本文主要是介绍R语言贝叶斯Metropolis-Hastings Gibbs 吉布斯采样器估计变点指数分布分析泊松过程车站等待时间,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近我们被客户要求撰写关于吉布斯采样的研究报告,包括一些图形和统计输出。
指数分布是泊松过程中事件之间时间的概率分布,因此它用于预测到下一个事件的等待时间,例如,您需要在公共汽车站等待的时间,直到下一班车到了。
在本文中,我们将使用指数分布,假设它的参数 λ ,即事件之间的平均时间,在某个时间点 k 发生了变化,即:
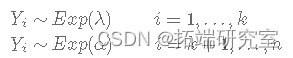
我们的主要目标是使用 Gibbs 采样器在给定来自该分布的 n 个观测样本的情况下估计参数 λ、α 和 k。
吉布斯Gibbs 采样器
Gibbs 采样器是 Metropolis-Hastings 采样器的一个特例,通常在目标是多元分布时使用。使用这种方法,链是通过从目标分布的边缘分布中采样生成的,因此每个候选点都被接受。
Gibbs 采样器生成马尔可夫链如下:
-
让
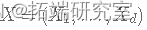 是 Rd 中的随机向量,在时间 t=0 初始化 X(0)。
是 Rd 中的随机向量,在时间 t=0 初始化 X(0)。 -
对于每次迭代 t=1,2,3,...重复:
-
设置 x1=X1(t-1)。
-
对于每个 j=1,...,d:
