本文主要是介绍基于深度强化学习与多参数域随机化的水下机械手自适应抓取研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
源自:信息与控制
作者:王聪, 张子扬, 陈言壮, 张奇峰, 李硕, 王晓辉, 王森
引 言
水下机械手在海洋科考、海洋工程、搜救打捞等领域应用广泛,是目前水下有缆遥操作潜水器(remotely operated vehicle,ROV)与载人潜水器(human occupied vehicle,HOV)最主要的作业工具之一[1]。水下机械手目前主要分为两大类:液压机械手和电动机械手。其中,电动机械手主要以小型轻负载为主,多用于小型观察级ROV;而液压机械手具有易密封、负载大、响应快等优点,在海洋工程领域具有广泛的应用,也是目前作业型ROV与HOV的标配作业工具之一。然而,目前水下机械手的实际控制方式多以遥操作为主,其精度与性能等指标与目前成熟的工业机械臂相比存在较大差距,控制精度较低,尤其是水下液压机械手相比于电动手在自主作业的实际应用案例较少。由于水下机械手仍然是目前海洋作业中最主要的工具之一,因此对其自主作业能力进行深入研究,具有很高的理论与应用价值。
水下机械手自主作业的研究具有较长的历史,国内外均开展了大量研究,如文[2-4]。其中,视觉伺服是水下自主作业的一种常用方法[5-6]。针对一些水下典型任务,通过视觉识别目标并实现抓取等操作。相比于固定任务的预编程方式[7],视觉伺服具有一定的灵活性,但是以常见简单任务为主。3D激光相比单纯的RGB(red green blue)图像可以提供更多的3维信息,有助于提升复杂作业任务能力[8],但是也会导致其系统的成本、可靠性、复杂度等的增加。水下机械手的控制规划任务,也是自主作业一个重要基础,比如力/位置结合的操作空间控制[9]、机械臂的运动补偿[10]等,但是受限于水下机械手的传感器、控制精度等,目前还较难达到陆地上机械手的作业精度与效率。
强化学习起源于马尔可夫决策过程,是不同于传统控制理论的一种范式,早期的强化学习多应用于小规模、离散变量等问题。自从DeepMind提出深度强化学习理论,并且在围棋方面取得了令人瞩目的成果之后[11],深度强化学习方法开始在很多领域发挥优势,包括机器人领域[12],比如学习操作魔方[13]、四足机器人行走[14]、投掷物体[15]、双足机器人行走[16]等复杂应用,效果均超过了传统方法。目前强化学习在水下机器人领域研究较少,这与水下机器人的复杂度以及水下工作环境有直接关系,已有研究包括AUV的底层控制[17]、深度控制[18],水下蛇形机器人控制[19],水下机械手基于力矩与位置约束的控制[20]等。因此,强化学习在水下机器人领域的控制、规划、决策等方面的应用有待开展进一步研究。
