等待时间专题

Android/Linux 磁盘写入缓存/等待时间 参数修改
Linux系统当进行文件写操作时,并不会将数据立马写入磁盘,而是写写到缓存,等待达到占用内存一定比例或超过一定时间才会批量将这些缓存数据写入磁盘,这样可以减少IO操作,提升性能和磁盘寿命。如果数据还没来得及写入磁盘发生硬件掉电,这些数据就会丢失。应用可以调用sync实时将内容写入磁盘避免丢失。排查丢失问题可以在断电前执行sync命令,看能不能复现,若无法复现,说明就是缓存没有及时写入磁盘导致。

Keras 添加model.add(LSTM(......))等待时间过长,以及占用CPU空间的问题
原因: tensorflow版本过低,一般tensorflow在1.3.0以下(包括1.3.0)会出现这种问题 解决方法: 升级tensorflow pip install tensorflow --upgrade 再次运行会提示 ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.9’ not found 参考博客: https:

WPF 一个执行耗时任务,页面更新等待时间的例子
xaml页面,一个按钮,一个lable,lable用来更新等待的时间。点击按钮,每过1秒,label的数值+1,直到任务结束。 <Window x:Class="WpfApp2.MainWindow"xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x="http://schemas.microsoft.
ACE的通知信号量,等待时间(2008-12-21 14:24:19)
ACE的通知信号量,等待时间 (2008-12-21 14:24:19) 标签:it 分类:ACE学习笔记 1.通知信号量:ACE_Thread_Semaphore 第一步:初始化:m_callSem(0); 第二部:同步等待:callSem.acquire(); 第三部:通知信号量加一:callSem.release(); 举例如下: //testSemaphore.h

基于排队理论的客户结账等待时间MATLAB模拟仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 4.1 排队系统的组成 4.2 基本概念 4.3 常见的排队模型 5.完整程序 1.程序功能描述 基于排队理论的客户结账等待时间MATLAB模拟仿真,分析平均队长,平均等待时长,不能结账的概率,损失顾客数,到达顾客数,服务顾客数,平均服务时间。 2.测试软件版本以及运
conda安装pytotch和torchvision,加载模型到GPU中等待时间过长
问题描述:在服务器上用conda创建了自己的环境,然后在该环境下用conda创建一个python 2.7的环境,在该环境下安装pytorch和torchvision包,训练模型时,model = model.cuda()占据过多时间。 解决: 卸载之前安装的pytorch,conda uninstall pytorch 然后pip重新安装,pip install xx.whl # 把whl下

单机调度问题(第i工件的完工时间=加工时间+等待时间)
第08章 制造系统的调度控制 - 百度文库 (baidu.com) 模拟退火单机极小化总流水时间的排序问题_哔哩哔哩_bilibili 在单机调度问题中,工件的完工时间是一个至关重要的指标,因为它直接反映了生产效率的高低。而完工时间的计算,必须同时考虑工件的加工时间和等待时间,因为这两者共同决定了工件在机器上的整体处理时间。 加工时间,是工件在机器上进行实际加工所需的时间,这是由工
前端开发攻略---在页面上渲染大量元素,使用defer减少白屏等待时间,优化页面响应速度
1、优化前 2、优化后 3、优化思路 1、在元素数量不变的情况下,进行一步一步的渲染,先渲染一些重要的元素或者需要用户第一时间看到的元素。 2、使用Hooks封装优化函数 4、优化代码 拥有大量元素的组件(Item):文件位置:components > Item > index.vue <template><div class="content"><span v-for
管理双系统中的默认系统启动顺序以及启动等待时间
转载来源:http://www.cnblogs.com/giraffe/archive/2012/02/25/2368235.html 注意如果修改了/boot/grub/grub.cfg之后,则不要再更新update-grub,因为那样又会生成新的grub.cfg文件。 一、能上网情况下的最好方法:安装startupmanager——图形启动项管理器 打开

