相关文章

KL散度(Kullback-Leibler divergence)
K L KL KL散度( K u l l b a c k − L e i b l e r d i v e r g e n c e Kullback-Leibler\ divergence Kullback−Leibler divergence),也被称为相对熵、互熵或鉴别信息,是用来衡量两个概率分布之间的差异性的度量方法。以下是对 K L KL KL散度的详细解释: 定义 K L KL

信息熵,交叉熵,相对熵,KL散度
熵,信息熵在机器学习和深度学习中是十分重要的。那么,信息熵到底是什么呢? 首先,信息熵是描述的一个事情的不确定性。比如:我说,太阳从东方升起。那么这个事件发生的概率几乎为1,那么这个事情的反应的信息量就会很小。如果我说,太阳从西方升起。那么这就反应的信息量就很大了,这有可能是因为地球的自转变成了自东向西,或者地球脱离轨道去到了别的地方,那么这就可能导致白天变成黑夜,热带雨林将
从概率角度出发,对交叉熵和 KL 散度进行分析和推导
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 1. 定义与推导 交叉熵(Cross Entropy) 交叉熵是一个衡量两个概率分布之间差异的指标。在机器学习中,这通常用于衡量真实标签的分布与模型预测分布之间的差异。对于两个概率分布 P P P 和 Q Q Q,其中 P P P 是真实分布, Q Q Q 是模型预测分布,交叉熵的定义为:
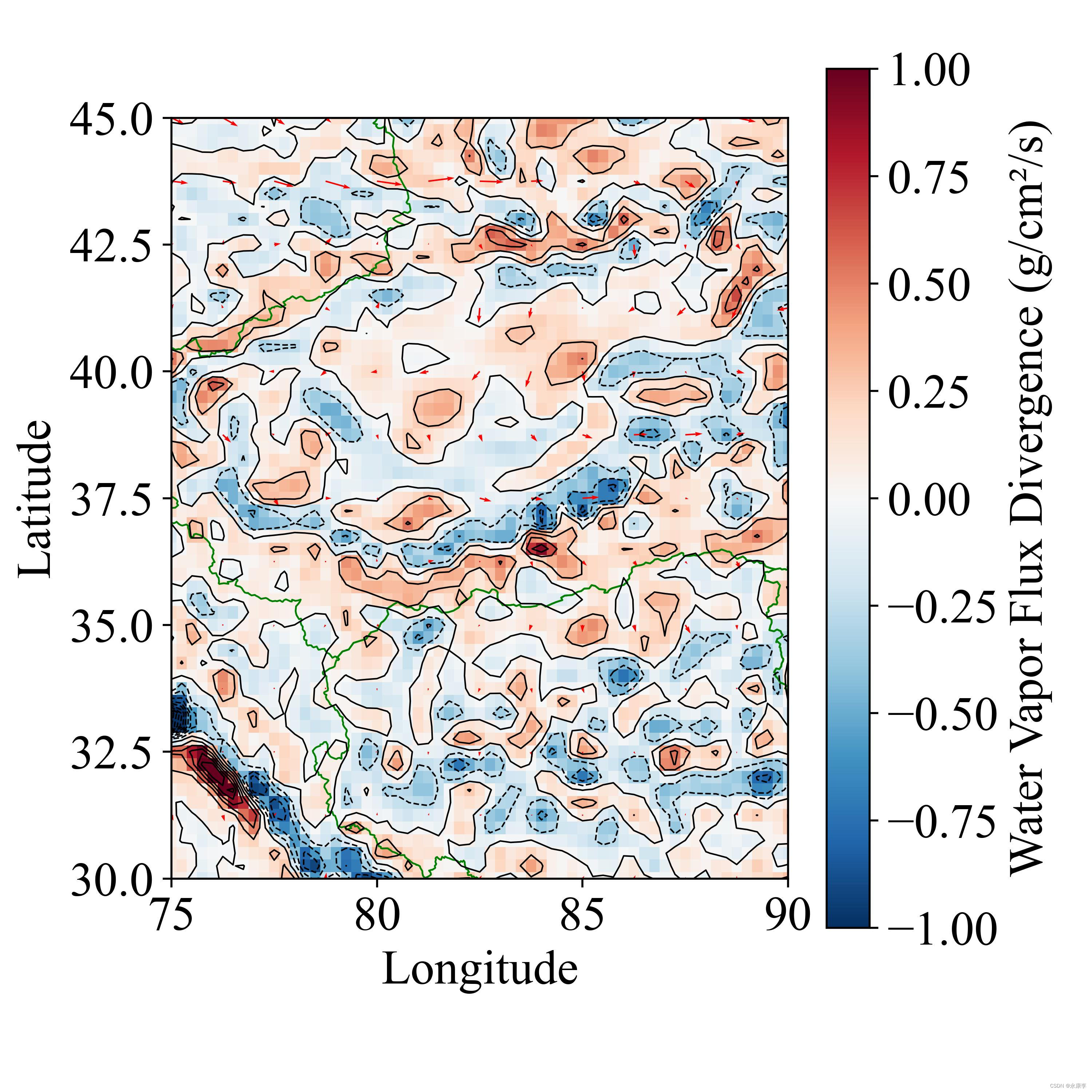
python ERA5 画水汽通量散度图地图:风速风向矢量图、叠加等高线、色彩分级、添加shp文件、添加位置点及备注
动机 有个同事吧,写论文,让我帮忙出个图,就写了个代码,然后我的博客好久没更新了,就顺便贴上来了! 很多人感兴趣风速的箭头怎样画,可能这种图使用 NCL 非常容易,很多没用过代码的小朋友,就有点犯怵,怕 python 画起来很困难。但是不然,看完我的代码,就会发现很简单,并且也可以批量,同时还能自定义国界等shp文件,这对于发sci等国际论文很重要,因为有时候内置的国界是有问题的。 数据 本

