随机化专题
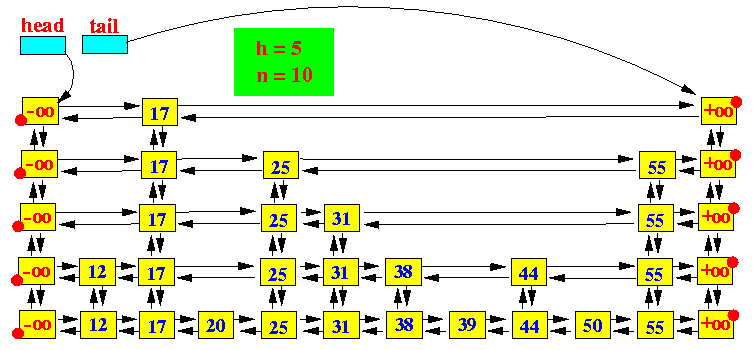
跳跃表-随机化数据结构
Skip list(跳表)是一种可以代替平衡树的数据结构 参考 http://www.mathcs.emory.edu/~cheung/Courses/323/Syllabus/Map/skip-list-impl.html http://www.acmerblog.com/skip-list-impl-java-5773.html Skip list的性质 (1) 由很多层结构组成,l

算法导论 第2版 7.3 快速排序随机化版本
根据书上伪码编写: #include <iostream>#include <ctime>using namespace std;int A[11] = {-1,4,1,8,3,10,2,5,6,9,7};//下标从1开始,因此A[0]不用,用-1标记int n = sizeof(A)/sizeof(int)-1;int partition(int *A, int p, int r)//划

driftingblues9 - 溢出ASLR(内存地址随机化机制)
Site Unreachable driftingblues9easyaPphp GETSHELL、searchsploit使用、凭据收集、gdb使用、缓冲区溢出漏洞(难)、pattern_create.rb、pattern_offset.rb 使用 主机发现 ┌──(kali㉿kali)-[~/桌面/OSCP]└─$ sudo netdiscover -i eth0 -r 192.168
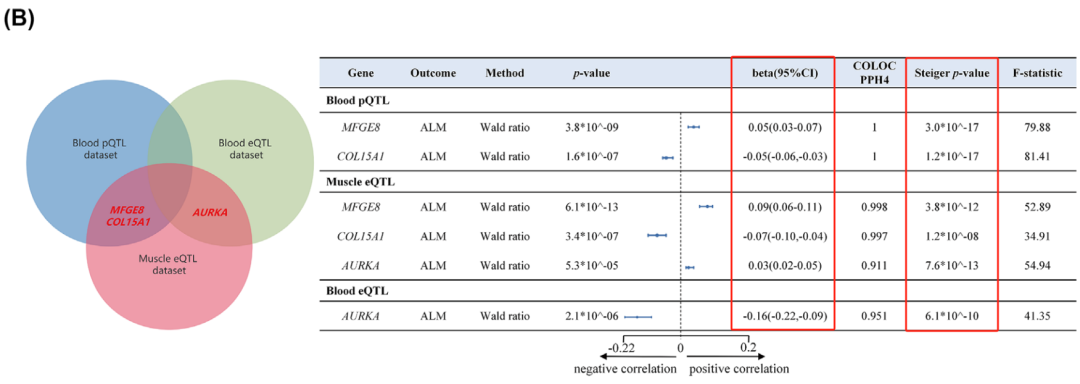
设计严谨,思路绝妙!这篇高级孟德尔随机化研究:药靶、共定位,发文一区(IF=8.9)!...
现在越来越多的学者在用孟德尔随机化高级方法发文,今天我们看的这篇这篇药靶孟德尔随机化,还用了共定位分析方法,亮点在于它的设计严谨,思路绝妙,一起看下去吧! 2024年4月21日,四川大学华西医院陈永平团队做了一项药靶孟德尔随机化研究,在期刊《Journal of CachexiaSarcopenia And Muscle》(医学一区,IF=8.9)发表了题为:“Systematic drugg