强化学习在机器人领域应用的关键问题之一,就是从仿真环境到真实机器人的迁移适应能力,即Sim2Real问题,相关研究包括基于视觉的迁移[13, 21],动力学参数随机化[22],自适应仿真随机化[23-24]等。水下环境相比于陆地环境而言,其水动力、浮力、外界扰动等更为复杂多变,陆地上的方法一般难以直接迁移到水下机器人进行应用,因此目前在水下机器人强化学习训练与迁移方面的研究较少。如何针对水下机器人与水下环境的特殊性进行分析与设计,使得强化学习的训练更有针对性,对于强化学习在水下机器人领域的研究与应用具有重要意义。
本文以水下机械手自主作业为研究背景,基于强化学习搭建了具有参数自适应能力的控制器,通过对水下机械手的特性进行详细分析,开展基于多参数的域随机化研究,包括机械手动力学参数、水动力与外界扰动以及强化学习动作空间与状态空间的噪声和延时等。为了测试所提方法的有效性,本文从两个方面进行验证,一方面在另一款新的机器人仿真环境下进行强化学习策略的迁移实验,另一方面在一款真实的深海液压机械手上进行水池实验与分析。实验表明,本文所提方法对于水下机械手作业具有较好的自适应能力。
1 问题概述
本文以3类典型的水下机械手为对象,包括中国科学院沈阳自动化研究所(SIA)自主开发的7功能深海液压机械手[25],以及英国爱丁堡机器人中心的两款水下电动手,开展水下自主作业研究。水下机械手目前存在一些通用的问题,这主要是由于机械手本身的结构、驱动、传感器、工作环境等特点造成的,其中,液压机械手由于液压驱动的复杂性,其高精度轨迹控制的实现难度更高。具体来说,水下机械手目前存在的一些问题包括:
-
1) 关节误差,包括机械结构误差、回程误差、液压机械手的伺服阀控制死区与零漂等。
-
2) 液压机械手的液压系统非线性严重,随着工作时长、工作深度、液压油油温等条件发生变化,会明显影响控制精度。
-
3) 液压机械手关节仅有模拟量的位移传感器,缺少高精度的编码器。
-
4) 液压机械手底层控制频率低,传感器反馈噪声较大。
-
5) 水下工作环境中水动力、浮力、外界扰动等影响。
因此,本文重点关注在强化学习的应用中,如何解决实际水下机械手与仿真模型的差异,也是实际应用的一个主要难点。
2 研究方法
本文所提方法主要涉及3个部分,系统框图如图 1所示,包括强化学习部分、多参数域随机化以及机械手轨迹规划模块,下面将针对3个子系统分别进行阐述。
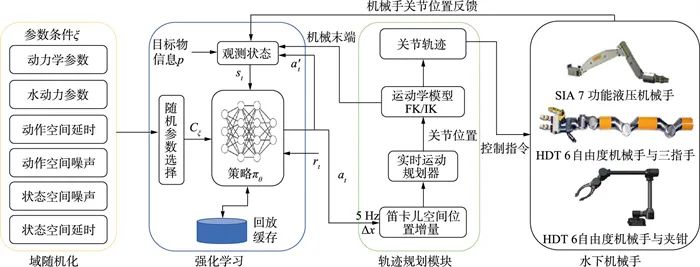
图 1 系统框图
2.1

基于深度强化学习的控制系统设计
强化学习部分是本系统的重要组成部分,本节将具体介绍其涉及到的相关理论基础,以及状态空间、动作空间等的设计问题。
2.1.1
强化学习基础
在强化学习的基本定义[26]中,给定一个环境,智能体(agent)根据当前的状态s∈S通过策略π(a|s)执行一定的动作a∈A,然后获得一定的奖励r∈R。具体来说,在每个控制步骤中,智能体通过观察当前的状态st,从策略π中采样一个动作at,环境响应下一个状态s′=st+1并且获得相应的奖励值rt+1。因此强化学习的目标就是学习最优参数θ使得期望E的回报值最大