-
生成 X∗j(t) 从
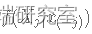 , 其中
, 其中 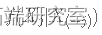 是给定 X(-j) 的 Xj的单变量条件密度。
是给定 X(-j) 的 Xj的单变量条件密度。 -
更新
 .
.
-
-
当每个候选点都被接受时,设置
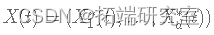 .
. -
增加 t。
贝叶斯公式
变点问题的一个简单公式假设 f和 g 已知密度:
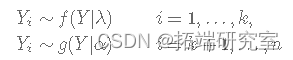
其中 k 未知且 k=1,2,...,n。让 Yi为公交车到达公交车站之间经过的时间(以分钟为单位)。假设变化点发生在第 k分钟,即:

当 Y=(Y1,Y2,...,Yn) 时,似然 L(Y|k)由下式给出:
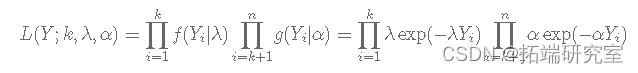
假设具有独立先验的贝叶斯模型由下式给出:

数据和参数的联合分布为:
![]()
其中,
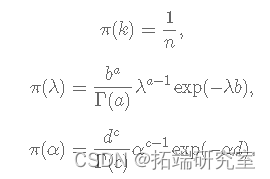
正如我之前提到的,Gibbs 采样器的实现需要从目标分布的边缘分布中采样,因此我们需要找到 λ、α 和 k 的完整条件分布。你怎么能这样做?简单来说,您必须从上面介绍的连接分布中选择仅依赖于感兴趣参数的项并忽略其余项。
