本文主要是介绍图像质量的评价指标【PSNR/SSIM/LPIPS/IE/NIE/Prepetual loss】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
做插帧这么久了,这几个指标还没系统的研究过,这次开一个博客写下这几个指标的区别
这里贴一个比较全的评价指标的库https://github.com/csbhr/OpenUtility/tree/c9cf713c99523c0a2e0be6c2afa988af751ad161
以以下两张图为例
预测图片

真实图片

MSE
MSE(mean squared error)均方误差
公式如下:
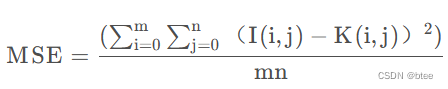
即两张图片对应像素点数的差的平方求平均,这里可以理解为带噪声图像与干净图像之间的噪声
对于这两张0-255的取值范围的图片,MSE的值为20.3308
对于上图真值图片和一张全黑图片(值为0),MSE的值为15907.2259
对于全白图片和全黑图片,MSE的值为255*255=65025
而将该两张图片过Tensor后缩放成0-1之间,MSE的值为0.0003
显然,MSE的值的大小和图片本身是有关的
PSNR
PSNR(Peak Signal-to-Noise Ratio)
PSNR即峰值信噪比,衡量的是对应像素之间的相近程度
公式如下
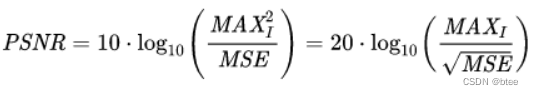
MSE即上图的均方误差。MAXI为图像中像素颜色的可以取到的最大数值,即255
PSNR则是反映MSE的相对大小情况
如上图与真值的PSNR为35.054(Unit8)
将上图缩放为0-1之间,PSNR为35.229(float64)
这两种情况的取值不一样!!!
以及,直接用unit8相减减不出负值,会溢出,而平方的取值范围达不到,最后的MSE的值会不准,导致PSNR结果不对
至于峰值信噪比和信噪比之间的关系(信噪比我理解的是预测图片像素值的均方和),这里我理解的是将图片的信号值变成最大数值,可以规避掉图片由于RGB绝对值很小带来的PSNR值很小的情况,导致同样噪声情况下,亮度值大的图片比亮度值小的图片PSNR值高
这里还值得注意的是,若MSE的值为0,会导致PSNR取值无限大,因此会采用加上一个小的值到MSE上,进行截断,比如加上1e-8,因此PSNR最大值为128.13080360867912
而MAX平方/MSE永远>=1,因此PSNR的值不会为负(是负的就是算错了分子分母上下的值没搞对)
SSIM
【论文】
SSIM(structural similarity index)结构性相似指标
评价一张图片的亮度 (luminance )、对比度 (contrast ) 和结构 (structure)
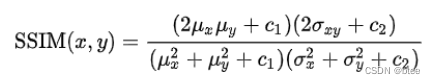
亮度用均值表示
标准差,协方差作为对比度的表示

