本文主要是介绍【EAI 013】BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning
论文作者:Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, Chelsea Finn
论文原文:https://arxiv.org/abs/2202.02005
作者单位:Robotics at Google, Everyday Robots, UC Berkeley, Stanford University
论文出处:CoRL 2021
论文被引:235(01/05/2024)
论文代码:https://www.kaggle.com/google/bc-z-robot
项目主页:https://sites.google.com/view/bc-z/home
Abstract
在本文中,我们研究了使基于视觉的机器人操作系统能够泛化到新任务的问题,这是机器人学习中一个长期存在的挑战。我们从模仿学习(Imitation Learning)的角度切入这一难题,旨在研究如何扩展和拓宽所收集的数据来促进这种泛化。为此,我们开发了一个交互式的灵活模仿学习系统,该系统既能从演示(demonstrations)中学习,也能从干预(interventions)中学习,并能以传达任务的不同形式的信息为条件,包括经过预训练的自然语言嵌入(embeddings)或人类执行任务的视频。在对真实机器人的数据收集进行扩展到 100 多个不同任务时,我们发现该系统可以执行 24 个未见过的操作任务,平均成功率为 44%,而且这些任务无需机器人演示。
1 Introduction
机器人技术面临的巨大挑战之一,是创造出一种能够在非结构化环境中根据用户任意指令执行多种任务的通用机器人(general-purpose robot)。这项工作的关键挑战在于泛化性(generalization):机器人必须处理新的环境,识别和操作它以前从未见过的物体,并理解它从未被要求执行的命令的意图。从像素开始的端到端学习是为这种通用机器人行为建模的灵活选择,因为它对世界的状态表示假设最少。只要有足够的真实世界数据,这些方法原则上就能让机器人在新的任务,物体和场景中实现泛化,而不需要手工编码的特定任务表示法。然而,实现这一目标通常仍是遥不可及的。本文研究了如何让机器人将零样本或小样本泛化到新的基于视觉的操作任务。
我们利用模仿学习的框架来研究这个问题。之前关于模仿学习的研究表明了对新物体[1, 2, 3, 4, 5]和新物体目标配置[6, 7]的单样本(one-shot)或零样本(zero-shot)泛化。然而,对新任务的零样本泛化仍然是一个挑战,特别是在考虑基于视觉的操作任务时,这些任务涵盖了使用不同物体的多种技能(如擦拭,推,拾放)。要实现这种泛化,就必须解决与扩大数据收集规模和针对不同数据学习算法有关的难题。
我们开发的交互式模仿学习(interactive imitation learning)系统具有两个关键特性,能够收集高质量的数据,并将其泛化到全新的任务中。
- 首先,我们的系统将共享自主权融入远程操作中,使我们既能收集原始演示数据,又能进行人工干预以纠正机器人的当前策略。
- 其次,我们的系统可根据不同形式的任务说明(包括语言指令或人类执行任务的视频)灵活调整策略。与离散的单样本任务标识符[8]不同,这些连续形式的任务说明原则上可以让机器人在测试时提供新任务的语言或视频指令,从而将零样本或小样本任务泛化为新任务。我们之前已经探索过这些特性;我们的目的是通过经验研究这些想法是否适用于广泛的真实世界任务。
我们的主要贡献是对大规模交互式模仿学习系统进行了实证研究,该系统可解决各种任务,包括对训练期间未见的任务进行零样本和小样本泛化。利用该系统,我们收集了 100 个机器人操作任务的大型数据集,并将专家远程操作和共享自主过程(shared autonomy process)相结合,在共享自主过程中,人类操作员通过纠正错误来 “指导” 所学策略。在 12 个机器人中,7 个不同的操作员收集了 25,877 次机器人演示,共计 125 小时的机器人操作时间,以及 18,726 次相同任务的人类操作视频。在测试阶段,该系统能够完成 24 项未见物体之间的操作任务,而这些物体之前从未在同一场景中出现过。这些闭环视觉运动策略以 10Hz 的频率执行异步推理和控制,每个 episode 决策次数远远超过 100 次。我们开源了用于训练该策略的演示:https://www.kaggle.com/google/bc-z-robot。
2 Related Work
模仿学习在从低维状态学习抓取和拾放(pick-place)任务方面取得了成功[9, 10, 11, 12, 13, 14, 15]。深度学习可以直接从原始图像观测结果中进行模仿学习 [8,16,17]。在这项工作中,我们的重点是在模仿学习框架中实现对新任务的零样本和小样本泛化。
先前的多项模仿学习工作已经实现了不同形式的泛化,包括对新物体[1, 2, 3, 4, 18],新物体配置[19]和新目标配置[6, 7, 20]的一次泛化,以及对新物体[5],场景[21]和目标配置[22]的零样本泛化。其中许多作品都是以机器人演示 [1, 2],人类视频 [3, 4],语言指令 [23, 24] 或目标图像 [21] 为条件来适应新场景的。我们的系统可以灵活地以人类视频或语言指令为条件,并专注于实现零样本(语言)和小样本(视频)泛化,以便在真实机器人上完成全新的 7-DoF 操作任务,包括没有目标图像的场景,以及在训练数据中从未同时遇到任务相关物体的场景。