λ 的完整条件分布由下式给出:
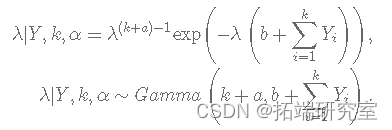
α 的完整条件分布由下式给出:
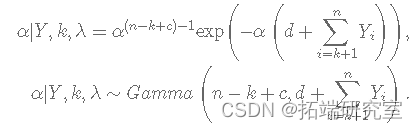
k 的完整条件分布由下式给出:
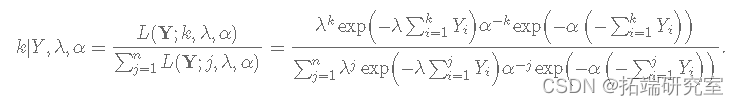
计算方法
在这里,您将学习如何使用使用 R 的 Gibbs 采样器来估计参数 λ、α 和 k。
数据
首先,我们从具有变化点的下一个指数分布生成数据:
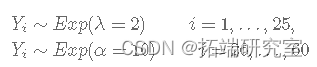
set.seed(98712)
y <- c(rexp(25, rate = 2), rexp(35, rate = 10))考虑到公交车站的情况,一开始公交车平均每2分钟一班,但从时间i=26开始,公交车开始平均每10分钟一班到公交车站。
Gibbs采样器的实现
首先,我们需要初始化 k、λ 和 α。
n <- length(y) # 样本的观察值的数量
lci <- 10000 # 链的大小
aba <- alpha <- k <- numeric(lcan)
k[1] <- sample(1:n,现在,对于算法的每次迭代,我们需要生成 λ(t)、α(t) 和 k(t),如下所示(记住如果 k+1>n 没有变化点):
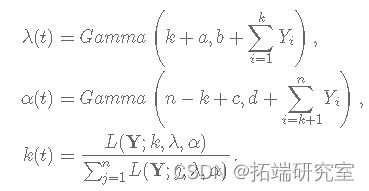