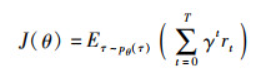
(1)
其中,
![]()
,τ=(s0,a0,s1,…,aT-1,sT)为从t=0到t=T的一个完整轨迹,rt是在t时刻收获的即时奖励,γt∈[0, 1]是在时刻的折扣率。策略梯度是解决强化学习问题的一个基本且有效的方法[26],策略梯度的计算为
![]()
(2)
其中,dθ(st)是在策略πθ下的状态分布;At是优势函数:
![]()
(3)
本文策略学习部分采用PPO(proximal policy optimization)算法[27]。PPO是一个无模型在线强化学习算法,算法易于实现,训练稳定,应用广泛。PPO的更新策略为
![]()
(4)
其中采取随机梯度下降来最大化目标。这里L为
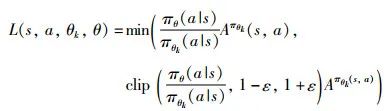
(5)
其中,ε是一个超参,clip表示剪切函数,当
![]()
超过(1-ε,1+ε)的范围则直接取上下极限,使得新策略与旧策略的更新偏差不会过大。
2.1.2
状态空间与动作空间
状态空间的设计与状态变量的选择对于强化学习尤为重要,针对典型水下机械手的控制系统,本文选择的状态变量包括:机械手关节位置、速度,机械手末端位置、姿态、线速度,夹钳状态,目标物位置、姿态以及前3个动作序列,一共包含9个变量,向量维度根据机械手的情况有所不同。
为了避免直接学习关节空间到笛卡儿空间的复杂非线性映射,提高强化学习的效率,本文动作空间的选择为机械手末端位置控制增量(ax,ay,az)以及夹钳(或者多指手)控制量agrasp,包含2个变量,组成一个n维的向量作为控制策略的输出,控制频率为5 Hz,然后通过后面机械手的运动规划器实时计算关节空间的轨迹,并以更高频率发送给机械手底层控制系统。
2.1.3
奖励函数
本文中的奖励函数考虑几个方面的影响,包括抓取成功与否、机械手末端与目标物的距离、机械手动作的平滑性与连续性等,具体的奖励函数为
![]()
(6)
其中,
![]()
为动作控制奖励,主要使机械手的运动幅度较为平滑;
![]()
为轨迹连续性控制奖励,主要使机械手避免发生较大的轨迹跳跃而使机械手产生加速度突变;r3=
![]()
代表机械手末端P1(x1,y1,z1)与目标物P2(x2,y2,z2)之间的距离,并且成反比关系;r4=exp(-100dt2)使机械手末端可以更为精准地到达目标物位置,但是只在近距离范围起作用;r5为抓取成功后的标量奖励值100。ω1~ω5为各个奖励值的权重,根据实际情况进行调整。
2.2

多参数域随机化
