本文主要是介绍算法设计与分析复习笔记第七章随机化(概率)算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概率算法概述
随机数
数值随机化算法
舍伍德算法
拉斯维加斯算法
蒙特卡罗算法
概率算法概述
随机化算法的基本思想
是一种使用概率和统计方法在其执行过程中对于下一计算步骤作出随机选择的算法。
随机化算法把“对于所有合理的输入都必须给出正确的输出”这一求解问题的条件放宽,把随机性的选择注入到算法中,在算法执行某些步骤时,可以随机地选择下一步该如何进行,同时允许结果以较小的概率出现错误,并以此为代价,获得算法运行时间的大幅度减少。
随机化算法的基本概念
例如,判断表达式f(x1, x2, …, xn)是否恒等于0。
随机化算法首先生成一个随机n元向量(r1, r2, …, rn),并计算f(r1, r2, …, rn)的值,如果f(r1, r2, …, rn)≠0,则f(x1, x2, …, xn)≠0;如果f(r1, r2, …, rn)=0,则或者f(x1, x2, …, xn)恒等于0,或者是(r1, r2, …, rn)比较特殊,如果这样重复几次,继续得到f(r1, r2, …, rn)=0的结果,那么就可以得出f(x1, x2, …, xn)恒等于0的结论,并且测试的随机向量越多,这个结果出错的可能性就越小。
随机化算法的基本特征
一般情况下,随机化算法具有以下基本特征:
(1)算法的输入包括两部分,一部分是原问题的输入,另一部分是一个供算法进行随机选择的随机数序列;
(2)算法在运行过程中,包括一处或若干处随机选择,根据随机值来决定算法的运行;
(3)算法的结果不能保证一定是正确的,但可以限定其出错概率;
(4)算法在不同的运行中,对于相同的输入实例可以有不同的结果,因此,对于相同的输入实例,概率算法的执行时间可能不同。
随机化算法的随机性
对于同一实例的多次执行, 效果可能完全不同;
时间复杂性的一个随机变量;
解的正确性和准确性也是随机的。
随机化算法的分类
数值随机化算法
主要用于数值问题求解
算法的输出往往是近似解
近似解的精确度与算法执行时间成正比
蒙特卡罗算法
主要用于求解需要准确解的问题
算法可能给出错误解
获得精确解概率与算法执行时间成正比
拉斯维加斯算法
一旦找到一个解, 该解一定是正确的
找到解的概率与算法执行时间成正比
增加对问题反复求解次数, 可使求解无效的概率任意小
舍伍德算法
一定能够求得一个正确解
确定算法的最坏与平均复杂性差别大时, 加入随机性, 即得到Sherwood算法
消除最坏行为与特定实例的联系
随机化算法的性能分析
随机化算法分析的特征:
每次运行实例仅依赖于随机选择, 不依赖于输入的分布
确定算法的平均复杂性分析: 依赖于输入的分布
对于每个输入都要考虑算法的概率统计性能
随机化算法分析的目标:
平均时间复杂性: 时间复杂性随机变量的均值
获得正确解的概率
获得优化解的概率
解的精确度估计
随机数
随机数的产生
在概率算法中随机数的产生是个非常重要的部分,但在计算机上无法产生真正的随机数。
任何一种随机数的产生都和给定的初始条件有关,当初始条件相同时,会给出同样的随机数序列。还有,该随机数序列存在周期,即经过一个周期后,序列会重复出现,称为伪随机数。
线形同余算法
最简单的伪随机数是用线性同余算法产生的。公式如下:
a0=d
an=(b*an-1+c) mod m ,n=1,2,……
其中,d被称为种子。b,d,c,m均大于0。而且这几个数直接关系到随机序列的性能。
线性同余算法实现简单,速度快,具有较好的统计性能,广泛应用于仿真,但不能用于加密。大多数系统中提供的random函数都是采用此方法实现。
随机数类RandomNumber

