本文主要是介绍【网安AIGC专题10.11】2 ILF利用人类编写的 自然语言反馈 来训练代码生成模型:自动化反馈生成+多步反馈合并+处理多错误反馈+CODEGEN -M ONO 6.1 B model,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Improving Code Generation by Training with Natural Language Feedback
- 写在最前面
- 主要工作
- 启发
- 背景介绍
- 应用
- 现有工作的不足
- Motivation动机
- 方法
- ILF
- Experiments & Results
- 数据集
- 评价指标
- 3.1.验证 π Reffine \pi_{\text{Reffine}} πReffine 与NLF结合的有效性(可以使用反馈来修复不正确的代码)
- 3.2 验证ILF比Fine-Tuningon黄金数据或人工编写的程序的通过率更高
- 3.3 评估使用多少 GPT 生成的 Feedback 能赶上人工 NLF
- 3.4 Human Feedback Is More Informative Than InstructGPT Feedback
- 3.5 π Refine \pi_{\text{Refine}} πRefine 努力合并解决许多 bug 的反馈
- 结论
- Conclusion & Discussions
- Conclusion
- 展望
- 不足之处
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
一位同学分享了arXiv 2023.3.28
纽约大学团队Authors: Angelica Chen, Jérémy Scheurer, Tomasz Korbak, Jon Ander Campos, Jun Shern Chan, Samuel R. Bowman, Kyunghyun Cho, Ethan Perez的
Improving Code Generation by Training with Natural Language Feedback《通过使用自然语言反馈进行训练来改进代码生成》
论文:https://arxiv.org/pdf/2303.16749.pdf
代码:https://github.com/nyu-mll/ILF-for-code-generation
主要工作
- 论文介绍了一种名为“Imitation learning from Language Feedback (ILF)”的解决方案,旨在解决
代码生成任务中的准确性和样本效率问题。 - ILF方法的核心思想是:
利用人类编写的自然语言反馈来训练代码生成模型,提供更准确的训练信息,从而改进模型性能。 - 实验证明,ILF方法在MBPP基准测试中能够将CODEGEN-MONO 6.1B模型的pass@1 rate相对值提高38%,绝对值提高了10%。这表明ILF方法在代码生成任务中具有显著性能提升。
- 这项研究为改进代码生成提供了一种有效且高效的方法,通过引入人类反馈数据,从而提高了生成代码的质量。
- 尽管ILF方法在性能方面取得了显著的成果,但它依赖于人类编写的自然语言反馈数据。因此,方法的适用范围和局限性需要进一步探索和理解。
- 未来可以研究结合该方法与其他代码生成技术。
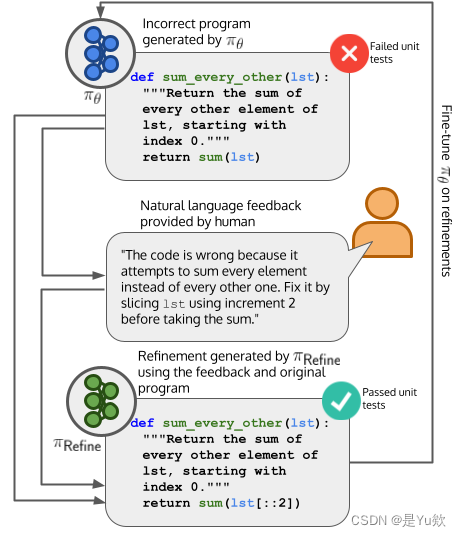
启发
这篇论文提供了有关使用人工反馈来提高代码生成模型质量的重要见解。在未来的研究中考虑:
-
自动化反馈生成: 论文中提到未来可能实现