域随机化的目的是使训练模型可以从初始训练环境迁移到目标环境,在机器人领域一般指从仿真环境到真实物理环境的迁移。通过在初始仿真环境选取N组随机参数ξ∈CξN进行训练,并且在一定的范围内进行随机选取。因此,强化学习在正常训练中增加了一个参数随机化的过程,使得策略训练的范围更宽,所以泛化性能更好。这里的训练参数由式(1)中的θ变成θ*,而强化学习的目标也转化成在一系列参数ξ下的奖励值回报
![]()
(7)
这里的τ即一系列服从于ξ的轨迹。Cξ代表随机参数空间,针对第2节中涉及到的水下机械手特点,本文将对其相关参数进行分析,以方便后续的随机化处理。
2.2.1
动力学参数
水下机械手受工作环境等因素影响,其工作状态的动力学模型难以像工业机械手一样精确稳定,因此,本文对机械手以及目标物相关的一些重要参数进行随机化,具体包括:
-
∙每个连杆的质量
-
∙每个关节的阻尼系数
-
∙目标物的质量、摩擦系数
-
∙桌子高度
2.2.2
水动力参数
机械手在水下作业时,还会受到水动力的影响,这也是其与陆地上机械手作业的一个重要区别。此处增加与水动力相关的重力g、流体密度ρ以及流体粘性阻力系数β等参数,用以模拟机械手实际作业受到的浮力、水动力等各种影响。
水动力的模拟本身非常复杂,有很多专业软件可以进行高精度的模拟计算,但是本文主要考虑机器人在运动过程中受到的水动力对作业过程的影响,因此重点关注与运动相关的流体密度ρ与流体粘性阻力系数β。这里把每个连杆的形状都简化为一个等效惯性体,即每个机械手的连杆都采用基本的圆柱体进行简化计算。连杆在相对于线速度的正方向受到力的作用,v代表连杆在局部坐标系下的线速度,Cd代表拖拽系数,A代表相对于水流方向的横截面积,i为连杆序号。因此,根据Morison方程[28],每个连杆基于流体密度ρ受到的被动力为
![]()
(8)
其中,vi代表第i个连杆在局部坐标系下的线进度。
基于流体粘度β受到的力为
![]()
(9)
其中,D表示圆柱体的直径。
后面将根据机器人模拟器进行相关参数的设置。
2.2.3
动作空间响应
机械手在实际作业中,控制指令的传输通常需要经过较长的线缆,尤其是在深海的ROV作业模式下,难以保证精确的时序控制。因此,本文采用增加一个随机的时延以及一定的噪声来模拟实际情况,其中随机时延为
![]()
(10)
其中,T代表随机时间。
随机噪声σ1为
![]()
(11)
其中,at是每一步的动作,a′t是含有噪声的动作,σ1服从高斯分布
![]()
(0,0.1)。
2.2.4
状态空间
液压机械手的关节位置反馈采用基于模拟信号的电位计,原始数据噪声较大,在经过均值滤波后,仍然存在一定程度的噪声。因此,本文在状态空间中也加入类似于动作空间的时延与噪声,其中时延为
![]()
(12)
随机噪声σ2为
![]()
(13)
其中,st是每一步的状态,s′t是含有噪声的状态,σ2服从高斯分布
![]()
(0,0.1)。
2.3

轨迹规划模块