通过远程操作(teleoperation)[25]或动觉教学(kinesthetic teaching)[10]收集演示是标准做法,而 DAgger [26]等主动学习(active learning)方法有助于减少学习者的分布漂移(distribution shift)。遗憾的是,DAgger 及其一些变体 [27, 28]很难应用于机器人操作,因为它们需要一个接口(interface),专家必须在不控制机器人策略的情况下注释正确的操作。受最近自动驾驶领域的 HG-DAgger [29] 和 EIL [30] 的启发,我们的系统只要求专家在认为策略可能出错时进行干预,并允许专家暂时完全控制,使策略回到正轨。由此产生的数据收集方案易于使用,并有助于解决分配偏移问题。此外,专家在数据收集过程中的干预率可作为现场评估指标,我们通过经验发现,这与策略成功与否息息相关。
除了模仿学习,许多其他机器人学习作品也对泛化进行了研究。其中包括将技能泛化到新物体 [31, 32, 33, 34, 35],新环境 [36] ,从模拟到现实 [37, 38, 39, 40, 41],以及新操作技能和物体 [42, 43, 44, 45]。我们的研究重点是最后一种情况,即对新任务的泛化,但与之前的这些研究不同,我们处理的是一大套 100 个具有挑战性的任务,这些任务涉及 10 Hz 频率下的 7 DoF 控制,并且在一个 episode 中需要做出 100 多项决定才能完成任务。
3 Problem Setup and Method Overview

我们的模仿学习系统概览如图 1 所示。我们的目标是训练一种条件策略,它可以解释 RGB 图像(表示为 s ∈ S s \in \mathcal{S} s∈S)和任务指令 w ∈ W w \in \mathcal{W} w∈W(可能对应于语言字符串或人物视频)。不同的任务对应完成不同的目标;图 2 显示了一些任务和相应指令的示例。策略是从图像和命令到动作的映射,可以写成 μ : S × W → A μ : \mathcal{S} × \mathcal{W} → \mathcal{A} μ:S×W→A,其中动作空间 A 包括末端操纵装置的 6 个自由度(DoF)姿态,以及用于平行钳口夹爪连续控制的第 7 个自由度。

通过基于虚拟现实的远程操作(VR-based teleoperation rig)平台(见图 1 左侧)收集的大规模数据集,结合直接演示和人在回路中共享自主权(human-in-the-loop shared autonomy),对策略进行训练。在后者中,经过训练的策略被部署到机器人上,当机器人犯错时,人类操作员会进行干预,提供纠正。这一过程类似于人类导向的 DAgger(HG-DAgger)算法 [26,29],可对所学策略进行迭代改进,并提供可用于跟踪策略性能的连续信号。
策略架构分为编码器 q ( z ∣ w ) q(z|w) q(z∣w) 和控制层 π π π,编码器将命令 w w w 处理为嵌入 z ∈ Z z∈\mathcal{Z} z∈Z,控制层 π π π 处理 ( s , z ) (s, z) (s,z) 以产生动作 a a a,即 π : S × Z → A π : \mathcal{S} × \mathcal{Z} → \mathcal{A} π:S×Z→A。它使我们的方法能够纳入辅助监督,例如预训练的语言嵌入,这有助于构建潜在任务空间并促进泛化。在我们的实验中,我们将证明这种方法可以泛化到训练过程中没有出现过的任务,包括动词和宾语的新组合。
4 Data Collection and Workflow
为了让模仿学习系统在零演示的情况下泛化到新任务,我们必须能够轻松地收集各种数据集,提供纠正反馈,并对许多任务进行大规模评估。
System Setup.
我们的远程操控系统使用 Oculus VR 头显,该头显通过 USB 连接到机器人的机载计算机,并跟踪两个手持控制器。远程操作员站在机器人后面,使用控制器以第三人称视角操作机器人。机器人在 10 Hz 非实时控制环路中对操作员的动作做出响应。相对较快的闭环控制使操作员能够轻松地演示各种任务,并在自主执行过程中机器人即将进入不安全状态时迅速进行干预。有关用户界面和数据收集的更多详情,请参阅附录 A 和 B。
Environment and Tasks.
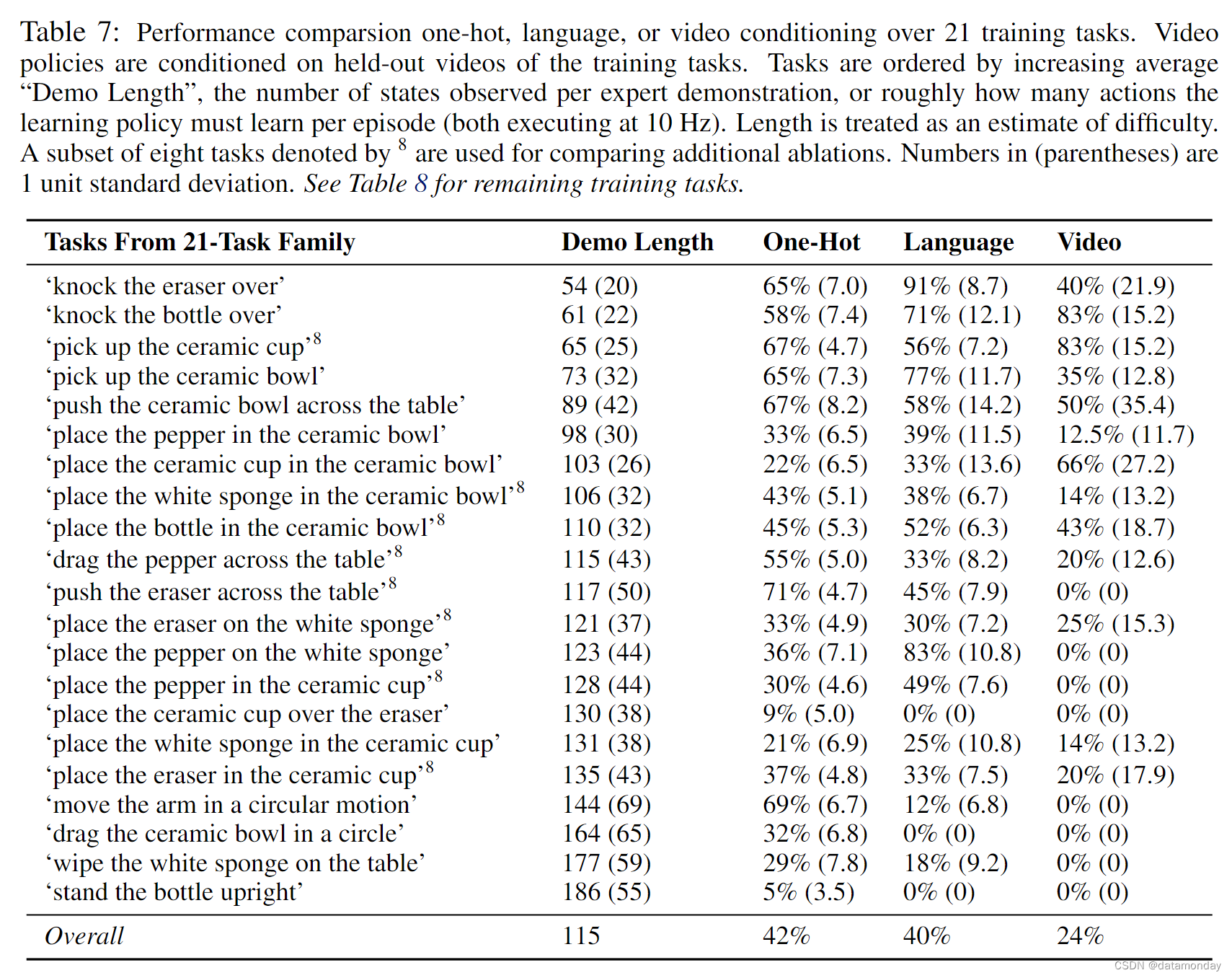
我们将每个机器人放置在一张桌子前,桌子上摆放着 6 到 15 件姿态随机的家用物品。我们收集了人类执行 100 项预先指定任务的演示和视频(见表 7 和表 8),这些任务涵盖 9 种基本技能,如 pushing 和 pick-and-place。然后,我们使用新的语言描述或任务视频,在 29 个新任务上对模型进行了评估。该方法要想在这些未完成的任务中表现出色,就必须既能正确解释新的任务指令,又能输出与该任务相符的动作。

Shared Autonomy Data Collection.