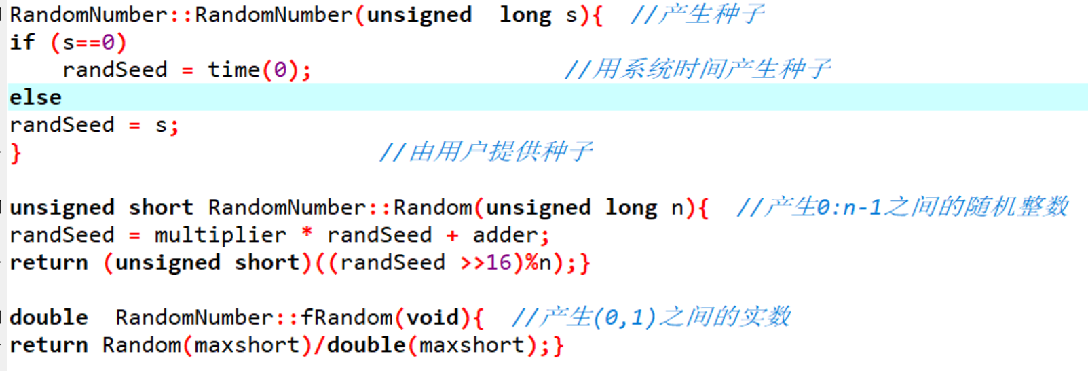
用伪随机数来模拟抛硬币实验
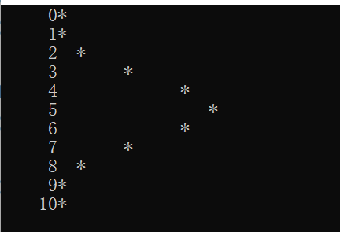
假设抛10次硬币,每次抛硬币得到正面和反面是随机的。抛 10 次硬币构成一个事件。调用 Random(2)返回一个二值结果:返回 0,表示抛硬币得到反面;返回 1,表示得到正面。下面的算法 TossCoins 模拟抛10次硬币这一事件。在主程序中反复用函数 TossCoins 模拟抛10 次硬币这一事件 50000 次。用 head[i](0≤i≤10)记录这 50000次模拟恰好得到 i 次正面的次数。最终输出模拟抛硬币事件得到正面事件的频率图。

数值随机化算法
用随机投点法计算π值
向正方形随机投掷n个点, 设落入其内切圆的点数为k。
由于是均匀分布, 因此落入圆内的概率为

当n足够大时,k 与 n 之比就逼近于这一概率,从而



用随机投点法计算定积分
设f(x)是[0, 1]上的连续函数,且0≤f(x)≤1,计算积分
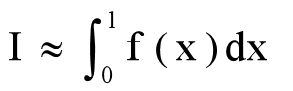
在正方形中随机点落在曲线 y = f(x)下面的概率为

假设向单位正方形内随机投入n个点(xi, yi),若有m个点落入G中,由概率论可知,如果这些点在正方形内均匀分布,则I≈m/n。
当n足够大时,统计出m的值,就可以近似地求出I的值。
计算连续函数的算法

随机抽样算法
在n个元素的集合中随机抽取m(0<m≤n)个无重复的元素。
可以采用下面的方法进行选择:
1、首先将n个元素都标记为“未选择”;
2、重复下列步骤直到抽取了m个不同的元素
⑴产生一个0至n-1间的随机数r;
⑵如果r标记为“未选择”,将它标记为“已选择”,并加入到抽样中。

随机抽样算法评估
算法空间复杂度为O(n) ,时间复杂度也为O(n)。
需要一个长度为n的数组标记每个元素。如果n很大而m很小,这种空间上的浪费是比较大的。要解决这个问题需要设计一个比较好的杂凑函数。
当抽取的元素逐步增加时,要随机抽取下个无重复的元素所需要的时间也越来越长。 当m>=n/2时,选择n-m个元素,抛弃掉它们并将剩余元素作为抽样。
舍伍德算法
舍伍德算法总能求得问题的一个解,且所求得解的结果总是正确的。其主要目的是消除算法所需计算时间对输入实例的依赖。
当一个确定型算法最坏情况下的计算复杂性与其平均情形下的复杂度有较大差别时,可以在这个确定型算法中引入随机性将它改造成一个舍伍德算法,消除或减少问题的好坏实例间的这种差别。
舍伍德算法的精髓不是避免算法的最坏情况行为,而是设法消除这种最坏情形行为与特定实例之间的关联性。
舍伍德算法与快速排序
舍伍德算法的一个典型应用就是在快速排序中。
在快速排序算法中,若用拟中位数作为划分标准,可保证在线性时间内完成。但是确定拟中位数要付出额外开销。若选用第一个元素为划分基准,最坏时的时间复杂性为O(n2)。
为了改进它的性能,我们可以改变基准选取的原则,不是每次都选取待排序列的第一个元素,而是在待排序列中随机选取一个元素作为基准(每次将选择到的元素与第一个元素交换,然后就和确定性算法一样做)。既保证算法的线性时间平均性能,又避免了计算拟中位数的麻烦

线性时间选择算法
在无序序列中选择第K大(或小)的元素是最常见的问题。若K=1或K=n,则显然可以在O(n)的时间内解决;但若K=(n+1)/2,就要难得多了。
借用快速排序来解决。算法的基本思路也是采用划分,以基准元素为标准,将序列划分成大于和小于基准的两部分,第K大元素或者就是基准,否则只可能位于其中的一部分,再对这一部分进行递归处理就可以了。为了避免在最坏情形下时间复杂度达到O(n2),这里对基准的选取需要加入随机性。
选取第k大的元素