自动化或半自动化的自然语言反馈生成。这是一个非常有前景的方向,可以减少人工反馈收集的时间和成本,提高模型的实际应用性。 -
多步反馈合并: 论文中提到
将反馈分解为多个步骤,并逐步合并这些反馈的方法。这是一个有望提高反馈质量的方法,未来的工作可以进一步探索这一领域,以优化反馈的处理和集成。 -
处理多错误反馈: 论文中指出,当反馈中包含多个错误时,某些方法的效果较差。未来的研究可以探索如何更好地处理多错误反馈,例如使用
分级反馈或多轮反馈的方法。 -
编程语言相关性研究: 论文中提到未研究ILF算法在不同编程语言中的性能提升。未来研究可以探究ILF算法在不同编程语言任务中的适用性,以便更全面地了解其效果。
背景介绍
近年来,预训练的大语言模型(如GPT)在自然语言处理任务中取得了显著的成果。
通过预训练大语言模型,我们可以利用其强大的语言建模能力来生成代码,提高代码生成的质量和效率
应用
自动化生成复杂代码片段
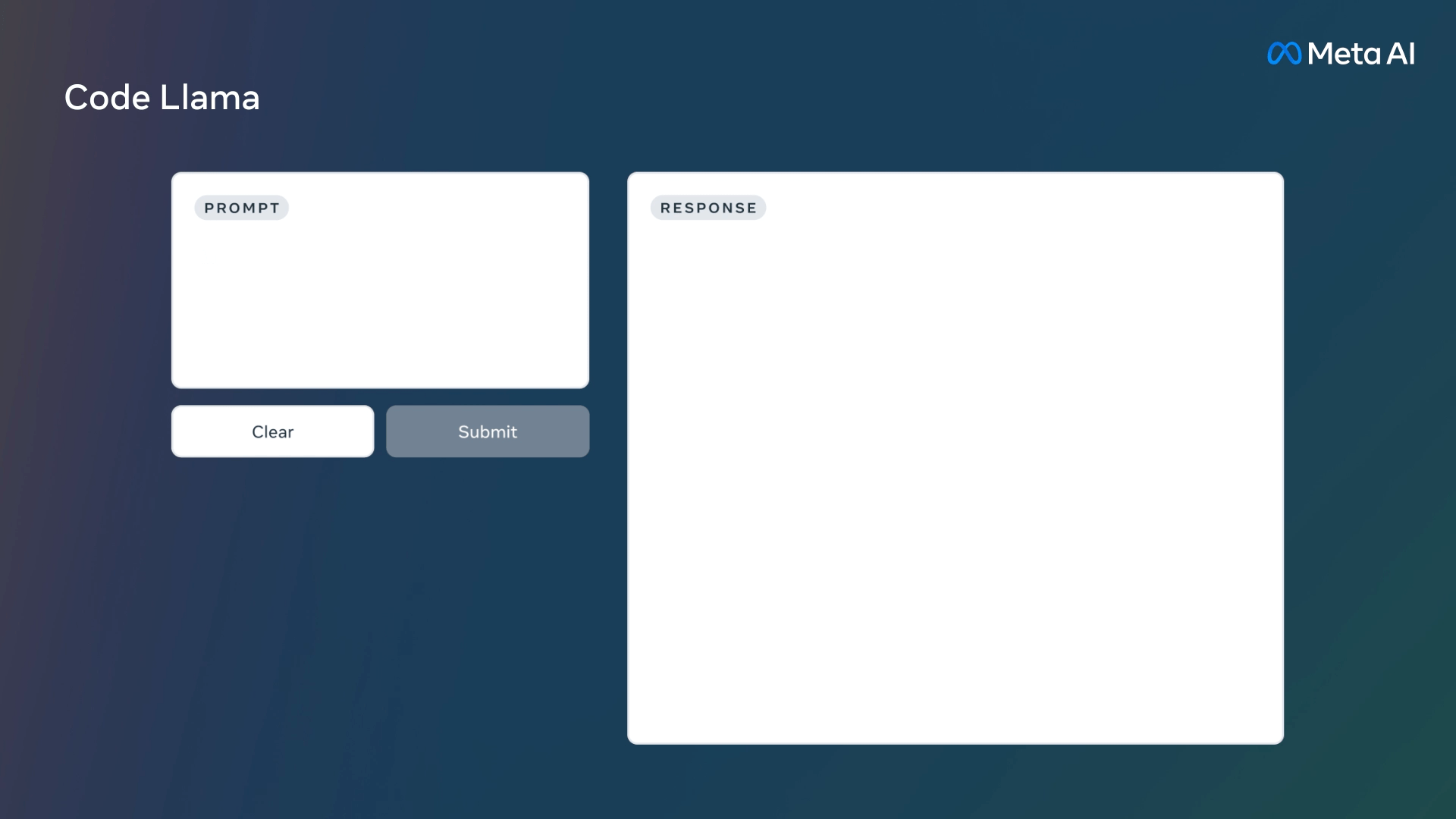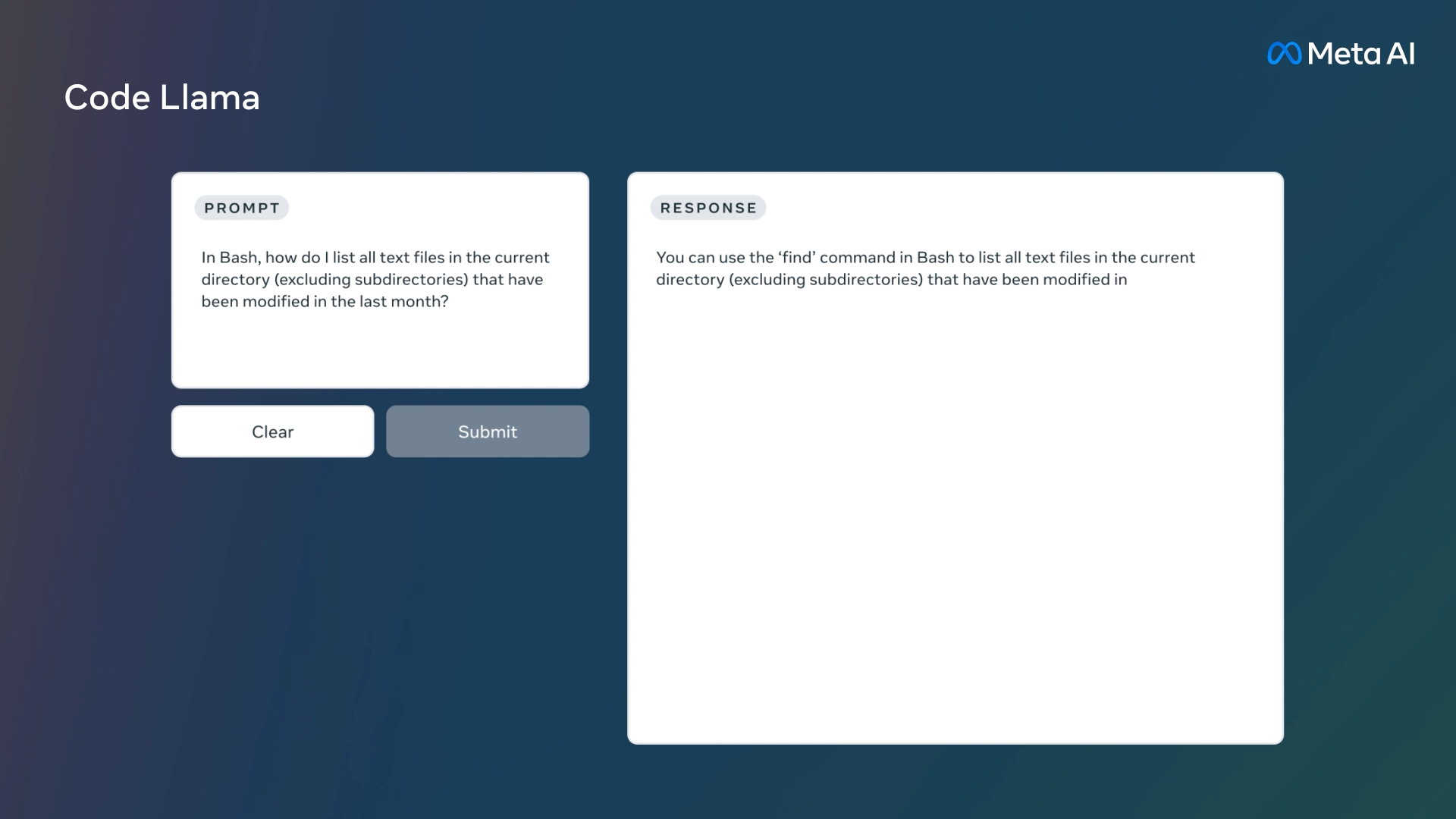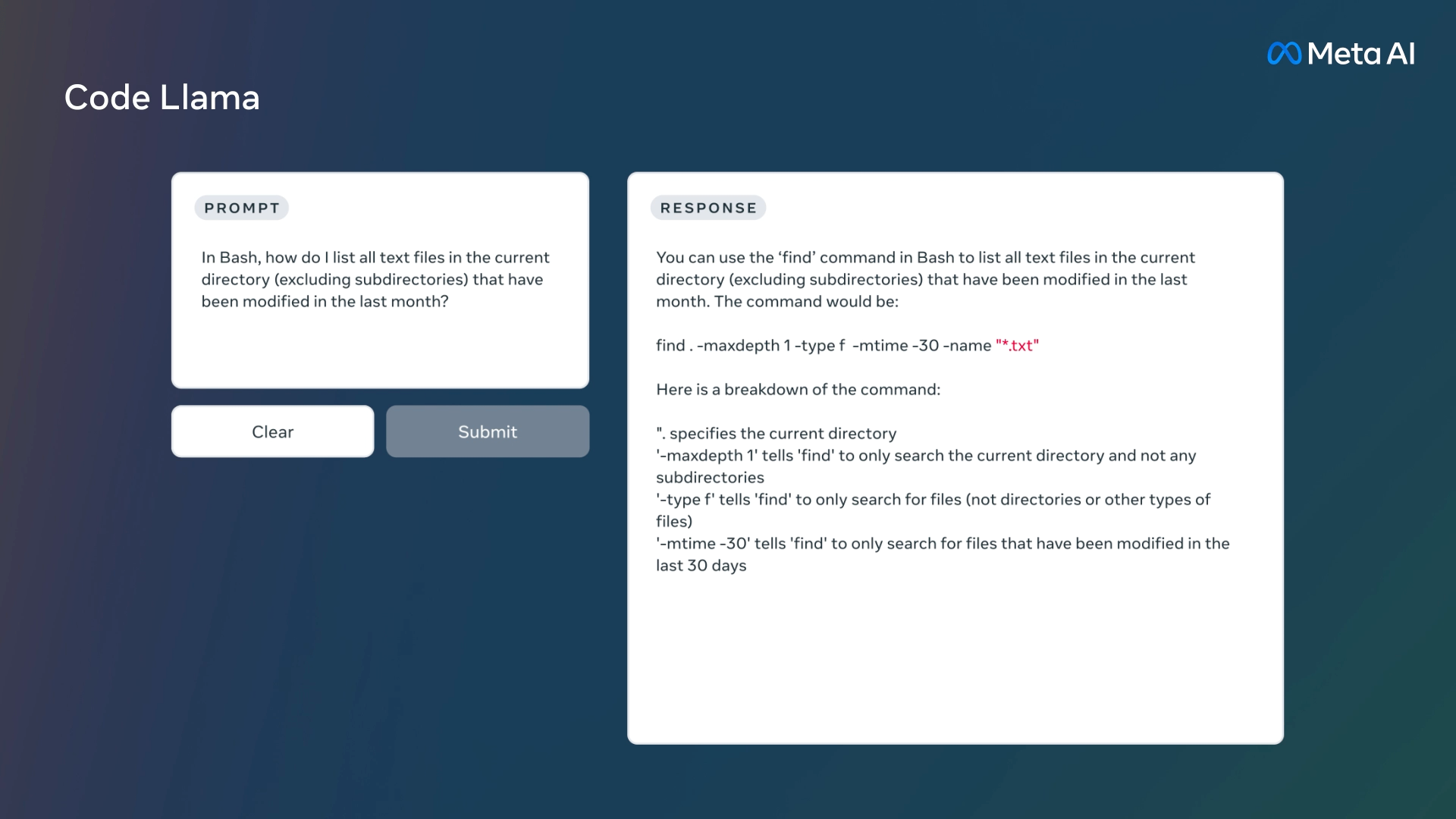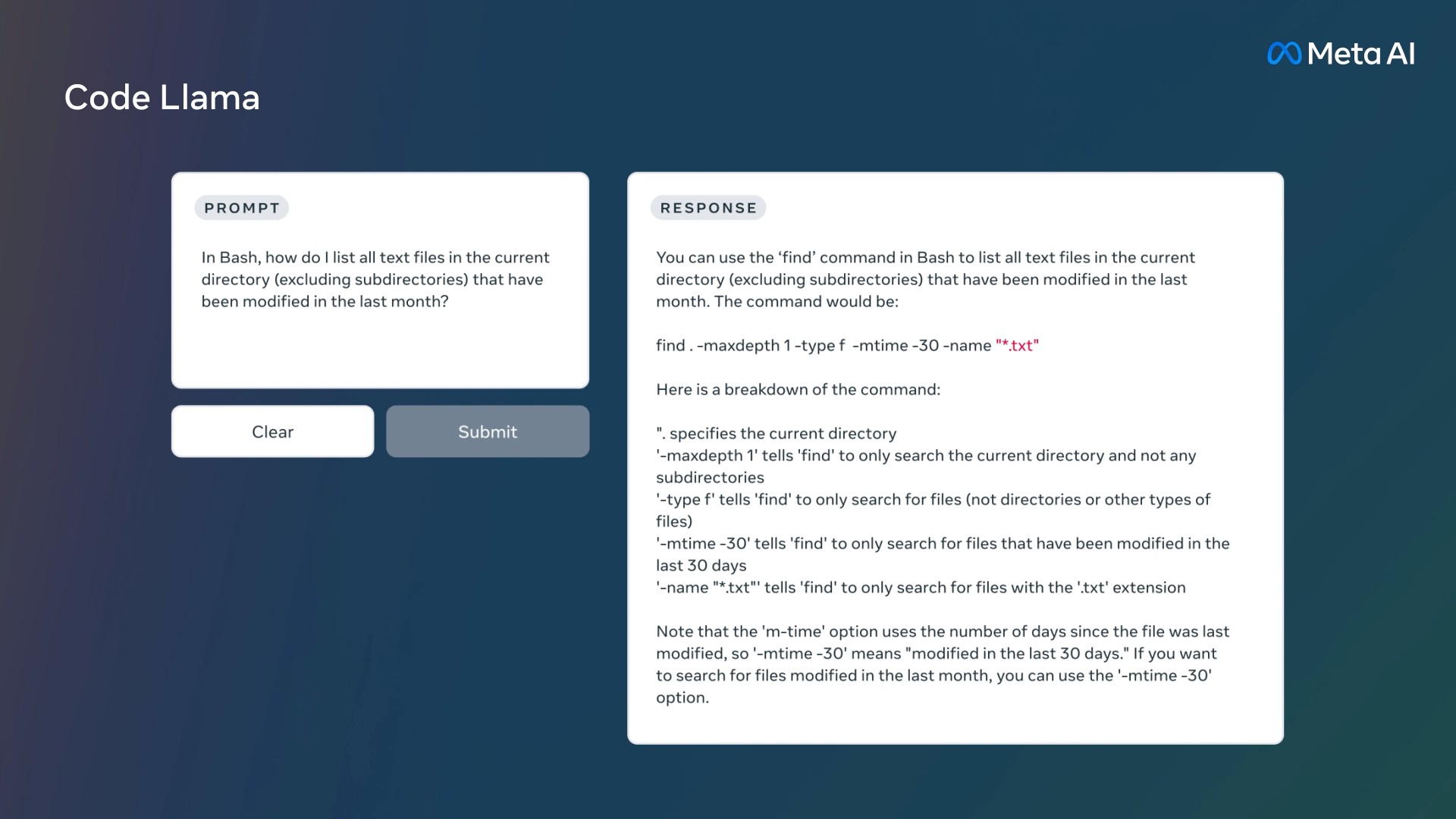
改进开发者IDE Copilot
AlphaCode程序竞赛

现有工作的不足
都是离线算法,没有交互式的反复实验;没有惩罚模型错误输出的交互式指导
有的工作仅在推理阶段引入了Feedback,在实际应用时难以实现
大语言预训练模型仍然很难生成非常准确的代码
| LLMs for Program Synthesis | ||
|---|---|---|
| 论文 | 会议 | 训练数据 |
| THE PILE (Gao et al., 2020) | ArXiv | 大型语言文本 |