数据收集从最初的专家专用阶段开始,由人类从头到尾演示任务。从专家专用数据中学习到初始多任务策略后,我们继续在共享自主(shared autonomy)模式下收集演示数据,即当前策略在人类监督下尝试执行任务。在任何时候,人类都可以通过握住 override 开关来接管机器人,这样当策略即将进入不安全状态,或者人类认为当前策略无法成功完成任务时,人类就可以短暂地完全控制机器人,并进行必要的修正。通过这种设置,可以使用 HGDAgger [29],然后将干预数据与现有数据汇总,用于重新训练策略。对于多任务操作任务,我们为初始策略收集了 11,108 次专家演示,然后又收集了 14,769 次 HG-DAgger 演示,涵盖了 16 次策略部署迭代,其中每次迭代都部署了在聚合数据集上训练的最新策略。这样,总共有 25,877 次机器人演示。我们在表 4 中发现,在控制相同的总 episode 时,HG-DAgger 能大幅提高性能。
Shared Autonomy Evaluation.
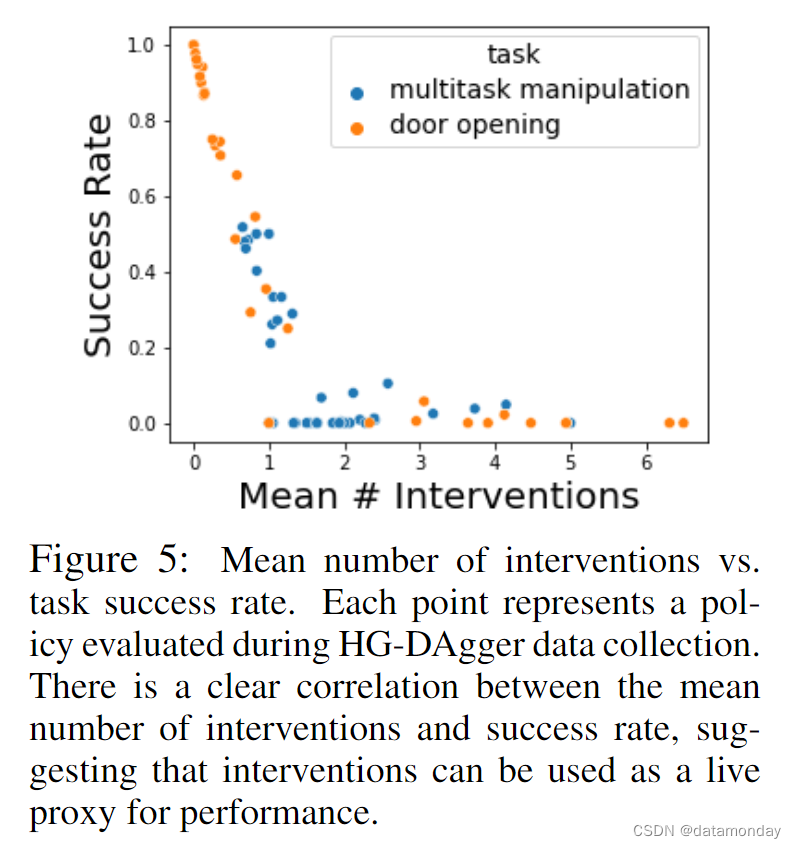
当成功率较低时,最好将资源用于收集更多数据以改进策略;但评估对于调试工作流程中的问题也很重要。随着预期泛化程度的提高,我们需要更多的试验来评估策略泛化的程度。这就产生了一个资源权衡问题:如何在测量策略成功率和收集更多示范数据以改进策略之间分配机器人时间?幸运的是,共享自主数据收集还带来了额外的好处:干预率(以每个 episode 所需的平均干预次数来衡量)可作为策略效率的指标。在图 5 中,我们发现干预率与总体策略成功率呈负相关。
5 Learning Algorithm
上述数据收集过程会产生一个大型多任务数据集。对于每个任务 i i i,该数据集包含专家数据 ( s , a ) ∈ D e i (s, a) \in \mathcal{D}^i_e (s,a)∈Dei,人类视频数据 w h ∈ D h i w_h \in \mathcal{D}^i_h wh∈Dhi 和一条语言指令 w l i w^i_{\mathscr{l}} wli。下面我们将讨论如何使用这些数据来训练编码器 q ( z ∣ w ) q(z|w) q(z∣w) 和控制层 π ( a ∣ s , z ) π(a|s,z) π(a∣s,z)。
5.1 Language and Video Encoders
我们的编码器 q ( z ∣ w ) q(z|w) q(z∣w) 将语言命令 w l i w^i_{\mathscr{l}} wli 或人类视频 w h w_h wh 作为输入,并生成任务嵌入 z z z。如果命令是语言命令,我们使用预训练的多语言句子编码器 [46] 作为编码器,为每个任务生成 512 维语言向量。尽管简单,但我们发现这些编码器在我们的实验中运行良好。
当任务指令是人类执行任务的视频时,我们使用卷积神经网络生成 z z z,特别是基于 ResNet-18 的模型。受近期研究成果 [2, 3] 的启发,我们以端到端的方式对该网络进行了训练。我们收集了 18,726 个视频数据集,这些视频是人类在各种家庭和办公室地点,摄像机视角和物体配置下完成每一项训练任务的视频。我们使用成对的人类视频 w h i w^i_h whi 和相应的演示 d e m o { ( s , a ) } i demo\{(s,a)\}^i demo{(s,a)}i,对人类视频 z i ∼ q ( − ∣ w h i ) z^i ∼ q(-|w^i_h) zi∼q(−∣whi) 进行编码,然后将嵌入传递到控制层 π ( a ∣ s , z i ) π(a|s, z_i) π(a∣s,zi),再将行为克隆损失的梯度反向传播到策略和编码器参数中。