手机拨出等待时间长_为什么现在打开
2008-05-07 开机等待问题电脑开机后要等很长时 速度、木马、系统漏洞、病毒等综合性影响,常规解决办法: 1、解决杂乱文件影响(减少电脑负担)。 清理杂乱文件有三个方法,第一是点网页上的“工具”,点“Internet选项(0)”,在新页面分别点“删除Cookies(I)”“删除文件(F)”“清除历史记录(H)”、最后“确定”;第二是用“磁盘清理”,把鼠标指向程序——附件——系统工具——就
web 性能测试中的几个关键指标:并发用户数,QPS,用户平均请求等待时间
关于并发用户数和QPS,自己一直被这两个概念纠结,阅读了一下相关资料,总结如下:并发用户数和QPS两个概念没有直接关系,但是如果要说QPS时,一定需要指明是多少并发用户数下的QPS,否则豪无意义,因为单用户数的40QPS和20并发用户数下的40QPS是两个不同的概念。前者说明该应用可以在一秒内串行执行40个请求,而后者说明在并发20个请求的情况下,一秒内该应用能处理40个请求,当QPS相同时,越

R语言贝叶斯Metropolis-Hastings Gibbs 吉布斯采样器估计变点指数分布分析泊松过程车站等待时间
最近我们被客户要求撰写关于吉布斯采样的研究报告,包括一些图形和统计输出。 指数分布是泊松过程中事件之间时间的概率分布,因此它用于预测到下一个事件的等待时间,例如,您需要在公共汽车站等待的时间,直到下一班车到了。 在本文中,我们将使用指数分布,假设它的参数 λ ,即事件之间的平均时间,在某个时间点 k 发生了变化,即: 我们的主要目标是使用 Gibbs 采样器在给定来自该分布的

R语言贝叶斯METROPOLIS-HASTINGS GIBBS 吉布斯采样器估计变点指数分布分析泊松过程车站等待时间...
原文链接:http://tecdat.cn/?p=26578 指数分布是泊松过程中事件之间时间的概率分布,因此它用于预测到下一个事件的等待时间,例如,您需要在公共汽车站等待的时间,直到下一班车到了(点击文末“阅读原文”获取完整代码数据)。 相关视频 在本文中,我们将使用指数分布,假设它的参数 λ ,即事件之间的平均时间,在某个时间点 k 发生了变化,即: 我们的主要目标是使用 Gibbs
Linux系统内核-TCP连接数和网络等待时间设置优化
一、TCP连接数优化 Linux服务器默认支持1024个tcp连接,在实际压测时,无论是压力机还是服务器都需要对tcp参数进行优化 1.参看系统当前支持tcp连接数 ulimit -n 2.设置系统最大连接数 vi /etc/security/limits.conf 在最后一行添加: * soft nofile 1000000 * hard nofile 1000000

Python+Selenium+Unittest 之selenium15--等待时间
在正常的自动化过程中,如果整篇代码中没有加等待时间的话,有时候可能页面跳转或者还没开始点击就执行到下一个流程了,这时候因为页面没有加载完毕,所以有可能会导致找不到对应的元素而报错,因此我们需要在整个代码流程中间合适的位置加上等待时间,使其等待页面加载完毕后,在进行后续代码流程。 Selenium中有三种等待方式,分别为:强制等待、隐式等待、显示等待。 1、强制等待
windows 和 ubuntu (20.4) 双系统:开机选择系统时,等待时间的设置
windows 和 ubuntu (20.4) 双系统:开机选择系统时,等待时间的设置 使用管理员权限 && gedit 编辑器,编辑文件 /etc/default/grub sudo gedit /etc/default/grub CTRL + F 搜索 GRUB_TIMEOUT,将它的值修改为自己想要的时间。例如我改成了开机选择系统时等待 300s:GRUB_TIMEOUT = 300
LeetCode:1701. 平均等待时间(Java 模拟)
目录 1701. 平均等待时间 题目描述: 实现代码与解析: 简单模拟 原理思路: 1701. 平均等待时间 题目描述: 有一个餐厅,只有一位厨师。你有一个顾客数组 customers ,其中 customers[i] = [arrivali, timei] : arrivali 是第 i 位顾客到达的时间,到达时间按 非递减 顺序排列。timei 是
Java的Object.wait(long)在等待时间过去后会继续往后执行吗
Java的Object.wait(long)在等待时间过去后会继续往后执行吗 Object.wait(long)方法相比于wait,多了个等待时长,那么当等待时长过去后,线程会继续往下执行吗? 单个线程执行 多个线程并发执行 public class ThreadWaitDemo { public static final int WAIT_IN_SECONDS = 2;public s
mysql事务锁等待时间
获取表锁信息 SELECT r.trx_id waiting_trx_id, r.trx_mysql_thread_id waiting_thread, TIMESTAMPDIFF( SECOND, r.trx_wait_started, CURRENT_TIMESTAMP ) wait_time, r.trx_query waiting_query, l.lock_tab