强化学习模块的输出为机械手的笛卡儿空间轨迹,因此本文设计了一个轨迹规划模块,如图 1所示。在接收到低频率的控制轨迹指令后,笛卡儿空间的位置增量与机械手当前状态结合,确定下一步的目标位置;然后通过运动学模块计算;最后获得实时的关节轨迹,发送到机械手的底层控制系统。
为了保障该轨迹规划模块的通用性,机械手的运动模型将根据实际机械手的参数进行修改,保证运动学正逆解的计算可以实时、准确、高效。其余部分则具有良好的模块化特点,保证迁移到不同的机械手仅需要做出少量的修改。另外,由于不同机械手的实际控制接口与控制频率存在差异,因此需要将接口部分进行抽象化,以保证系统的模块化特点。
3 仿真实验
本文采用MuJoCo[29]作为强化学习的仿真训练环境。MuJoCo是一款优秀的物理仿真器,在建模、速度、精度等方面都有较好表现,尤其针对抓取任务中物体之间的接触力可以实现较为精确的模拟计算。另外,MuJoCo可以模拟空气或者水中介质的流体阻力等参数,因此满足本文中的水下机械手工作环境的仿真要求。
3.1

仿真设置
本文在中国科学院沈阳自动化研究所开发的水下自主作业平台[30]的与英国爱丁堡机器人中心两款水下电动机械手的基础上,在MuJoCo环境构建了三类水下机械手的模型,分别如图 2所示。常见的水下作业任务中有很多典型的目标物,其形状较为规则化,因此在本文中的抓取目标设定为两类基本的目标物:立方体和圆柱体。抓取目标放在一个桌子之上,用于模拟实际的抓取实验。强化学习的策略学习部分采用PPO (proximal policy optimization)算法[27],其相关参数如表 1所示。

图 2 三款水下机械手模型

表 1 PPO算法参数
本文在MuJoCo仿真环境中实现了多参数的域随机化,同时与强化学习进行联合训练。其中,机械手动力学参数和水动力参数在强化学习的每个周期开始随机选择一组参数,状态空间和动作空间的噪声则在每个训练步骤中进行添加,主要参数如表 2所示,系数为在各个默认参数值基础上的比例系数或者增加的附加项。
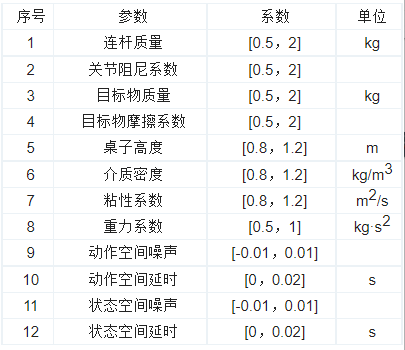
表 2 域随机化参数选择
在每个强化学习训练周期的开始,机械手和目标物都会随机初始化一个位置,其余参数也会进行随机化的选取。每个训练周期的结束条件是目标物抓取成功或者达到周期训练步骤的上限,每个训练周期为200步。通过并行化训练,每个训练周期大约为3 h。
3.2

仿真分析
为了测试算法训练与学习的稳定性,本文在PPO的基础上,另外选取了PG(policy gradient)、A2C(advantage actor-critic)、APPO(asynchronous proximal policy optimization)[27]三种算法作为比较,4种算法的训练中均添加了多参数的域随机化过程,每个算法采用3个随机种子训练后取平均值。图 3为训练过程中的奖励回报值曲线,其中,图 3(a)为最大奖励值,图 3(b)为平均奖励值,PPO在1×106步以内可以实现收敛,收敛后的最大回报值约为9 000,平均回报约为7 000。其余3种算法中,A2C可以收敛,但是不稳定,PG和APPO不能实现收敛。