定位基准元素

“洗牌”算法
有时候会遇到这样的情况,即所给定的确定型算法无法直接修改成舍伍德算法。此时可以借助随机预处理技术,不改变原有的确定型算法,仅对其输入进行随机洗牌,同样可以收到舍伍德算法的效果。
所谓随机洗牌就是将输入的数组随机排列。下面就是一个随机洗牌算法。

拉斯维加斯算法
舍伍德算法:计算时间复杂性对所有实例而言相对均匀;但与其相对应的确定性算法相比,其平均时间复杂性没有改进。
拉斯维加斯算法:显著地改进算法的有效性,甚至对某些迄今为止找不到有效算法的问题,也能找到满意的算法;
但它所做的随机性决策有可能导致算法找不到需要的解。由于后者的原因,通常用boolean型方法表示拉斯维加斯型算法。
倔强算法
拉斯维加斯算法的典型调用形式为boolean success = LV(x, y);其中x是输入参数,当success的值为true时,y返回问题的解,当success的值为false时,y算法未能找到问题的一个解。此时可对同一实例再次独立地调用相同的算法。
由于拉斯维加斯算法所做的随机决策有可能导致找不到所需要的解,就用下面的倔强算法来求解。

Las Vegas算法求解n后问题
Las Vegas算法的特点是随机性地进行决策。
对n后问题,Las Vegas算法是随机地产生一组王后放置的位置。若成功了,便找到了一个解;若失败了,就整个重来,再随机产生另外一组王后的位置。这样作,直至找到解。
此算法采用了与前面回溯法完全不同的策略,一旦有一列中的皇后没有位置可放,需要全部重新开始。
n 后问题
问题描述:等价于在n×n格的棋盘上放置n个皇后,任何2个皇后不放在同一行或同一列或同一斜线上。
解的表示:
用 n 元组 rec[1:n] 表示皇后i放在第i行的第rec[i]列。
约束条件:
不在同一列:rec[i]互不相同,即rec[i]≠rec[j],当i≠j。
不在同一行:皇后i一定放在第i行,表示法的约定。
不在同一斜线:|rec[i]-rec[j]|≠|i-j|。
QueensLV算法


QueensLV算法的改进
上述算法每次都重新开始,似乎过于悲观。如果将上述随机放置策略与回溯法相结合,可能会获得更好的效果。
可以先在棋盘的前面若干行随机地放置皇后,然后在后继行中用回溯法继续放置,直到找到一个解或宣告失败。随机放置的皇后越多,后继回溯所需的时间就越少,但失败的概率也就越大。
蒙特卡罗算法
蒙特卡罗算法用于求解问题的准确解。
对于一些问题来说,近似解毫无意义。例如判定问题,只要回答“是”或“否”,不存在近似解回答。又如,要求一个整数的因子时所给出的解答必须是准确的,一个整数的近似因子是没有任何意义的。
蒙特卡罗算法能求得一个解,但未必是正确的。其求得正确解的概率依赖于算法所用的时间。所用时间越多,得到正确解的概率就越高,但它的缺点也在于此。在一般情况下,无法有效地判定所得到的解是否肯定正确。
蒙特卡罗算法的基本思想
设p是一个实数,且1/2<p<1。若一个蒙特卡罗算法对于问题的任意实例得到正确解的概率不小于p,则称该蒙特卡罗算法是p正确的,且称p-1/2是该算法的优势。
若对于同一实例,蒙特卡罗算法不会给出两个不同的正确解答,则称该蒙特卡罗算法是一致的。
对于一个一致的p正确蒙特卡罗算法,要提高获得正确解的概率,只要执行该算法若干次,并选择出现频率次数最高的解即可。
关于正确解的概率
在一般情况下,设δ和ε是两个正实数,且δ+ε<0.5。设MC(x)是一个一致的(1/2+ε)正确的蒙特卡罗算法。不论它的优势ε有多小,都可以通过反复调用来放大算法的优势,使得最终得到的算法具有可以接受的错误概率。已经证明,重复n次调用算法MC(x)得到正确解的概率至少为1-δ。在实际应用中,大多数蒙特卡罗算法经重复调用后正确率提高很快。
偏真算法
设MC(x)是解某个判定问题的蒙特卡罗算法,当它返回true时解总是正确的,仅当它返回false时有可能产生错误的解。称这类蒙特卡罗算法为偏真算法。
对于一个偏真算法,只要有一次调用返回true,就可以断定相应的解为true。假定某个偏真算法正确概率为0.55,我们只要重复调用4次,就可以将正确率提高到0.95,重复调用6次,就可以提高到0.99。而且对于偏真算法而言,原先的要求p>0.5,可以放松到p>0。
主元素问题
设T[0..n-1]是一个有n个元素的数组。当|{i|T[i]=x}|>n/2时,称元素x是数组T的主元素。我们用下面的方法来判断T中是否含有主元素:

对majority算法的分析
若算法返回结果为true,即随机选择的元素x是数组T的主元素,则显然数组T含有主元素。反之, 若返回结果为false, 则数组T未必没有主元素。由于若数组T有主元素,则它的非主元素个数小于n/2, 故上述情况发生的概率小于1/2。由此可见, majority算法是一个偏真的1/2正确算法。
或换句话说,若数组T含有主元素,则算法以大于1/2的概率返回true; 若数组T没有主元素,则算法肯定返回false。
重复2次调用的majority2算法
在实际使用时,50%的错误概率是不可容忍的。重复调用技术可将错误降低到任何可接受值的范围。现在讨论重复调用2次的算法majority2。

对majority2算法的分析
若数组T不含主元素,则每次调用majority(T, n)返回false, 从而majority2肯定也是返回false。若数组T含有主元素,则算法majority(T, n)返回true的概率是p>1/2,而当majority(T, n)返回true时, majority2也返回true。
另一方面,majority2第一次调用majority(T, n)返回false的概率为1-p, 第二次调用majority(T, n)仍以概率p返回true。因此当数组T含有主元素时,majority2返回true的概率是p+(1-p)p=1-(1-p)2>3/4。即算法majority2是一个偏真3/4正确的MC蒙特卡罗算法。
错误概率小于ε的偏真算法
由于重复调用majority所得到的结果是相互独立的,若T确实含有主元素,则k次重复调用majority仍然得到false的概率小于2-k。另一方面,只要有一次调用返回值为true,即可断定T中含有主元素。
对于任何给定的ε>0,下面算法majorityMC重复调用log(1/ε)次算法majority。它是一个偏真的蒙特卡罗算法,且错误概率小于ε。

判定素数的概率算法
判定自然数是否是素数,不仅有重要理论意义,而且在密码学中具有重要实用价值。
最简单的素数判定方法是依次测定从2到n½ 中是否存在n的因子,该算法的复杂度为O(n½ )。
筛法:将小于n的合数预先筛掉,而不用判断其是否为n的因子。它虽然没有降低算法的复杂度,但实际运行速度比前者要快得多。
概率算法,保证一定概率的前提下简单判断。
Fermat素数测试法
Fermat定理: 若p是素数,则对任意整数a,gcd(a, p) = 1,则有ap–1≡1 (mod p)。
对于给定的整数n,通过计算d=2n-1 mod n来判定整数n的素性。当d不等于1时,n肯定不是素数;当d=1时,n则很可能是素数,称为伪素数。
为了提高测试的准确性,可在(1, n-1)范围内选取整数作为a, 用an-1
![]()
1(mod n)来判定整数n的素性。
Fermat素数测试法的正确性
Fermat定理只是素数判定的一个必要条件。满足Fermat定理条件的整数n未必全是素数。有些合数也满足,这些数被成为Carmichael数,前3个Carmichael数是561、1105和1729。
Carmichael数是非常少的。在1~100000000范围内,只有255个Carmichael数。
算法的时间复杂度是O(logn)。

合数的见证者
设n为测试的自然数,不妨设n是大于2的奇数,则有n – 1 = 2im,其中i是非负整数,m是正奇数。取一自然数b,1 < b < n,记W(b)为条件:
① bn–1 ≠ 1 (mod n) 或
②
![]()
i,使得m = (n–1)/2i 且 1 < gcd(bm–1, n) < b。
若①或②中有一个为真,就认为W(b)满足,则n必定是合数,我们称b是n为合数的见证者。若n有见证者,则n必定为合数。
合数的见证者多于一半
Miller已经证明,存在常数c,使得当n为合数时,在[1, c(log n)2]范围内有见证者。
Rabin证明了:如果n是合数,则|{b|1<b<n,W(b)满足}|≥(n–1)/2 即,在小于n的自然数中有多半是n的见证者。
任取一个自然数b < n,若b不是n的见证者,则n是合数的概率小于1/2。若随机取m个数都不是见证者,则n是合数的概率小于1/2m。
Miller-Rabin素数判定概率算法


这篇关于算法设计与分析复习笔记第七章随机化(概率)算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