【域适应】基于散度成分分析(SCA)的四分类任务典型方法实现
关于 SCA(scatter component analysis)是基于一种简单的几何测量,即分散,它在再现内核希尔伯特空间上进行操作。 SCA找到一种在最大化类的可分离性、最小化域之间的不匹配和最大化数据的可分离性之间进行权衡的表示;每一个都通过分散进行量化。 参考论文:Shibboleth Authentication Request 工具 MATLAB 方法实现 SCA变换实

KL散度交叉熵信息熵不确定性信息度量
0.起源 物理学中的热力学 熵:度量分子在物理空间中的混乱程度; 1.信息熵 信息熵: 度量信息量的多少; 以离散信息为例 离散符号:x1,x2,…,xn; 信息中各符号出现的概率:p1,p2,…,pn; 信息的不确定性函数: f: p—f(p); p越大,信息的不确定性越小,因此f是一个 减函数; 假设前提: 各符号的出现是相互独立的(与实际不符) 则:f(p1,p2)=f(p1)+f(p

KL divergence(KL 散度)详解
本文用一种浅显易懂的方式说明KL散度。 参考资料 KL散度本质上是比较两个分布的相似程度。 现在给出2个简单的离散分布,称为分布1和分布2. 分布1有3个样本, 其中A的概率为50%, B的概率为40%,C的概率为10% 分布2也有3个样本: 其中A的概率为50%,B的概率为10%,C的概率为40%。 现在想比较分布1和分布2的相似程度。 直观看上去分布1和分布2中样本A的概率是一样的

熵、交叉熵和KL散度的基本概念和交叉熵损失函数的通俗介绍
交叉熵(也称为对数损失)是分类问题中最常用的损失函数之一。但是,由于当今庞大的库和框架的存在以及它们的易用性,我们中的大多数人常常在不了解熵的核心概念的情况下着手解决问题。所以,在这篇文章中,让我们看看熵背后的基本概念,把它与交叉熵和KL散度联系起来。我们还将查看一个使用损失函数作为交叉熵的分类问题的示例。 什么是熵? 为了开始了解熵到底指的是什么,让我们深入了解信息理论的一些基础知识。在这个
KL散度 pytorch实现
KL散度 KL Divergence D K L D_{KL} DKL 是衡量两个概率分布之间的差异程度。 考虑两个概率分布 P P P, Q Q Q(譬如前者为模型输出data对应的分布,后者为期望的分布),则KL散度的定义如下: D K L = ∑ x P ( x ) l o g P ( x ) Q ( x ) D_{KL} = \sum_xP(x)log\frac{P(x)}{Q