附录 E 中对所学嵌入的可视化显示,这种端到端方法本身往往会过拟合初始物体场景,学习到较差的嵌入,并显示出较差的任务泛化能力。因此,为了使视频嵌入更符合语义,我们进一步引入了辅助语言回归损失。具体来说,这种辅助损失训练视频编码器以余弦损失预测任务语言命令的嵌入。由此得出的视频编码器目标如下:

其中 Dcos 表示余弦距离。由于机器人演示同时也是任务视频,我们还训练编码后的机器人视频与语言向量相匹配。这种语言损失对于学习更有组织的嵌入空间至关重要。其他架构和训练细节见附录 E。
5.2 Policy Training
在任务嵌入固定的情况下,我们通过对 XYZ 和轴角度预测的 Huber 损失以及对抓取角度的对数损失来训练 π ( a ∣ s , z ) π(a|s,z) π(a∣s,z)。在训练过程中,图像会被随机裁剪,降采样,并进行标准的光度增强。下面我们将介绍两个额外的设计选择,我们发现它们很有帮助。其他训练细节,如学习率,批量大小,伪代码和更多超参数,将在附录 D 中讨论。
Open-Loop Auxiliary Predictions.
该策略预测了机器人将采取的行动,以及如果以开环方式运行,该策略将采取的下 10 个行动的开环轨迹。在推理时,策略闭环运行,只根据当前图像执行第一个动作。开环预测赋予了一个辅助训练目标,并提供了一种以离线方式直观检查闭环规划质量的方法(见图 1 右侧)。
State Differences as Actions.
在标准的模仿学习实现中,演示时的动作被直接用作目标标签,以便从状态中进行预测。然而,以 10Hz 的频率克隆专家动作会导致策略学习到非常小的动作以及抖动行为。为了解决这个问题,我们将动作定义为未来 N > 1 步目标姿势的状态差异,并使用自适应算法根据手臂和抓手的移动程度来选择 N。我们将在第 6.3 节中对这一设计选择进行消融研究,并在附录 C 中提供更多细节。
5.3 Network Architecture
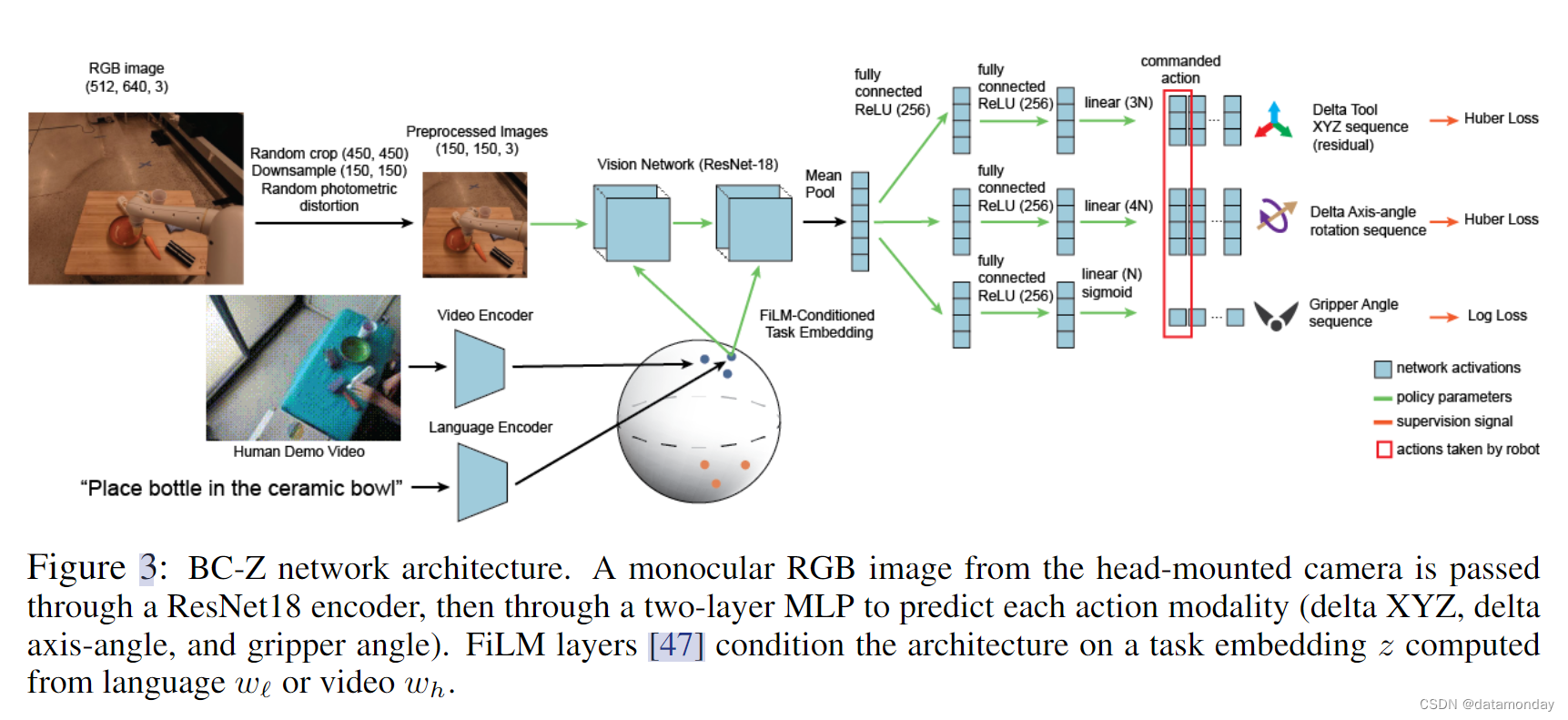
我们使用深度神经网络对策略进行建模,如图 3 所示。策略网络通过 ResNet18 “torso” [48] 处理摄像头图像,“torso” 从最后一个均值池化层分支到多个 “action heads”。每个 “action heads” 都是一个多层感知器,有两个大小各为 256 的隐藏层和 ReLU 激活,并对末端执行器的部分动作进行建模,特别是 delta XYZ,delta axis-angle 和 normalized gripper angle。通过 FiLM 层[47],该策略以 512 维任务嵌入 z 为条件。按照 Perez 等人的研究[47],任务条件被线性地投射到 4 个 ResNet 块中每个块的每个通道的通道尺度和移位上。
6 Experimental Results
我们的实验旨在评估 BC-Z 在大规模模仿学习环境中的作用。我们首先在单任务视觉模仿学习中对 BC-Z 进行初步验证。然后,我们的实验将旨在回答以下问题:
- (1) BC-Z能否从语言形式的命令或人类视频中实现零次和少量泛化到新任务?
