本文主要是介绍基于轻量级卷积神经网络模型MobileNet开发构建基于GTSRB数据集的道路交通标识识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相信经常需要开车出行的人对于各种各样的道路交通标识定是不陌生的,但是对于经常不开车的人来说生活中出现的形形色色的道路交通标识就未必都能认出来了,本文的主要目的就是想要基于CNN来开发构建道路交通标识识别分析系统,实现看图识标,这里我们选择的是德国的道路交通标识数据集GTSRB,关于该数据集在我前面的博文中有很详细的操作使用说明,如果有需要的话可以自行移步阅读即可。
《Python实现交通标志牌(GTSRB数据集)解析处理》
这里就不再对数据集的处理进行介绍了,直接步入正文。
首先看下实例效果:
接下来简单看下数据集:


这里我们选择的MobileNetv1的模型,MobileNet是一种轻量级的卷积神经网络模型,旨在在计算资源受限的移动设备上实现高效的图像分类和目标检测。其主要原理如下:
Depthwise Separable Convolution:MobileNet使用Depthwise Separable Convolution来减少参数量和计算量。这是一种将标准卷积分解成深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两个步骤的方法。深度卷积仅对输入的每个通道进行卷积,减少了卷积核的数量。逐点卷积使用1x1卷积核来将深度卷积的输出转化为期望的特征维度。这种分解有效降低了参数量,减少了计算量。
网络结构设计:MobileNet采用了基于深度可分离卷积的轻量网络结构。网络主要由一系列重复的卷积块和下采样层构成。卷积块包含了深度卷积、逐点卷积和激活函数。下采样层通常使用步长较大的深度可分离卷积来减少特征图的尺寸。通过这种设计,MobileNet减少了网络的深度和参数量,从而在较小的设备上实现了高效的推理。
优点:
轻量高效:MobileNet采用了Depthwise Separable Convolution和轻量网络结构,大大减少了参数量和计算量,使得它在计算资源受限的设备上运行速度快。
网络结构可定制:MobileNet的网络结构可以根据不同的需求和资源限制进行调整和定制。可以通过调整深度可分离卷积的层数和通道数来平衡准确性和模型大小。
缺点:
精度受限:由于网络结构的轻量化和参数减少,MobileNet相对于大型网络模型,如ResNet和Inception等,可能牺牲了一定的精度。
对复杂数据集的泛化能力有限:MobileNet在处理复杂数据集上的泛化能力可能相对较差,适用于较简单的图像分类和目标检测任务。
需要根据实际应用场景和资源限制来权衡使用MobileNet的优势和劣势。在资源受限的设备上,如移动设备或嵌入式系统,MobileNet是一种高效的选择,但在对准确性和复杂性要求较高的任务上,可能需要考虑更为复杂的网络结构。
MobileNetv1模型核心代码实现如下所示:
def MobileNet(classes=43):img_input = Input(shape=(224,224,3))x = convBlock(img_input, 32, 1.0, strides=(2, 2))x = dwConvBlock(x, 64, 1.0, 1, block_id=1)x = dwConvBlock(x, 128, 1.0, 1, strides=(2, 2), block_id=2)x = dwConvBlock(x, 128, 1.0, 1, block_id=3)x = dwConvBlock(x, 256, 1.0, 1, strides=(2, 2), block_id=4)x = dwConvBlock(x, 256, 1.0, 1, block_id=5)x = dwConvBlock(x, 512, 1.0, 1, strides=(2, 2), block_id=6)x = dwConvBlock(x, 512, 1.0, 1, block_id=7)x = dwConvBlock(x, 512, 1.0, 1, block_id=8)x = dwConvBlock(x, 512, 1.0, 1, block_id=9)x = dwConvBlock(x, 512, 1.0, 1, block_id=10)x = dwConvBlock(x, 512, 1.0, 1, block_id=11)x = dwConvBlock(x, 1024, 1.0, 1, strides=(2, 2), block_id=12)x = dwConvBlock(x, 1024, 1.0, 1, block_id=13)x = GlobalAveragePooling2D()(x)shape = (1, 1, 1024)x = Reshape(shape)(x)x = Dropout(1e-3)(x)x = Conv2D(classes, (1, 1), padding="same")(x)x = Activation("softmax")(x)x = Reshape((classes,))(x)inputs = img_inputmodel = Model(inputs, x)return model等待训练完成后我们对其训练结果进行可视化展示。核心代码实现如下所示:
# 准确率曲线
plt.clf()
plt.figure(figsize=(12, 6))
plt.plot(train, label="Train Acc Cruve")
plt.plot(test, label="Test Acc Cruve")
plt.title("Train-Test Accuracy Cruve")
plt.legend(loc="upper center", ncol=2)
plt.savefig("train_acc.png")# 损失值曲线
plt.clf()
plt.figure(figsize=(12, 6))
plt.plot(train, label="Train Loss Cruve")
plt.plot(test, label="Test Loss Cruve")
plt.title("Train-Test Loss Cruve")
plt.legend(loc="upper center", ncol=2)
plt.savefig("train_loss.png")
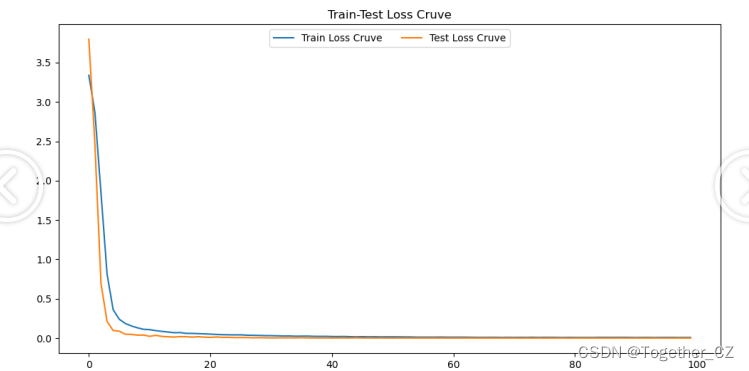
结果输出如下所示:
【loss曲线】
【accuracy曲线】
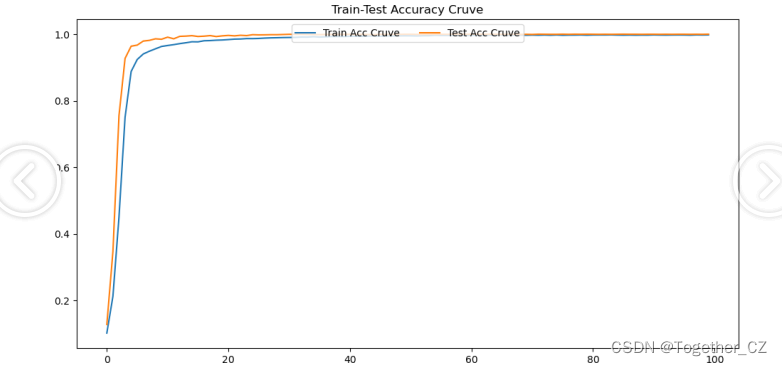
综合来看模型的效果已经是非常好的了。
感兴趣的话也都可以自行动手实践下!
这篇关于基于轻量级卷积神经网络模型MobileNet开发构建基于GTSRB数据集的道路交通标识识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