| GPT-NeoX-20B(Black et al., 2022) | ACL | 大型语言文本+少量代码 |
| Codegen(Nijkamp et al.,2022) | ICLR | 大型语言文本+少量代码 |
| AlphaCode(Li et al., 2022;) | Science | 源码文件 |
| Bloom(Workshop et al., 2022), | ArXiv | 源码和文档 |
| Learning from human feedback | ||
|---|---|---|
| 论文 | 会议 | Feedback类型 |
| (Ouyang et al., 2022), | NIPS | 人的反馈 |
| Codegen(Nijkamp et al.,2022) | ICLR | 自然语言反馈 |
| (Scheurer et al., 2023) | ArXiv | 自然语言反馈 |
Motivation动机
代码生成可以提高开发人员的效率,而LLM仍然难以始终如一地生成正确的代码。LLM自然能够结合书面反馈,这已被证明在测试时提供反馈时可以显著提高代码生成模型的通过率。
LLM的失败在很大程度上可以归因于现代LLM预训练设置。通过对模型自身输出的明确的人工书面反馈来监督LLM,可以更有效地训练模型以生成功能正确的代码。
方法
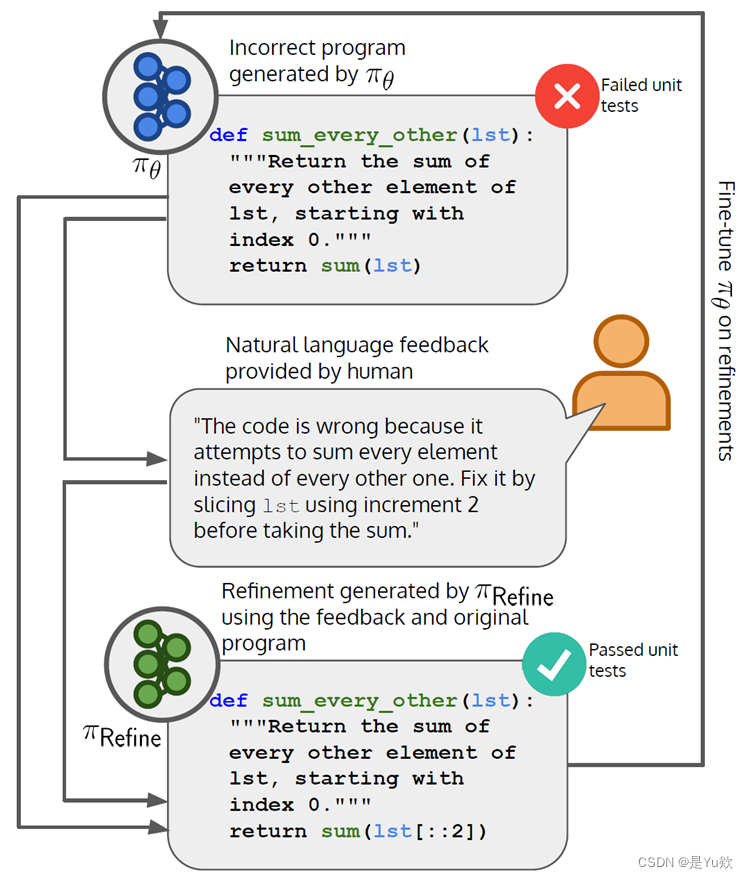
目标是从任务分布 P ( t ) P(t) P(t) 中采样出一组高质量的程序 x 1 ∼ π θ ( ⋅ ∣ t ) x_1 \sim \pi_{\theta}(\cdot|t) x1∼πθ(⋅∣t);
通过拟合LLM π θ \pi_{\theta} πθ 来近似真实的分布 π t ∗ ( x 1 ) \pi_t^*(x_1) πt∗(x1),利用奖励函数 ( R ) (R) (R) 来衡量程序 x 1 x_1 x1 通过单元测试的概率