- (2) BC-Z 的性能瓶颈在于任务嵌入还是策略?
- (3) BC-Z 的不同组成部分(包括 HG-DAgger 数据收集和自适应状态差异)的重要性如何?
我们将在本节介绍针对这些问题的实验。
6.1 BC-Z on Single-Task Imitation Learning
在考虑更具挑战性的多任务设置之前,我们首先要验证 BC-Z 能够学习单个基于视觉的任务。我们选择了两项任务:一项是垃圾桶清空任务,机器人必须从垃圾桶中抓取物品并将其丢入相邻的垃圾桶;另一项是开门任务,机器人必须在避免碰撞的同时推开一扇门。这两项任务都采用图 3 中的结构,只是开门任务涉及预测底座的前进速度和偏航速度,而不是控制手臂。垃圾桶清空数据集有 2759 次演示,而开门数据集有 24 个会议室的 12000 次演示和 5 个会议室的 36000 次模拟演示。更多任务和数据集详情见附录 I。
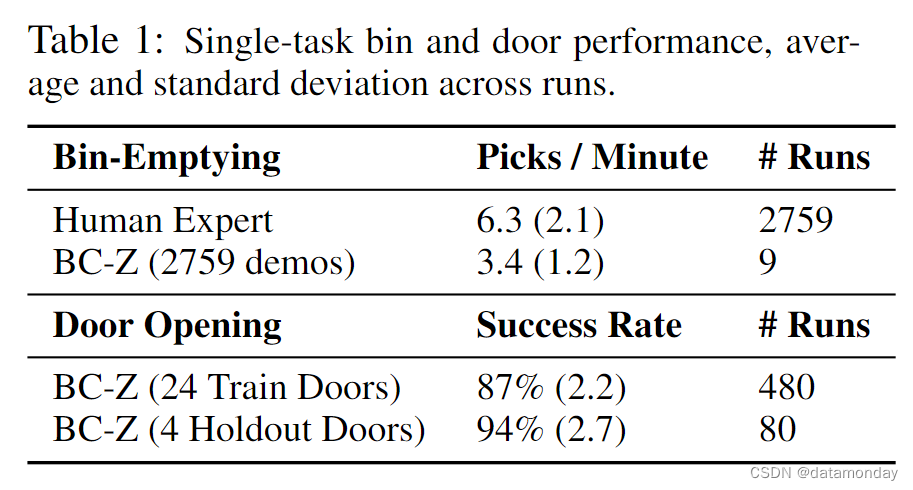
从表 1 中我们可以看到,BC-Z 模型的拾取速度达到了每分钟 3.4 次,是人类远程操作员速度的一半以上。此外,我们还可以看到,BC-Z 在 training door 场景中的成功率达到了 87%,而在 held-out door 场景中的成功率达到了 94%。这些结果验证了 BC-Z 模型和数据收集系统能够在单一任务设置中的 training 场景和 held-out 场景中取得良好的性能。其他分析见附录 H。
6.2 Evaluating Zero-Shot and Few-Shot Task Generalization

接下来,我们将测试 BC-Z 是否能在新任务中实现泛化。我们收集了 100 个不同操作任务的演示,包括两个不相连的物体集。使用不相邻的物体集,我们可以专门测试在训练过程中未同时出现的物体-物体对和物体-动作对组合的泛化能力。对于第一组物体,我们收集了 21 个不同任务的演示,如表 7 所示,这些任务涵盖了广泛的技能,从拾放任务到要求以特定方式放置物体的技能,如 “将瓶子竖立起来”。对于第二组物体,收集了 79 个不同任务的演示,包括拾放,擦拭表面和堆叠物体。后一种操作行为的种类较少,但定义的物体集较大,杂乱程度较高。附录 B 显示了物体集,附录 J Table 7 列出了全部训练任务句子。