Linux内核地址空间随机化ASLR的几种实现方法
ASLR(Address Space Layout Randomization)在2005年被引入到Linux内核kernel 2.6.12中。地址空间随机化在内核中有多种实现和表现方式,下面分别介绍。 堆栈随机化 堆栈随机化是一项安全增强,它允许对系统调用发生时,内核使用的堆栈添加一个随机偏移。这给基于stack的攻击增加了难度,因为stack攻击通常要求stack有个固定的layout。现

如何关掉地址空间随机化
如果我们的ru没有密码的话我们要先建一个密码 接着输入 su 进入root 接着输入 echo 0 > /proc/sys/kernel/randomize_va_space 就可以啦 接着可以cat查看是不是显示0,是的话就成功了
使用 js 代码生成随机化,选取一个范围内的随机数
说到随机数,肯定会想到使用Math.random 但是有几点需要注意 Math.random 没有参数生成一个 0-1 之间的伪随机数浮点数【注意这个返回值小于1】,包含0 ,不包含1 常用的是两个数之间 的整数随机数,要求包含两个边界值 function getRandomIntInclusive(min, max) {const minCeiled = Math.ceil(min);c

Hdu 6804 Contest of Rope Pulling —— 随机化,背包周期
This way 题意: 现在有两个集合的人,每个人都有一个重量和一个价值,你要在每个集合中选择一些人使得两个集合的人的重量之和相同,并且总价值最大。 题解: 题解的想法我在赛场上也想到了,但是我是按照重量排序的,然后就被卡掉,过不去。 但是将所有人放在一起随机化一下的话,我们知道背包就是选择一些数使得他们的重量达到预定的大小的同时让价值之和最大。这道题目就是一个正向背包加一个反向背包使

基于 python 实现的中小学随机化分班算法(思路、实现、代码以及打包好的可执行文件)
文章目录 0. 请勿转作商用!有问题可以添加QQ4705852261. 代码运行情况2. 需要提供的excel格式3. 最终结果4. 算法实现5. 代码6. 下载地址 0. 请勿转作商用!有问题可以添加QQ470585226 1. 代码运行情况 *****************************************************代码会自动分配所有
孟德尔随机化研究中评估因果效应大小的方法
欢迎关注”生信修炼手册”! 孟德尔随机化研究借助遗传变异这一工具变量,来评估暴露因素与结局变量之间的因果效用。为了准确评估因果效应的大小,有多种方法相继被发明。本文重点看下其中常用的两种方法。 1. IVW IVW全称如下 Inverse-Variance Weighted 称之为逆方差加权,由Burgess等提出,文章链接如下 https://onlinelibrary.wiley.co

BZOJ2428——随机化贪心
Description 已知N个正整数:A1、A2、……、An 。今要将它们分成M组,使得各组数据的数值和最平均,即各组的均方差最小。均方差公式如下: ,其中σ为均方差,是各组数据和的平均值,xi为第i组数据的数值和。 Input 第一行是两个整数,表示N,M的值(N是整数个数,M是要分成的组数) 第二行有N个整数,表示A1、A2、……、An。整数的范围是1–50。 (同一行的整数
poj3318(随机化算法)
链接:点击打开链接 题意:给出三个n*n的矩阵A,B,C,问是否存在A*B=C(n<=500) 代码: #include <math.h>#include <vector>#include <stdio.h>#include <stdlib.h>#include <string.h>#include <iostream>#include <algorithm>using nam
基于深度强化学习与多参数域随机化的水下机械手自适应抓取研究
源自:信息与控制 作者:王聪, 张子扬, 陈言壮, 张奇峰, 李硕, 王晓辉, 王森 引 言 水下机械手在海洋科考、海洋工程、搜救打捞等领域应用广泛,是目前水下有缆遥操作潜水器(remotely operated vehicle,ROV)与载人潜水器(human occupied vehicle,HOV)最主要的作业工具之一[1]。水下机械手目前主要分为两大类:液压机械手和电动机械手。其中,