π θ \pi_{\theta} πθ 预先训练的语言模型参数化依据 θ \theta θ; t t t 为从任务分布 P ( t ) P(t) P(t) 上采样得到的,代码描述
拟合 π θ \pi_{\theta} πθ 到 π t ∗ \pi_t^* πt∗ 的近似,可以被视为最小化从 π t ∗ \pi_t^* πt∗ 到 π θ \pi_{\theta} πθ 在任务分布 P ( t ) P(t) P(t) 上的 KL 散度的期望。
目标是从任务分布 P ( t ) P(t) P(t) 中采样出一组高质量的程序 x 1 ∼ π θ ( ⋅ ∣ t ) x_1 \sim \pi_{\theta}(\cdot|t) x1∼πθ(⋅∣t);
通过拟合LLM π θ \pi_{\theta} πθ 来近似真实的分布 π t ∗ ( x 1 ) \pi_t^*(x_1) πt∗(x1)
利用奖励函数 ( R ) (R) (R) 来衡量程序 x 1 x_1 x1 通过单元测试的概率
对于任务描述 t t t,程序是否通过单元测试

拟合 π θ \pi_{\theta} πθ 到 π t ∗ \pi_t^* πt∗ 的近似,可以被视为最小化从 π t ∗ \pi_t^* πt∗ 到 π θ \pi_{\theta} πθ 在任务分布 P ( t ) P(t) P(t) 上的 KL 散度的期望。
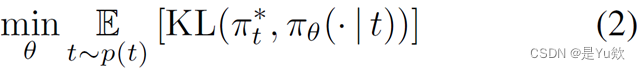
转化为有监督学习中的二分类任务
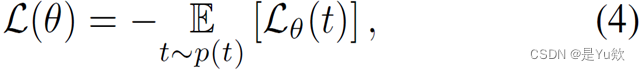
在 x 1 x_1 x1的潜在空间太大,而且不能直接在 π t ∗ \pi_t^* πt∗中采样!!