我们对 BC-Z 在 29 个未完成任务中的表现进行了评估。语言条件策略给出的是一个新句子,而视频条件策略给出的是新任务中几个人类视频的平均嵌入。其中 4 个未完成任务使用了 79 个任务系列中的物体,而 25 个任务则是通过混合使用 21 个任务系列和 79 个任务系列中的物体生成的。因此,前 4 个被保留下来的任务不需要跨物体集泛化,因此更容易泛化。即便如此,我们还是发现这 4 个任务中的每一个都具有足够的挑战性,以至于使用 DAgger 干预对 300 多个保留演示进行的单任务策略训练完全失败,任务成功率为 0%。这在一定程度上校准了这些任务的难度。我们假设,造成这一挑战的一个主要因素是,在我们的设置中,技能必须泛化到广泛的地点,物体和分心物,以及训练数据中广泛的这些因素。
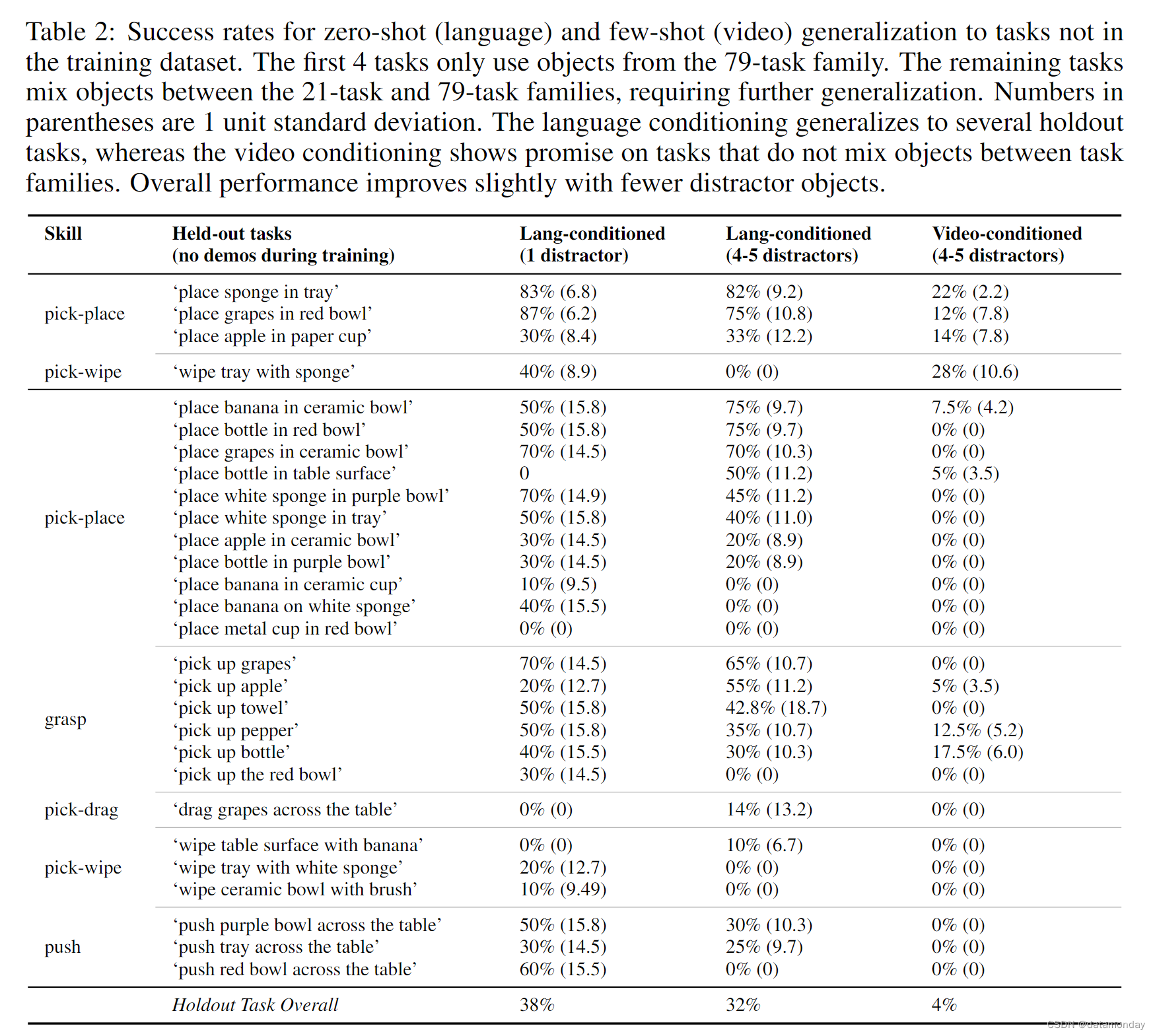
在表 2 中,我们可以看到,以语言为条件的 BC-Z 能够将 "0-shot "泛化到这两种被放置的任务中,平均成功率为 32%,并且在 24 个被放置的任务中成功率不为零。在 24 个成功率不为零的暂缓任务中,BC-Z 在对其从未见过的语言嵌入进行条件化时,平均成功率为 44%。
- 当以人类视频为条件时,我们发现泛化要困难得多,但 BC-Z 仍能以非零成功率泛化到 9 个新任务,尤其是当任务不涉及新的物体组合时。
- 从定性角度来看,我们观察到语言条件策略通常会朝着正确的物体移动,这清楚地表明任务嵌入反映了正确的任务,我们在补充视频中进一步说明了这一点。
- 最常见的失败原因是 “最后一厘米” 错误:未能关闭抓手,未能松开物体,或者在松开抓手中的物体时差点错过目标物体。
Is Performance Bottlenecked on the Encoder or the Policy?