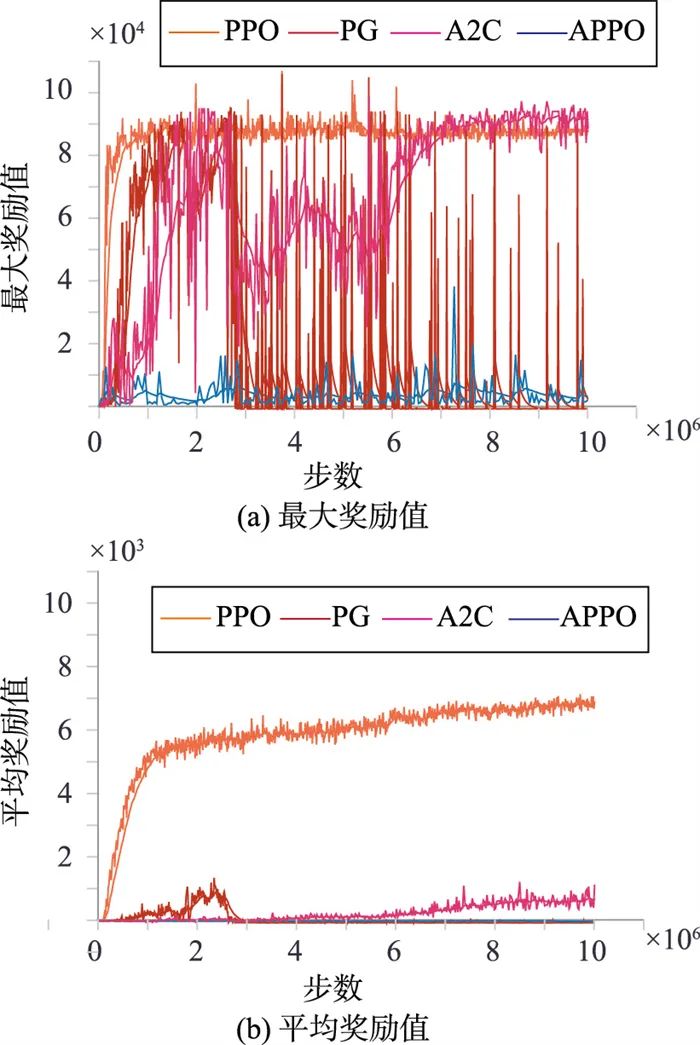
图 3 训练的奖励值
图 4所示为训练过程中的抓取成功率,相比于奖励回报,成功率曲线更能够体现训练任务的效果。其中,图 4(a)为训练中抓取的最大成功率,图 4(b)为抓取平均成功率,PPO算法基本上可以实现在1×106步骤以内的快速收敛,同时训练稳定性更高,明显优于其他三种算法。图 5为动作空间的输出,分别为夹钳以及机械手末端在x、y、z三个方向上的输出值。
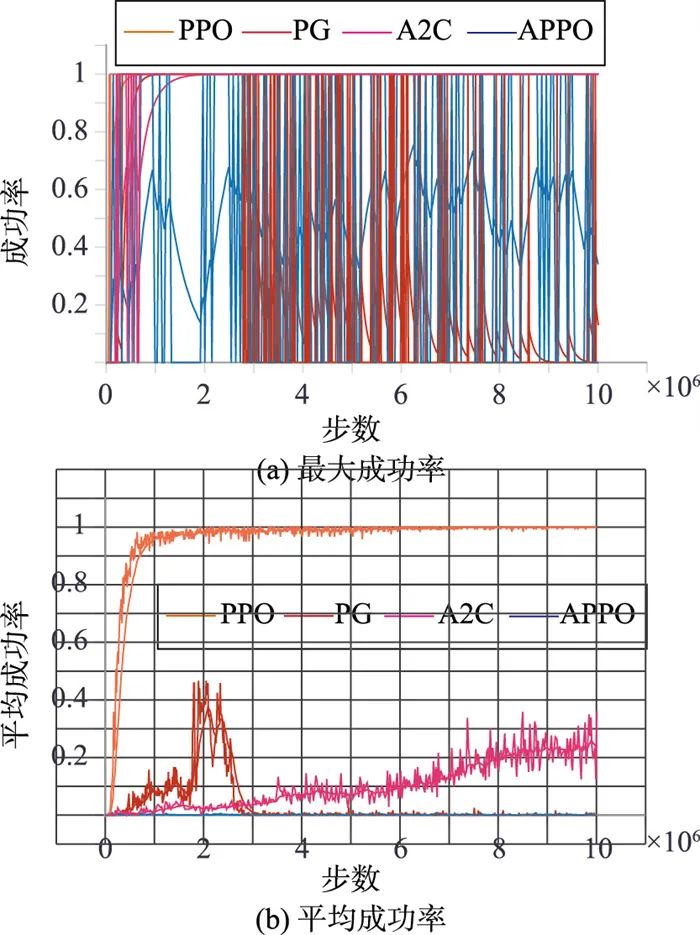
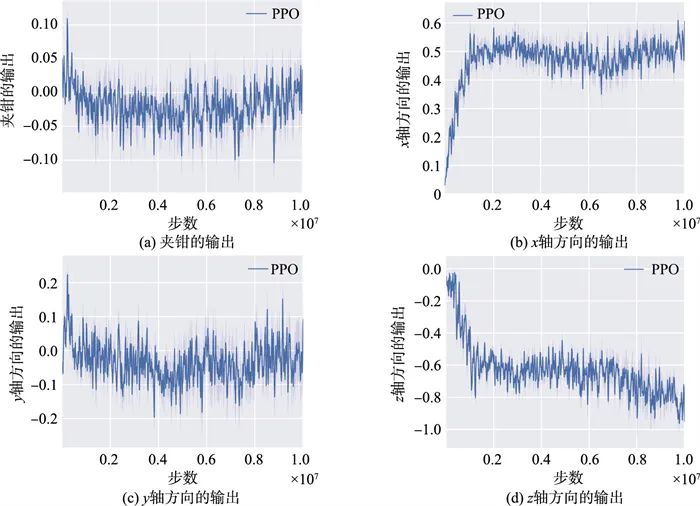
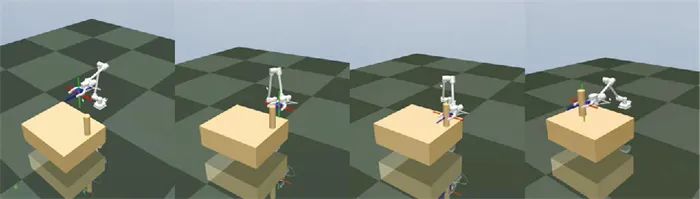
图 6~图 8分别展示了三类机械手的抓取训练结果截图,三类机械手结构参数各异,但是都能够实现较好的抓取效果,由此证明所提方法的鲁棒性与泛化性较好。


4 实 验
策略迁移的效果是强化学习在机器人领域应用的难点之一,因此为了验证前面所提方法的有效性,实验部分在两个方面进行了验证,包括迁移到另一款不同类型的仿真器以及真实机械手的水下抓取实验。
4.1 不同仿真环境的迁移实验
Gazebo[32]是机器人领域比较流行的一个开源的多刚体动力学仿真器,与机器人操作系统(robot operating system,ROS)[33]无缝集成,更新迭代较快,是当前主流的机器人仿真器之一。UUVSimulator[34]是在Gazebo基础上开发的一个水下机器人仿真环境,可以方便地模拟机器人在水下环境中的水动力、浮力、扰动等,是目前开源水下机器人仿真器中比较流行的一个。由于不同机器人仿真环境之间的动力学建模、物理仿真等原理不尽相同,因此各个仿真之间会存在差异,也就会导致Sim2Real中的“reality gap”问题的出现。所以测试不同仿真环境之间的迁移性,也代表了一定的泛化能力。
4.1.1 环境设置
Sim2Real迁移的整体系统框图如图 9所示。机器人通过URDF (unified robotics description format)模型在Gazebo中建立物理仿真模型,同时通过UUVSimulator创建水动力模块,用以模拟水动力仿真效果。控制系统整体基于ROS环境搭建,另外构建了完整的运动学规划模块,方便进行策略移植与部署。因此,在MuJoCo中训练的强化学习策略,可以比较方便地部署到Gazebo仿真环境中。
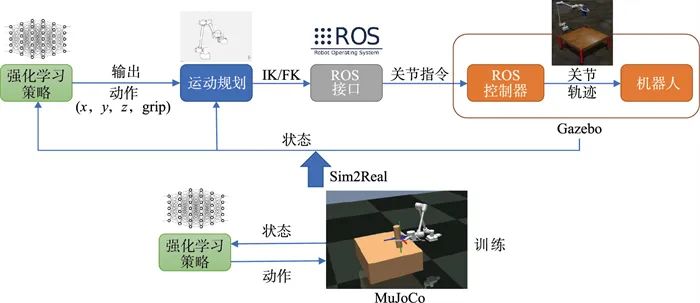