在 q t ( x 1 ) q_t(x_1) qt(x1)上采用重要性采样。
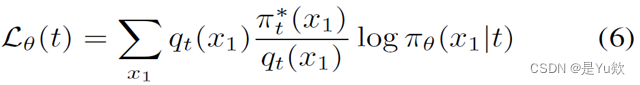
引入预训练模型𝜋_Refine和人工标注的自然语言反馈𝒇来近似𝒒_𝒕 (𝒙_𝟏)
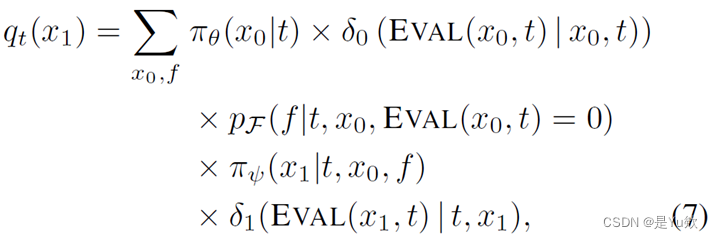
ILF

Experiments & Results
数据集
Mostly Basic Python Problems (MBPP) dataset
M B P P R e f i n e MBPP_{Refine} MBPPRefine:这些是任务的ID范围在111-310之间,CODEGEN-MONO 6.1B没有生成任何正确的完成。这个分割用于训练 π R e f i n e \pi_{Refine} πRefine。
M B P P T r a i n MBPP_{Train} MBPPTrain:这些是任务的ID范围在311-974之间,CODEGEN-MONO 6.1B没有生成任何正确的完成。这个分割首先用于评估由 π R e f i n e \pi_{Refine} πRefine生成的细化的正确性。然后,这个分割中的正确细化用于训练 π θ \pi_{\theta} πθ 以获得 π θ \pi_{\theta} πθ (这是算法1中的第5步)。
M B P P T e s t MBPP_{Test} MBPPTest:这些任务的ID范围在11-110之间,我们使用它们来评估 π θ ∗ \pi_{\theta}* πθ∗ 的最终性能。与前两个分割不同,我们在这个分割中使用了所有的任务,而不仅仅是CODEGEN-MONO 6.1B最初未生成正确程序的任务。这使我们能够更好地比较 π θ \pi_{\theta} πθ 的基准性能与 π θ ∗ \pi_{\theta}* πθ∗ 的性能。
评价指标
在本文中使用Kulal等人(2019年)引入的pass@k指标通常用于评估代码生成模型的性能。
这个公式计算了 k 个模型生成的样本中通过所有单元测试的比例,然后通过求和取平均值来得到 pass@k 指标的估计值。
p a s s @ k = 1 k ∑ i = 1 k Indicator ( T e s t ( x i ) ) pass@k = \frac{1}{k} \sum_{i=1}^{k} \text{Indicator}(Test(x_i)) pass@k=k1i=1∑kIndicator(Test(xi))
在这个公式中:
- pass@k 是 “pass@k” 指标的值。
- k 是模型生成的样本数量。
- 𝑥ᵢ 表示生成的代码样本中的第 i 个样本。
- Indicator 是指示函数,如果括号中的条件为真则返回1,否则返回0。
- Test(𝑥ᵢ) 是用于测试代码 𝑥ᵢ 是否通过所有单元测试的函数。
本文使用了Chen等人(2021年)提供的这一数量的经验估计,它是一个无偏估计器,给出如下公式:
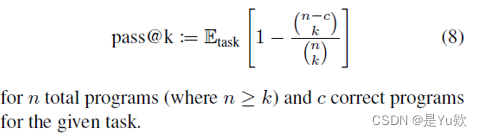
3.1.验证 π Reffine \pi_{\text{Reffine}} πReffine 与NLF结合的有效性(可以使用反馈来修复不正确的代码)
CODEGEN-MONO 6.1B Incorporates Feedback
只有最初无法通过测试的code才需要feedback

结论
Baseline模型可以使用feedback来修复不正确的代码,而Fine-tuning更有效。
-
我们首先验证我们的基线模型可以使用feedback来修复不正确的代码,这是ILF工作的先决条件。
-
我们评估了 CODEGEN-MONO 6.1B 在给定成对(incorrect code, natural language feedback)的情况下,以 few-shot 的方式和 fine-tuning 后生成 Refinements 的能力。