进程调度:一个例子区分响应时间、周转时间和等待时间
参考链接 arrival time:the time when a process enters into the ready state and is ready for its execution.(进程进入就绪态的时刻) burst time: the total time taken by the process for its execution on the CPU(进程在CPU上执
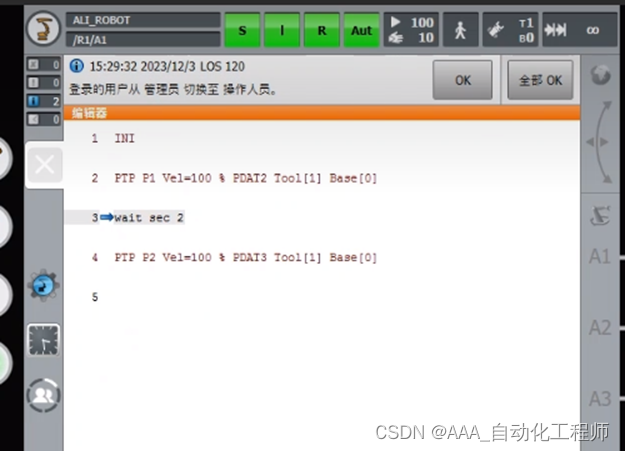
KUKA机器人如何在程序中编辑等待时间?
KUKA机器人如何在程序中编辑等待时间? 如下图所示,如何实现在P1点和P2点之间等待设定的时间? 如下图所示,可以直接输入wait sec 2(等待2秒), 如下图所示,再次选中该程序后,选择“选定”, 如下图所示,执行该程序,可以看到到达P1点之后,会等待2秒,2秒时间到之后才会继续执行下一个动作。

如何通过Timer将等待时间参数化
场景:当taskA执行结束后,等待到指定时间点后(该时间点是参数化的,而非固定写死的时间点),再执行下一个taskB 解决方案: 1) 在创建一个workflow变量,如$$Time, 它的必须类型是date/time类型 2) taskA之后创建一个assignment task,将$$Time值设定为指定的时间点 注意:指定的时间点

jmeter等待时间设置
第一部分:Request之间的等待时间的设置 先明确一些概念:1)定时器是在每个sampler(采样器)之前执行的,而不是之后;是的,你没有看错,不管这个定时器的位置放在sampler之后,还是之下,它都在sampler之前得到执行。2)定时器是有作用域的;当执行一个sampler之前时,所有当前作用域内的定时器都会被执行;3)如果希望定时器仅应用于其中一个sampler,则把该定时器作为子
解决Ubuntu 14.04 grub选择启动项10秒等待时间
sudo vim /etc/default/grub 注释掉:GRUB_HIDDEN_TIMEOUT 修改:GRUB_HIDDEN_TIMEOUT= 秒数 最后sudo update-grub

前端图片压缩上传,减少等待时间!优化用户体检
添加图片注释,不超过 140 字(可选) 这里有两张图片,它们表面看上去是一模一样的,但实际上各自所占用的内存大小相差了180倍。 添加图片注释,不超过 140 字(可选) 添加图片注释,不超过 140 字(可选) 可以看到右边的图片是22.3MB,而左侧的图片只有127KB,但是实际上这两张图片的大小都是22.3MB。 最近在开发中遇到这样的一个需求,需要把用户上传的图
python中的贪心算法-求顾客的最小的等待时间
一. 设有n个顾客同时等待一项服务。顾客i需要的服务时间为ti(1<=i<=n)。如何安排n个顾客的服务次序才能使顾客总的等待时间达到最小? n=int(input('请输入顾客的位数: '))times=[]for i in range(n):time=int(input(f'请输入顾客{i+1}的服务时间: '))times.append(time)times.sort()total