4.1.2 实验过程
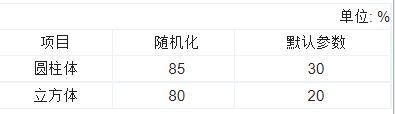
迁移实验针对两种目标物分别进行抓取测试,其中随机化参数与默认参数训练策略各进行20次实验,实验结果如表 3所示。由于MuJoCo与Gazebo两个仿真环境的建模方式有所不同,所用的底层物理仿真器以及水动力模拟计算也不尽相同,因此,直接进行迁移实验的效果较差。在应用了随机化参数后,迁移效果得到明显提升,因此验证了策略迁移的有效性。图 10为一次抓取的实验结果截图。

4.2 7 功能深海液压机械手实验
本文的真实水下抓取实验基于课题组前期搭建水下自主作业平台开展研究[30]。该平台参考深海科考型ROV“海星6000”进行设计,机械手的型号与规格参数与实际ROV保持一致,因此平台具有较高的真实作业模拟能力,通过将前述训练策略应用到该平台的机械手上进行实验,可以验证本文所提方法的实际应用效果。
4.2.1 实验设置
由文[30]可知,实验平台包括液压系统、水下机械手、作业支撑平台(模拟ROV载体)以及水下相机与水下灯等辅助设备,本文主要使用机械手、水下相机、水下灯等子系统。机械手的控制系统采用基于ROS架构进行开发,便于实现模块化与后续扩展,主要功能模块为强化学习训练策略与机械手进行通信,以及辅助的运动学、视觉等模块。
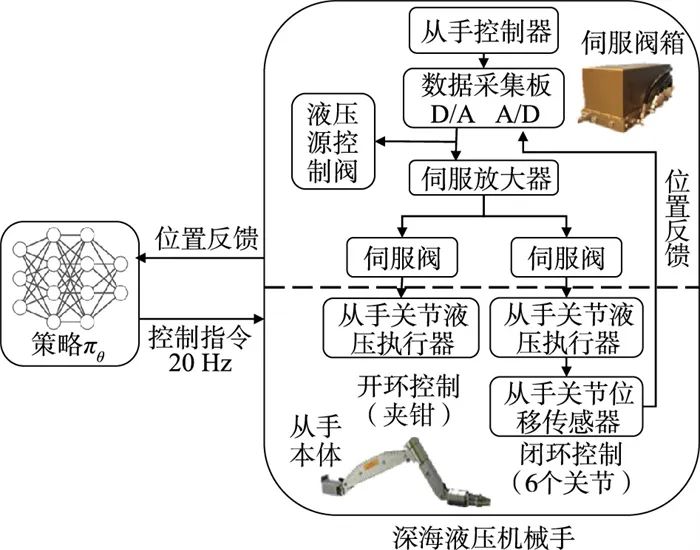
液压机械手的驱动不同于电动机械手,主要基于伺服阀进行控制,如图 11所示为7功能深海液压机械手的底层控制系统,强化学习策略控制器与从手控制器进行通信,从手控制器通过数据采集板来发送与接收机械手各个关节的伺服阀电流控制量与位置传感器反馈,进而实现关节位置闭环的伺服控制。
仿真环境中的目标物位置信息可以直接提取出来,在真实实验中,本文采用基于ArUco的视觉定位方案[35]。相比于双目相机、3D激光等视觉定位系统,该方案只需一个单目相机(DEEPSEA公司生成的Nano SeaCam水下相机)即可实现目标物的准确定位,更为简洁方便,同时具有较高的定位精度,便于开展研究工作。由于水下灯光与相机视野的局限性,相机采用安装于腕部的方案,便于近距离观察到目标物。视觉系统更多具体细节可以参考之前研究[36]。本文采用抓取目标圆柱体与立方体,分别模拟水下作业任务中常见的圆柱形水听器或采样器以及黑匣子等目标物,具有典型性与通用性。
4.2.2 实验过程
实验中目标物的位置姿态信息通过相机与ArUco二维码系统进行定位计算,然后将目标物坐标转换到机械手基坐标系下,作为强化学习的状态输入变量之一。另外,机械手的实时状态反馈信息也作为一个强化学习的基本状态输入变量,包括机械手的关节空间信息、末端笛卡儿空间信息等。