-
只有最初无法产生正确响应的任务才需要feedback,因此我们首先在所有 MBPP 上评估 CODEGEN-MONO 6.1B few-shot,每个任务生成 30 个程序,温度为 0.8。 表1 显示了由此产生的通过率。 共有 321 项任务,零样本 CODEGEN-MONO 6.1B 没有产生正确样本的任务有 321 个(表1: ( ( 100 % − 67 % ) × 974 任务 ) ≈ 321 ((100\%-67\%) \times 974 \text{ 任务}) \approx 321 ((100%−67%)×974 任务)≈321 个)。 然后,我们用反馈 feedback 和细化 refinements 为每个任务注释一个不正确的程序,如第3节所述。
表1. 在整个 MBPP 数据集上的初始零射击 CODEGEN-MONO 6.1B 性能。“1+正确”是指 CODEGEN-MONO 6.1B 生成至少一个通过所有单元测试的程序的任务百分比。

少样本反馈合并,我们使用人工反馈注释来创建少样本反馈提示,格式如图2所示。我们评估了 CODEGEN-MONO 6.1B 产生包含反馈并通过单元测试的改进的能力。然而,产生通过单元测试的精化并不能保证反馈已经被纳入;一个编程任务可以有多种解决方案,包括那些功能上完全不同,并且不使用反馈来改进原始代码的解决方案。或者,模型可能已经能够在没有反馈的情况下修复程序。因此,我们还评估了在打乱数据集中反馈样本后的通过率,以评估当呈现不相关反馈时,模型修复代码的能力是否会下降。
图2. 基于人工编写的反馈修复错误代码的零样本 LLM 提示示例。

表2:
- baseline模型把feedback纳入相关任务的能力较弱 (13.8%);
- 模型确实在使用feedback,使用相关feedback效果明显。
表2. 在提示符中给出相关或不相关的文本反馈,评估由 CODEGEN-MONO 6.1B (ILF之前) 生成的1次优化。只有在 CODEGEN-MONO 6.1B 之前没有输出任何正确程序的任务上才提供反馈。
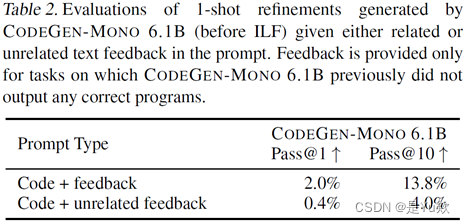
表3 显示了 π Refine \pi_{\text{Refine}} πRefine 在评估数据集上的通过率,该数据集是在温度0.8的情况下,每个任务采样30个 refinements 产生的。与单次优化相比,微调显著提高了 CODEGEN-MONO 6.1B 整合反馈的能力,将通过率提高了三倍以上( 2 → 19 % pass@1 2\rightarrow 19\% \text{ pass@1} 2→19% pass@1, 13.8 → 47 % pass@10 13.8\rightarrow 47\% \text{ pass@10} 13.8→47% pass@10,来自表2和表3)。此外,61%的任务至少有一次正确的优化。考虑到我们只选择了未经微调的 CODEGEN MONO 6.1B 模型最初没有输出任何正确程序的任务(表3中最右边的列),这一点尤为重要。对于61%的验证任务, π Refine \pi_{\text{Refine}} πRefine 生成了正确的细化,我们为每个任务随机选择了一个这样的正确程序来形成我们最终模型 π θ ∗ \pi_{\theta}^* πθ∗ 的训练数据集,产生了78个示例的最终训练数据集。
表3. π Refine \pi_{\text{Refine}} πRefine-generated 改进与零射击 CODEGEN-MONO 6.1B 程序在 MBPPTrain 中的任务的通过率。

3.2 验证ILF比Fine-Tuningon黄金数据或人工编写的程序的通过率更高