作为结构的表示
SSIM和PSNR的差别
a作为gt,以下5张图有着同样的PSNR值,但是SSIM值差别很大

同时,SSIM只是计算的一个小窗口内图像的亮度、对比度、结构的值得相似程度(三者是不相关的),通过逐像素滑窗求平均,可以得到整幅图像的MSSIM
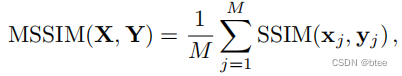
LPIPS
Learned Perceptual Image Patch Similarity (LPIPS) 感知图像块相似性
来源于CVPR2018年的一篇论文【here】
其主要思想是用CNN网络学到一些深层特征,再求得两张图片的深层特征之间的距离
网络的搭建如下:
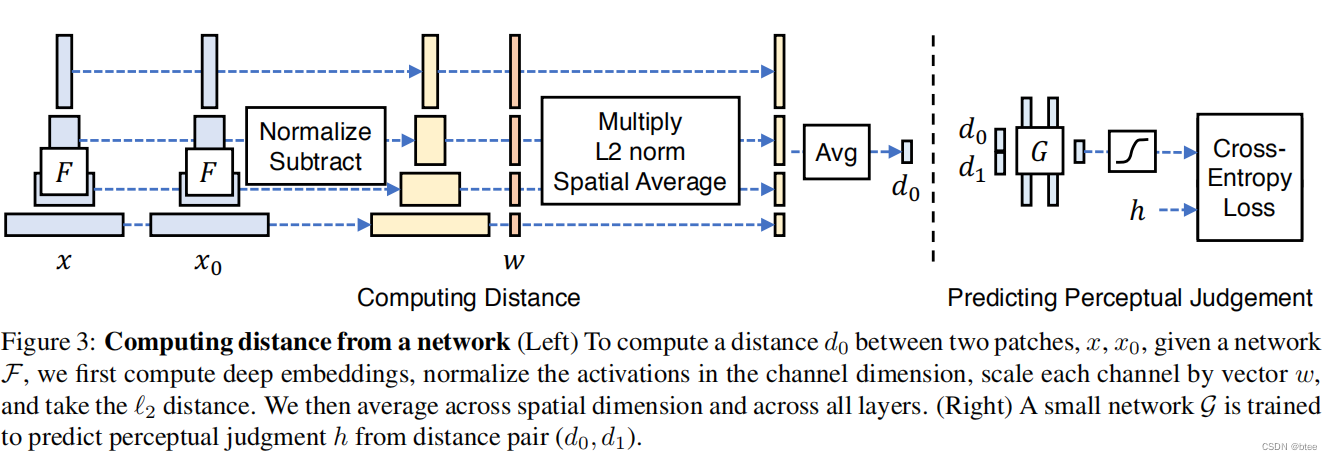
首先F即是不同的CNN网络,有Alexnet,VGG,squeeze,过了网络之后得到不同层的特征图y,将这些特征图在通道维进行单位归一化,
然后对特征维的不同通道乘上一个缩放因子,再将两张图的特征做l2损失,最后不同层的特征求得损失求平均得到一个距离d0=(x,x0)
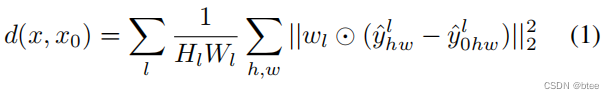
而右边的预测感知评价则是跟数据集有关。这里作者先介绍了一种评价图片相似程度的准则,2AFC similarity judgments,简称AFC,一组图片中有三张图片组成,其中两张图片分别与另一张图片配对,得到(x,x0)(x,x1),然后由人去判断哪张图片与参考图片更相似一点,最后两个配对的置信度分别由支持人数的比例构成,比如5个人里4个人觉得第一组更接近,那么第一组的置信度就是80%,第二组就是20%,最后这一组三张图片回答得到一个总的分数,总的分数的计算规则为p * p+(1-p) * (1-p)
因此通过网络G,将输入的两组距离映射得到一个输出分数,与地面真值相比使最终的损失最小
并提出三种不同的训练策略:-lin ,只训练最后一层的分类头,-tune,预训练之后做微调,-scratch高斯初始化后从头训
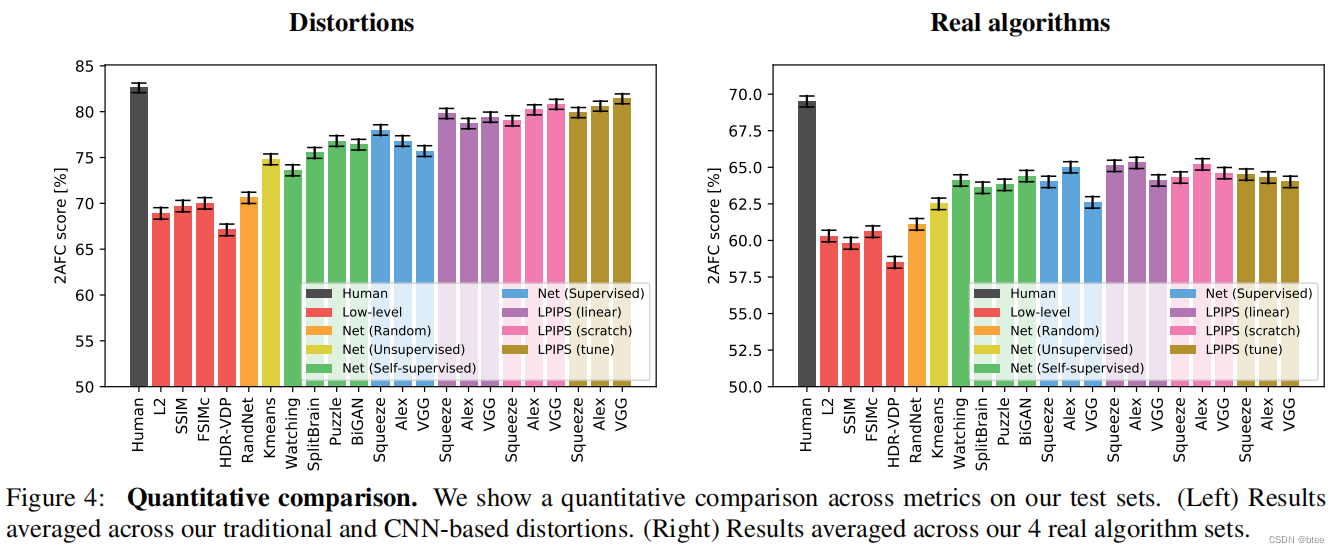
这是一些作者给出的结果,可以看到在认为设计的扭曲数据集上和算法生成的扭曲的数据集上,LPIPS 得到的分数都是跟人最接近的
用起来也比较简单,导个包就好了,作者再代码主页也介绍得比较详尽了
这篇关于图像质量的评价指标【PSNR/SSIM/LPIPS/IE/NIE/Prepetual loss】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