强化学习的控制策略在接收到目标物信息后,结合机械手的当前状态,以5 Hz的频率实时输出对应的控制指令,运动规划器在接收到机械手末端增量的控制指令后,以20 Hz的频率进行轨迹插值,同时调用运动学逆解模块进行实时计算,在获得基本的关节空间轨迹后,通过三次曲线进行插值,保证轨迹中加速度、速度、位置的连续性。
水下两类目标的实际抓取过程分别如图 12和图 13所示,其中,(a)为抓取起始状态,(b)为接近目标物,(c)为目标物的抓取,(d)为目标抓取成功后的结束状态。与仿真环境类似,机械手每次抓取的开始会初始化一个状态,保证目标物在机械手的视野范围内。机械手完成抓取后,会执行一段预设的目标轨迹,目标物被放到一个指定位置,整个作业任务完成。


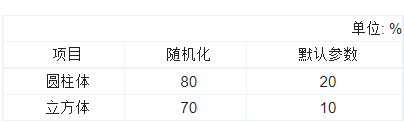
为了充分测试强化学习训练策略的有效性,在水下环境针对两种目标物分别进行了10次抓取实验,实验结果如表 4所示。整体而言,采用随机化参数后的策略抓取成功率明显高于直接采用默认训练参数的抓取成功率,表明从仿真环境直接部署到真实机器人上具有很高的不确定性,这也体现出液压机械手在实际建模与控制方面的复杂性。另外,由于圆柱体的尺寸相比于立方体更有优势,因此实际抓取中成功率更高。
4.3 实验分析
强化学习在机器人的应用中,一个主要的难点之一就是Sim2Real问题,而水下机器人与水下环境和仿真环境相比,误差更大,因此训练出来的模型进行部署和迁移的难度也是很大。为了验证本文所提方法,在Sim2Sim(5.1)与Sim2Real(5.2)两个方面进行了测试与验证,结果表明在增加多种域参数随机化过程后,训练的结果具有更好的鲁棒性与适应性,可以应用到实际的水下机器人上。
5 结论与未来展望
本文针对水下机械手自主作业提出一种基于深度强化学习的通用控制系统,通过详细分析当前机械手在水下作业中存在的问题,提出多参数域随机化与强化学习相结合的控制方法。为了提升机械手系统的整体作业性能,采用强化学习模块与底层控制系统结合,实现整体闭环控制,避免了直接端到端强化学习在机器人实际控制中的稳定性与可靠性不足的问题。最后,搭建的仿真环境与真实机器人实验验证了本文所提方法的有效性,为后续的实际工程应用奠定了良好的基础。
本文研究工作主要针对固定基座下的机械手作业问题,类似于ROV或HOV在实际海底坐底等情况下的作业场景,但在一些复杂的海底环境,ROV/HOV可能并不具备坐底条件,因此浮游状态下的作业便尤为重要。未来将进一步研究水下机械手安装于ROV载体上的浮游状态作业问题,由于系统的不稳定性进一步提升,导致整体的控制难度明显增加,因此如何改进现有的强化学习控制系统,是未来研究的一个难点。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询” 发布
这篇关于基于深度强化学习与多参数域随机化的水下机械手自适应抓取研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