双向孟德尔随机化 | 基础代谢率与心血管疾病因果关系研究发表医学一区文章...
欢迎报名2024年孟德尔随机化方法高级班课程! 郑老师团队开设的孟德尔随机化高级班2024年1月20-21日开课,欢迎报名 2023年12月29日,一篇题为Causal Effects of Basal Metabolic Rate on Cardiovascular Disease: A Bidirectional Mendelian Randomization Study的孟德尔随机化研
Codeforces Round 916 (Div. 3) G2. Light Bulbs (Hard Version)(思维题 随机化哈希)
题目 2n(2<=n<=2e5)个灯泡, 灯泡分n种,每种颜色恰有两个,灯泡颜色用1到i表示 你可以执行以下两种操作若干次: 1. 选择两个同色的灯泡i、j,如果一个亮,但是另一个不亮,就把另一个点亮 2. 选择三个不同位置的灯泡i,j,k(i<j<k),如果i和k都亮了,但是j不亮,就把j点亮 你初始时,可以手动点亮若干个灯泡, 求初始时最少手动点亮灯泡的个数,以及满足个数等于最少

MendelianRandomization | 孟德尔随机化神包更新啦!~(一)(小试牛刀)
1写在前面 今天发现MendelianRandomization包更新v0.9了。😜 其实也算不上更新。🫠 跟大家一起分享一下这个包做MR的用法吧。🤩 还有一个包就是TwoSampleMR,大家有兴趣可以去学一下。😅 2用到的包 rm(list = ls())# install.packages("MendelianRandomization")library(MendelianRand
R语言孟德尔随机化研究工具包(1)---friendly2MR
friendly2MR是孟德尔岁随机化研究中的一个重要补充工具,可以批量探索因素间的因果关系,以及快速填补缺失eaf的数据,但是存在细微差异需要注意。 remotes::install_github("xiechengyong123/friendly2MR")library(friendly2MR)library(friendly2MR)#Based on TwosampleMR, to