for (i in 2:lcan){kt <- k[i-1]# 生成lambdalambda[i] <- rgamma# 生成α# 产生k for (j in 1:n) {L[j] <- ((lambda[i] / alpha[i# 删除链条上的前9000个值
bunIn <- 9000 结果
在本节中,我们将介绍 Gibbs 采样器生成的链及其参数 λ、α 和 k 的分布。参数的真实值用红线表示。
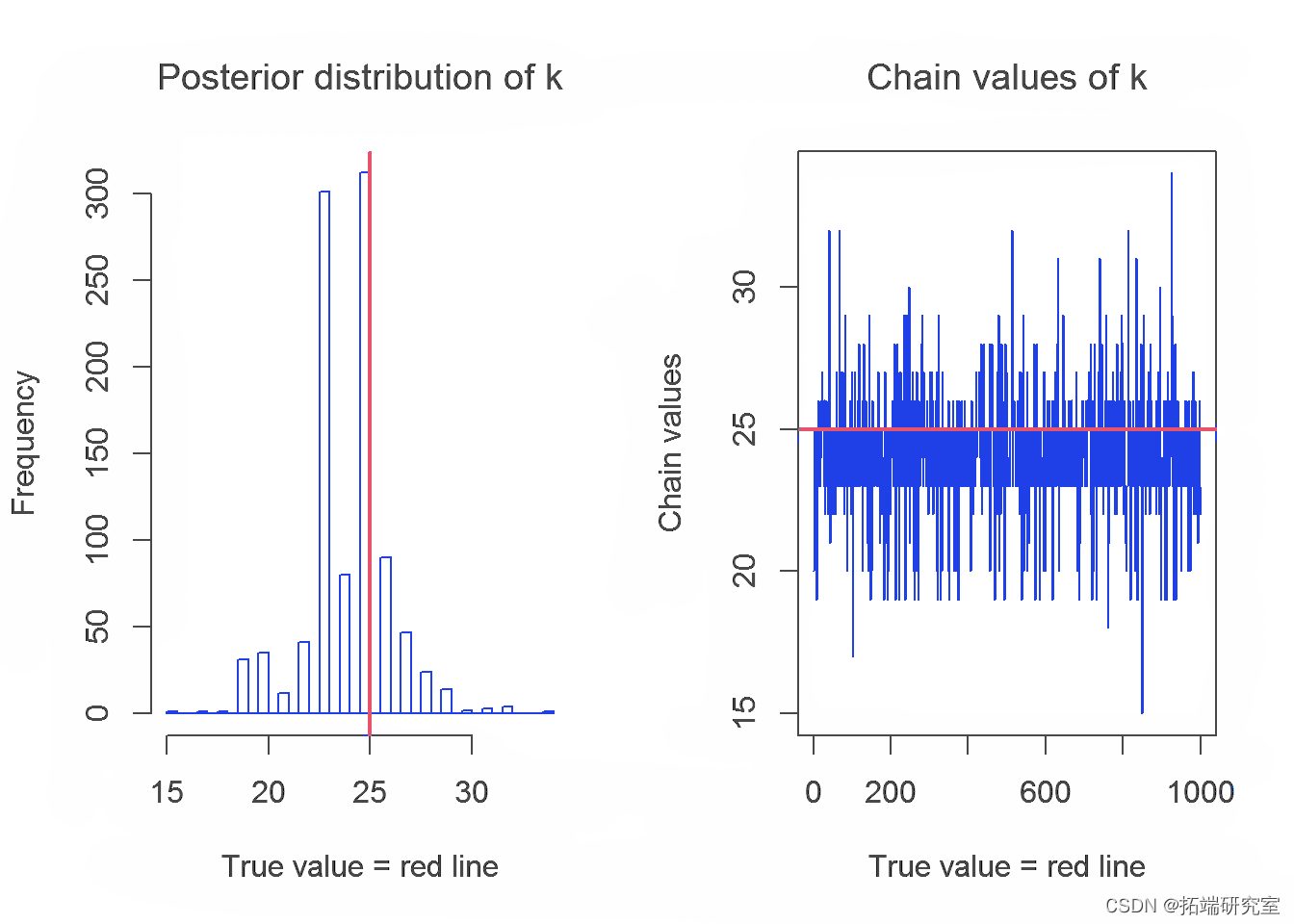
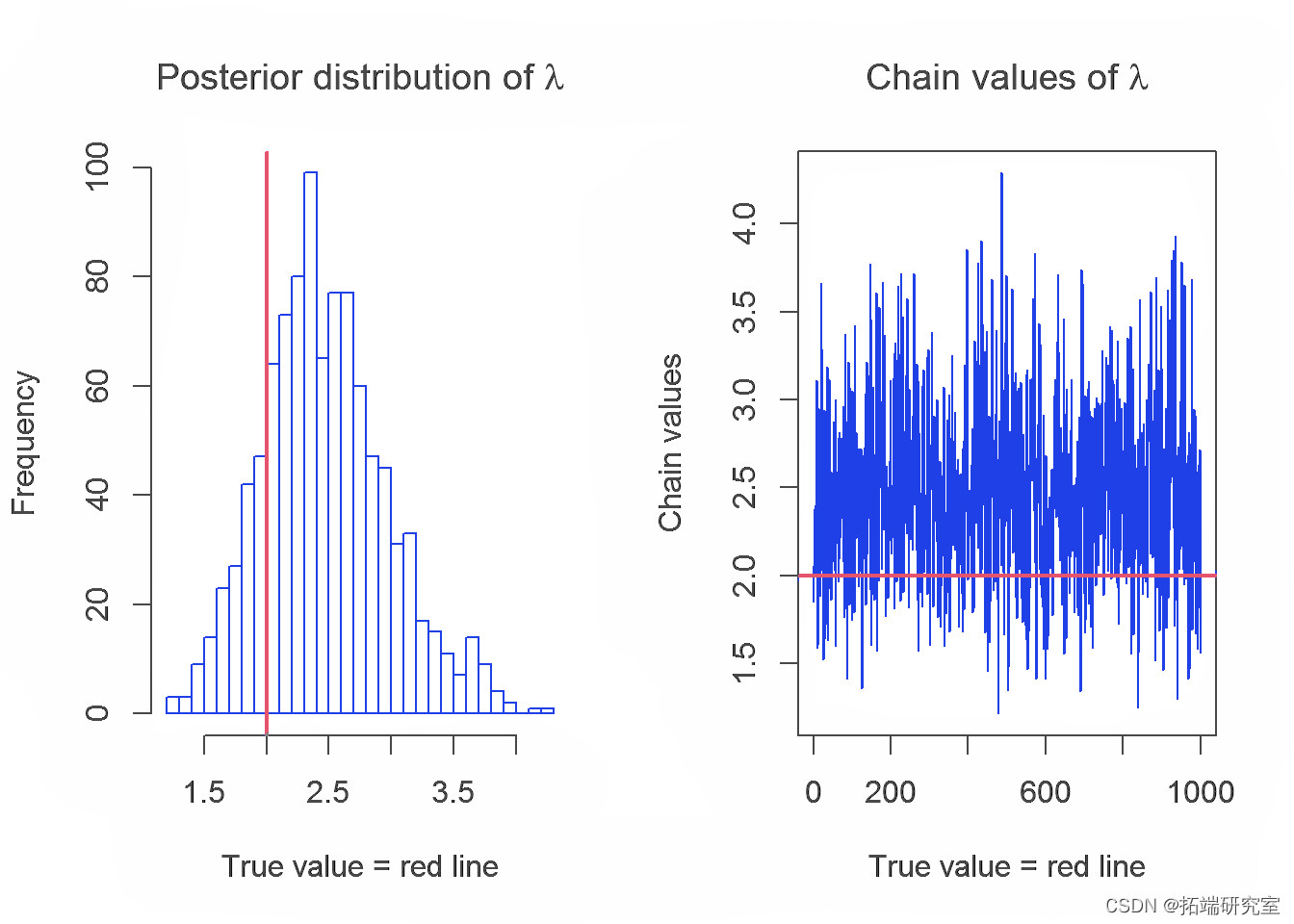
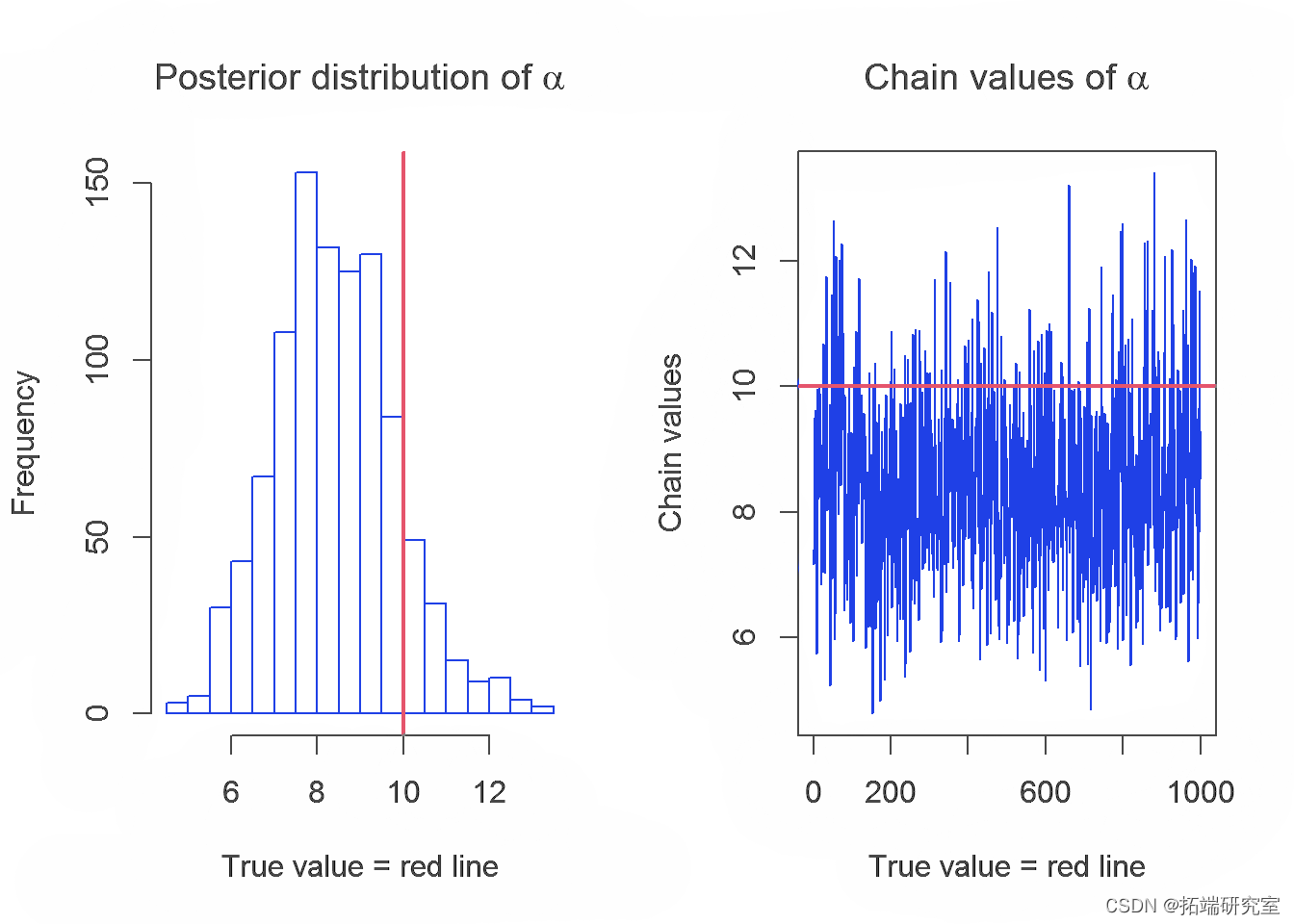
下表显示了参数的实际值和使用 Gibbs 采样器获得的估计值的平均值:
res <- c(mean(k[-(1:bun)]), mean(lmba[-(1:burn)]), mean(apa[-(1:buI)]))
resfil
结论
从结果中,我们可以得出结论,使用 R 中的 Gibbs 采样器获得的具有变点的指数分布对参数 k、λ 和 α 的估计值的平均值接近于参数的实际值,但是我们期望更好估计。这可能是由于选择了链的初始值或选择了 λ 和 α的先验分布。

这篇关于R语言贝叶斯Metropolis-Hastings Gibbs 吉布斯采样器估计变点指数分布分析泊松过程车站等待时间的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