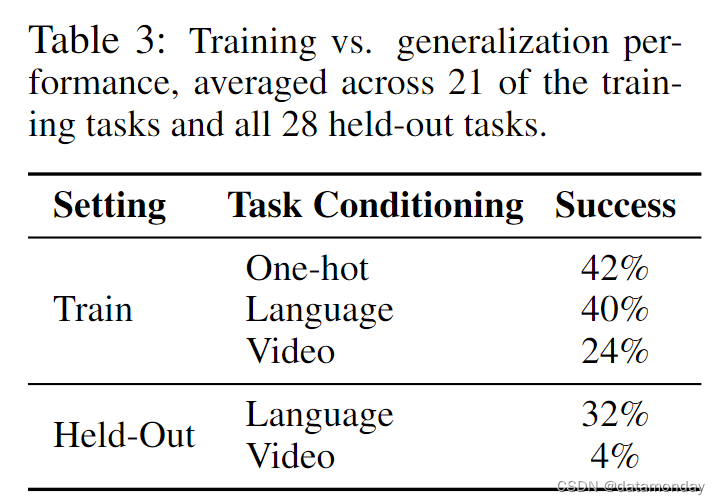
既然我们看到 BC-Z 可以在一定程度上泛化到相当数量的保留任务,那么我们要问的是,其性能是否更多地受到编码器 q ( z ∣ w ) q(z|w) q(z∣w),控制层 π ( a ∣ s , z ) π(a|s,z) π(a∣s,z) 或两者的泛化的限制。为了将这些因素区分开来,我们从三个方面测量了训练任务的策略成功率:单样本任务标识符,训练任务命令的语言嵌入以及训练任务中被保留的人类视频的视频嵌入。比较结果见表 3。单样本和语言为条件的性能相似,这表明潜在语言空间是足够的,而对 held-out 任务进行语言条件化的性能瓶颈在于控制层而非嵌入层。视频条件策略的性能下降更为明显,这表明从视频中推断任务要困难得多,尤其是对于 held-out 任务。
6.3 Ablation Studies and Comparisons
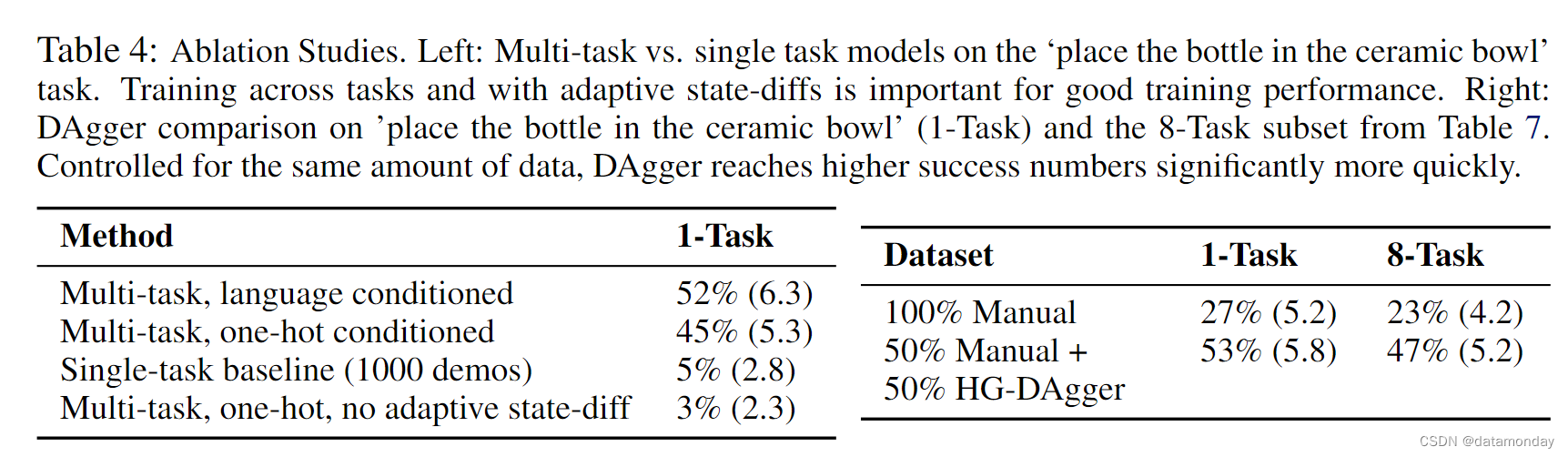
我们利用(训练)21 个任务系列验证了 BC-Z 设计决策的重要性。我们的第一组消融对 “将瓶子放入陶瓷碗中” 命令进行了评估,这是所有任务中演示次数最多的任务(1000 次)。我们首先测试了多任务训练是否有助于提高性能:我们比较了在所有任务的 25,877 个演示中训练的多任务系统和仅在目标任务的 1000 个演示中训练的单任务策略。在表 4(左)中,单任务基线的成功率仅为 5%。这一低成功率与第 6.2 节中 “放置任务” 的单任务低成功率是一致的:收集多个机器人和操作员的数据可能会增加任务的学习难度。只有在多个任务中汇集数据时,BC-Z 才能学会解决任务。我们消减了第 5.3 节中描述的自适应状态扩散方案,并发现该方案非常重要;当天真地选择 N = 1 个未来状态来计算专家行动时,策略会与噪声相匹配,且移动速度太慢,导致状态偏离良好轨迹。
接下来,我们在保持数据总量不变的情况下,减少了 HG-DAgger 的使用。具体来说,我们比较了使用 50% 专家演示和 50% HG-DAgger 干预所训练的策略与使用 100% 专家演示所训练的策略的性能。在表 4(右)中,我们发现在 "将瓶子放入陶瓷碗中 "任务和其他 7 个训练任务中,HG-DAgger 都比克隆专家演示显著提高了任务性能。附录 K 提供了更多比较详情。最后,在图 5 中,我们评估了衡量 HG-DAgger 干预是否能为我们提供策略性能的实时代理(live proxy)。我们发现,干预频率与策略成功率成反比,策略成功率的衡量标准是不需要干预的成功 episode 的比例。这一结果表明,我们确实可以将这一指标与 HG-DAgger 一起用于开发目的。
7 Discussion
我们介绍了一种多任务模仿学习系统,该系统将灵活的任务嵌入与在 100 个任务演示数据集上进行的大规模训练相结合,使其能够根据用户提供的语言或视频命令泛化到训练中未见的全新任务。我们的评估涵盖了 29 项未见过的基于视觉的操作任务,涉及各种物体和场景。我们的实证研究得出的主要结论是,简单的模仿学习方法可以在不增加机器人任务数据的情况下,扩展到新的任务。也就是说,我们了解到,我们不需要更复杂的方法来实现任务级的泛化。通过实验,我们还了解到,100 个训练任务足以实现对新任务的泛化,HG-DAgger 对于良好的性能非常重要,而冻结预训练的语言嵌入则无需任何额外训练即可成为出色的任务条件。