算法设计与分析复习笔记第七章随机化(概率)算法
目录 概率算法概述 随机数 数值随机化算法 舍伍德算法 拉斯维加斯算法 蒙特卡罗算法 概率算法概述 随机化算法的基本思想 是一种使用概率和统计方法在其执行过程中对于下一计算步骤作出随机选择的算法。 随机化算法把“对于所有合理的输入都必须给出正确的输出”这一求解问题的条件放宽,把随机性的选择注入到算法中,在算法执行某些步骤时,可以随机地选择下一步该如何进行,同时允许结果以
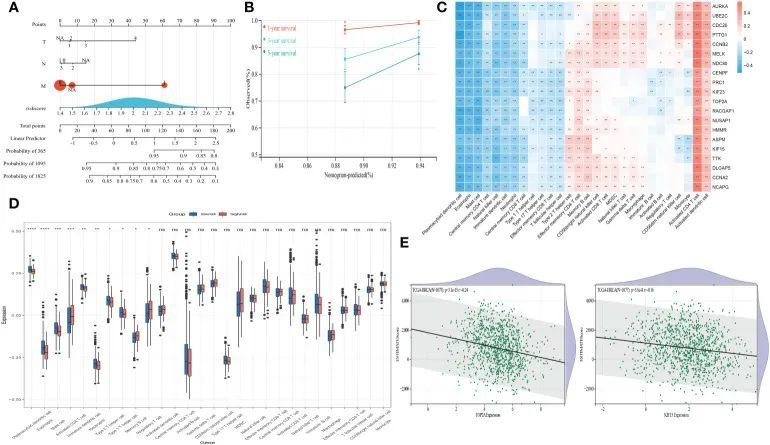
孟德尔随机化+WGCNA+预后模型,7+轻松get
今天给同学们分享一篇生信文章“Exploring the causality and pathogenesis of systemic lupus erythematosus in breast cancer based on Mendelian randomization and transcriptome data analyses”,这篇文章发表在Front Immunol期刊上,影响因子为
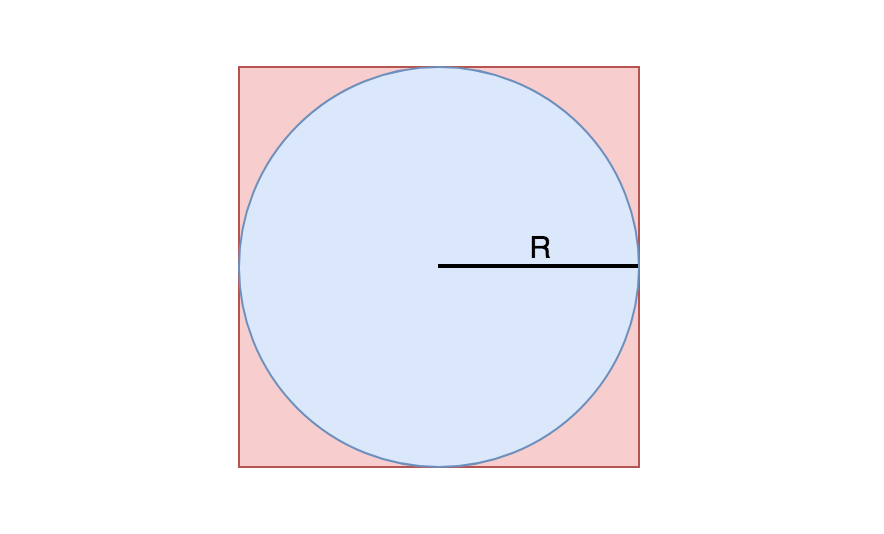
LeetCode-478. 在圆内随机生成点【几何 数学 拒绝采样 随机化】
LeetCode-478. 在圆内随机生成点【几何 数学 拒绝采样 随机化】 题目描述:解题思路一:一个最简单的方法就是在一个正方形内生成随机采样的点,然后拒绝不在内切圆中的采样点。解题思路二:具体思想是先生成一个0到r的随机数len,然后生成一个随机的角度来生成对应的坐标。但是这样并不是等概率的,因为例如 len 有 1 2 \frac{1}{2} 21的概率取到小于等于 r 2 \f

Linux地址空间随机化
ASLR(Address Space Layout Randomization)在2005年被引入到Linux的内核 kernel 2.6.12 中,早在2004年就以补丁的形式引入。内存地址的随机化,意味着同一应用多次执行所使用内存空间完全不同,也意味着简单的缓冲区溢出攻击无法达到目的。 1. 查看ASLR设置 cat /proc/sys/kernel/randomize_v

孟德尔随机化 MR入门基础-简明教程-工具变量-暴露
孟德尔随机化(MR)入门介绍和分章分享(暂时不解读) 大家好,孟德尔随机化大火,但是什么是孟德尔随机化,具体怎么实操呢 这没有其他教程的繁冗,我这篇讲最基础的孟德尔随机化的核心步骤,这个理解之后,再去考虑混杂因素等等术语。 孟德尔随机化(MR),其实是研究两个变量之间的因果关系。也就是研究谁决定了谁,是因果关系,而不是相关关系。 我画了一张图,协助理解: 现在再来读这
R语言实现多变量孟德尔随机化分析(1)
多变量孟德尔随机化分析调整了潜在混杂因素的影响。 1、调整哪些因素?参考以往文献。可以分别调整,也可以一起调整。 2、解决了什么问题?某个暴露相关的SNP,往往与某个或者某几个混杂因素相关。可以控制混杂偏倚。 3、如何解释结果?若该暴露的P值小于0.05,则可以说明该暴露独立于其他暴露对结局产生影响。否则是通过其他因素对结局产生影响。 #多变量孟德尔随机化(MVMR)library(Tw
