `clkOutPeriod/2-1) beginclk_driver <= 1'd1;ADC_Data <= IO_data;endelse if(clkCnt == `clkOutPeriod-1) beginclk_driver <= 1'd0;ADC_Data <= ADC_Data;endelse beginclk_driver <= clk_driver;ADC_Data <= ADC_Data;endendmodule
AD9226_TEST_tb
`timescale 1ns/1ns`define clock_period 20
module AD9226_TEST_tb;reg Clock;
reg Rst_n;
//reg a,b,c;
wire clk_driver;
//wire [1:0]out;
reg [12:0]IO_data;
wire [12:0]ADC_Data;//block_nonblock block_nonblock0(Clock,Rst_n,a,b,c,out);AD9220_ReadModule U0_AD9220_ReadModule(.clk(Clock),.rstn(Rst_n),.clk_driver(clk_driver),.IO_data(IO_data),.ADC_Data(ADC_Data)
);initial Clock = 1;
always#(`clock_period/2) Clock = ~Clock;initial beginRst_n = 1'b0;IO_data <= 13'd0;#(`clock_period*200 + 1);Rst_n = 1'b1;#(`clock_period*200); IO_data <= 13'd0;#(`clock_period*200); IO_data <= 13'd1;#(`clock_period*200); IO_data <= 13'd2;#(`clock_period*200); IO_data <= 13'd3;#(`clock_period*200); IO_data <= 13'd4;#(`clock_period*200); IO_data <= 13'd5;#(`clock_period*200); IO_data <= 13'd6;#(`clock_period*200); IO_data <= 13'd7;#(`clock_period*200);$stop;
endendmodule
自己再写个 260M的时钟,四分频来提供65M的时钟。
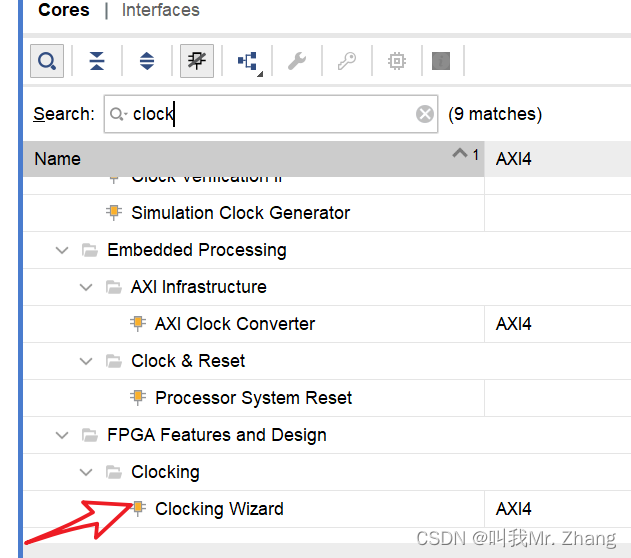
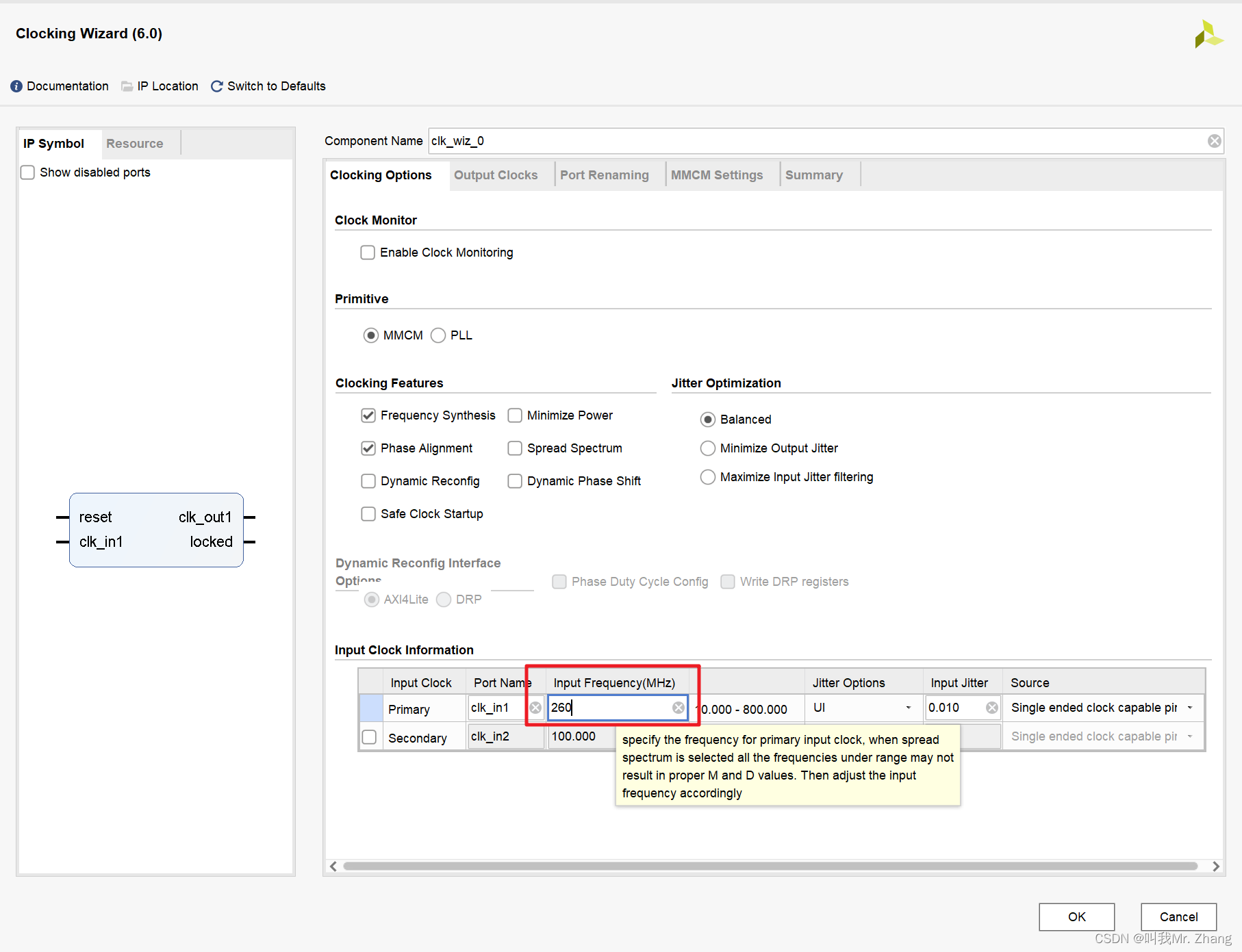
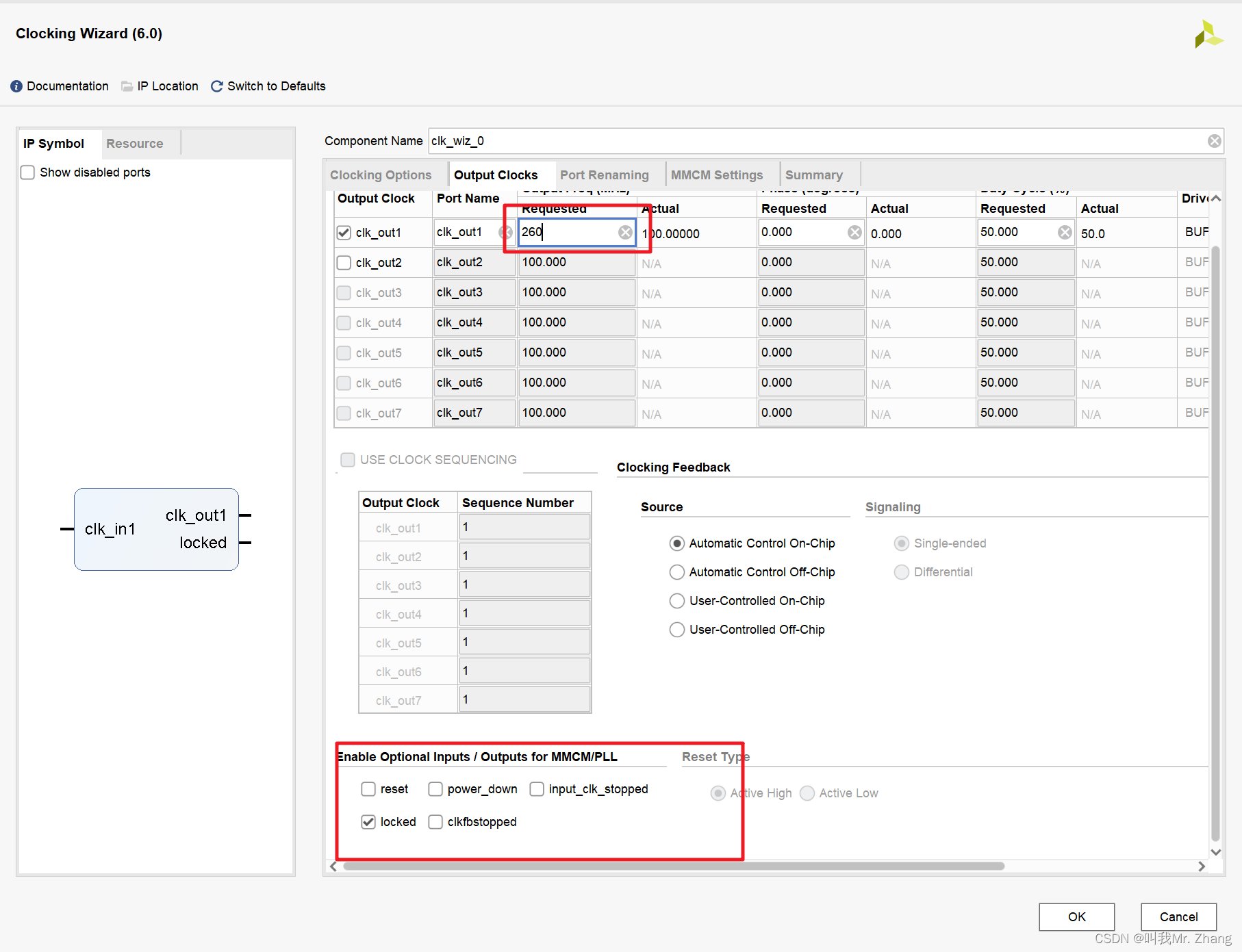
OK 最终生成
这篇关于AD9226 65M采样 模数转换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!