我们的系统确实存在一些局限性。
- 首先,新任务的表现差异很大。不过,即使是在不太成功的任务中,机器人的行为也常常表明它至少理解了任务的一部分,比如伸手去拿正确的物体或执行与语义相关的动作。这表明,未来工作的一个令人兴奋的方向是将我们的策略用作通用初始化,对下游任务进行微调,在此基础上进行额外的训练(也许是自主 RL),从而显著提高性能。
- 我们的语言命令结构遵循简单的 “(动词) (名词)” 结构。解决这一限制的一个方向是使用各种人类提供的注释对数据集进行重新标注[24],这样可以使系统处理语言结构中更多的变化。
- 另一个限制因素是视频条件策略的性能较低,未来在改进基于视频的任务表征的泛化和提高模仿学习算法整体性能方面的研究应该更加关注,因为低层次控制错误也是一个主要瓶颈。
※ A Teleoperation Interface
人类遥操作器包含两个无线 Oculus Quest 控制器,并使用相同的接口对所有任务执行演示。当保留 override 按钮(右控制器上的离合器)时,机械臂跟踪控制器的位置和方向。机器人可以在自主模式和手动模式之间切换。在手动模式下,机器人仍然保持不变,除非操作员移动它。在自主模式下,机器人遵循学习策略,除非操作员覆盖它。

※ B Data Collection Details

B.1 Inter-task Variability
B.2 Robotic Teleoperation
B.3 Human Video Data Collection
C Featurization Details
D Policy Training Details
E Video Conditioning Details
E.1 Video Preprocessing and Architecture
E.2 Ablation on Video Encoder Batch
F Video Embedding Visualization
※ G Data Annotation Visualization
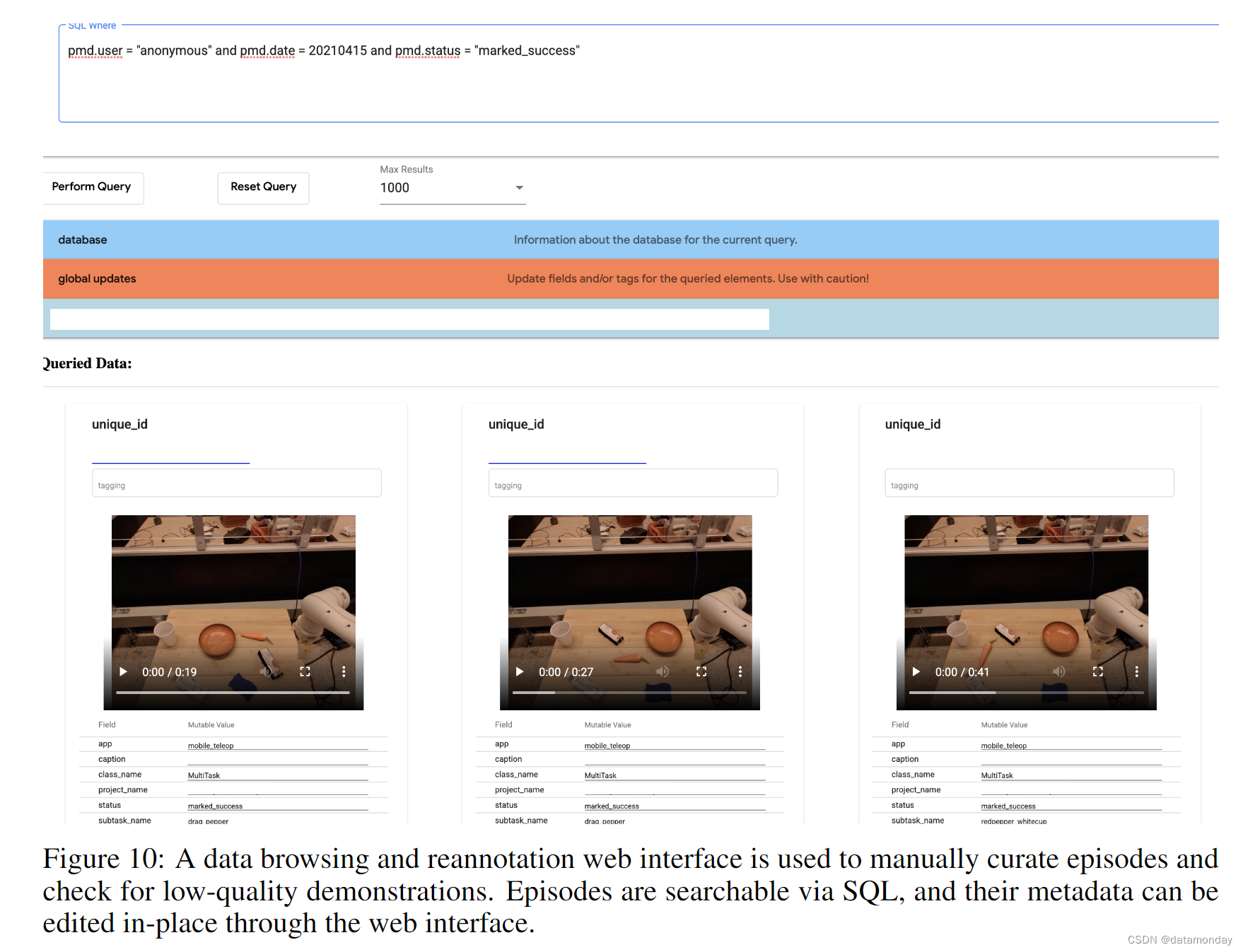
在数据收集期间,远程操作员偶尔会记录不成功的演示作为成功,反之亦然。为了修复这些错误,我们构建了一个数据可视化器,其中可以通过对其元数据的 SQL 查询检索演示,然后重新注释。除了修复不正确的标签外,我们还使用该工具来执行一般的数据清洗,例如标记机器人硬件故障的演示,演示中机械臂遮挡了目标物体。该界面如图 10 所示。
H Single-Task Validation on Bin-Emptying
I Single-Task Validation on Door Opening
J Multi-Task Manipulation Training Task
K Details on HG-DAgger Ablation
L Negative Results
M Further Video Embedding Comparisons
这篇关于【EAI 013】BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