ILF Yields Pass Rates Higher Than Fine-Tuning on Gold Data or Human-Written Programs Alone
结论
π Refine \pi_{\text{Refine}} πRefine 使用 NLF 预训练后更有效。人工编写的 NLF 最有效。使用 MBPP Gold 预训练和 Zero-shot 推理无显著差异,可能 MBPP Gold 脱离了本文使用的 baseline 的数据分布。
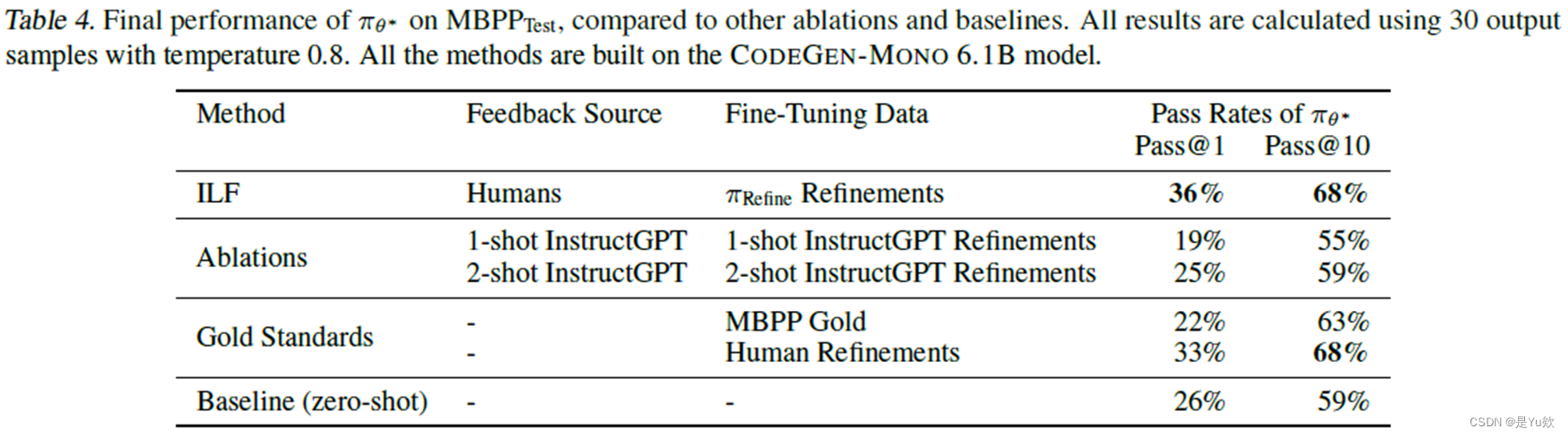
我们的 ILF 算法与基线和消融的结果如表4所示。尽管我们使用的反馈和改进样本很少,但 ILF 产生最高的 pass@1 和 pass@10 率。特别是 pass@1 率显示了在改进方面比零样本基线的显著增加,代表了 10% 的绝对增加(38% 的相对增加)。Pass@1 改进尤其有助于协助软件工程,在软件工程中,建议一个正确的完成比建议 10 个可能的完成更有帮助,供用户从中选择。
与黄金标准相比,ILF 优于 MBPP 黄金计划的微调和 pass@1 指标的人工精炼,pass@1 利率的绝对增长率分别为 14%(相对 64%)和 3%(相对 9%)。然而,人工编写的改进训练产生了与 ILF 相当的 pass@10 率,这并不奇怪,因为 π Refine \pi_{\text{Refine}} πRefine 是在人工编写的改进上训练的。
当人工编写的反馈和 π Refine \pi_{\text{Refine}} πRefine 生成的精炼被去除(表4的 “Ablations” 部分)时,ILF 在 1 次和 2 次 instructgpt 生成的精炼上的训练效果也分别高出 17% 和 11% 的绝对效果(89% 和 44% 的相对效果)。
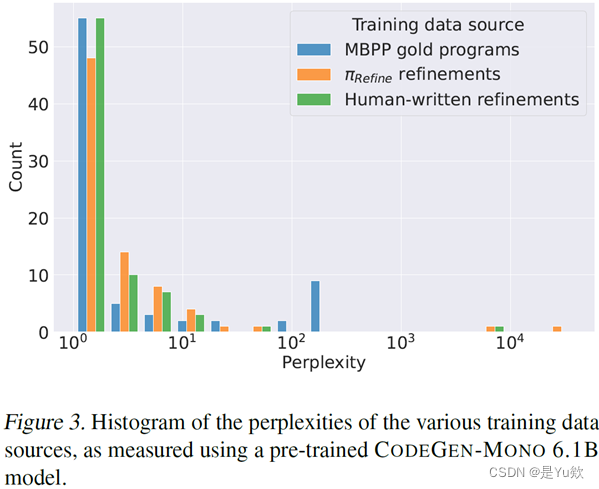
然而,我们也注意到一个令人惊讶的事实,即仅仅在 MBPP 金牌项目的一小部分样本上进行训练,并没有在零射击推理的准确性上产生显著差异。我们推测来自 MBPP 数据集的黄金程序可能在某种程度上偏离了 CODEGEN-MONO 6.1B 的分布。为了验证这一假设,我们使用预训练的 CODEGEN-MONO 6.1B 模型计算了 MBPP 黄金程序、 π Refine-generated \pi_{\text{Refine-generated}} πRefine-generated 细化和人工编写细化的困惑度。结果如图3所示。虽然这三个数据源的分布看起来很相似,但 MBPP 数据集包含的高困惑度程序(即困惑度 ≥ 1 0 − 2 \geq 10^{-2} ≥10−2 的程序)比 π Refine \pi_{\text{Refine}} πRefine 生成的细化或人工编写的细化都要多。因此,CODEGEN-MONO 6.1B 可能更容易从后两个数据集学习,因为它们更接近 CODEGEN-MONO 6.1B 的原始分布,同时仍然是功能正确的。
此外,ILF 对于无法获得大量黄金代码的设置特别有用。在这种情况下,ILF 可以被认为是一种不仅产
图3. 使用预训练的 CODEGEN-MONO 6.1B 模型测量的各种训练数据源的困惑度直方图。
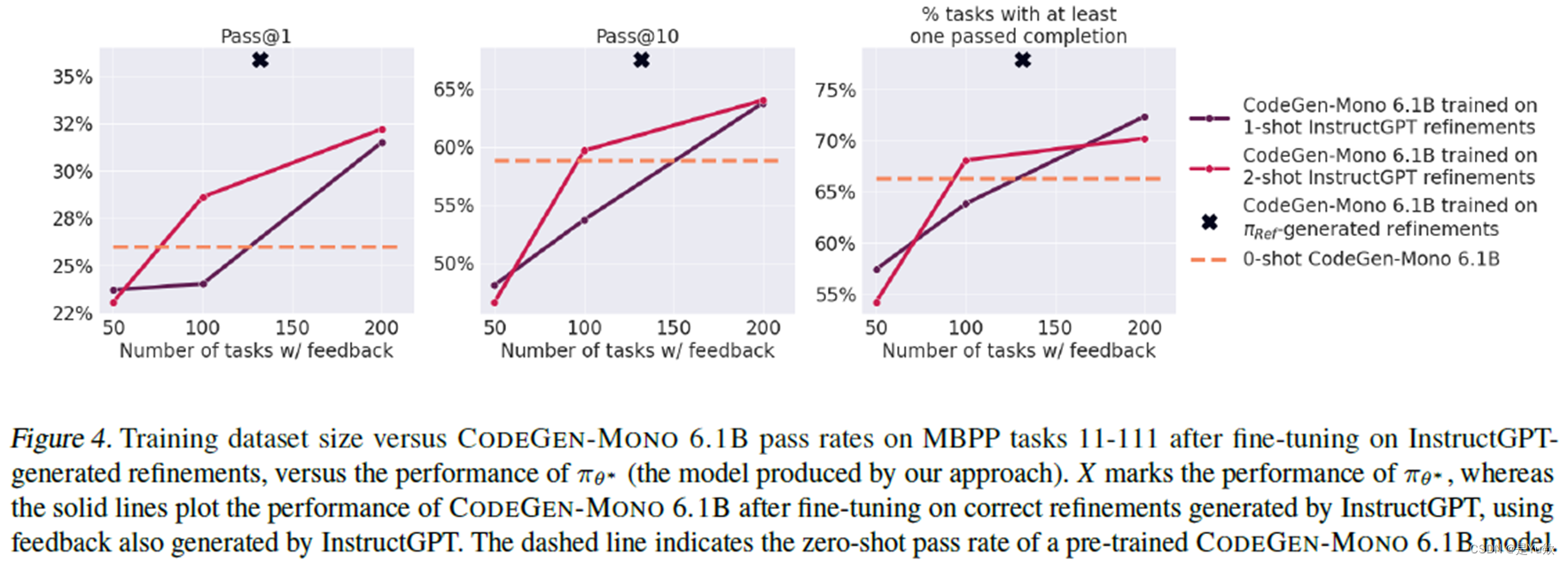
3.3 评估使用多少 GPT 生成的 Feedback 能赶上人工 NLF
Scaling Up Model Feedback Does Not Offer the Same Benefits As Human Feedback
结论
增加 InstructGPT 生成的 Feedback 数量可以适度提高代码通过率,但 π Refine \pi_{\text{Refine}} πRefine 的结果仍然更好,尽管只使用了 122 组数据 fine-tuning。
3.4 Human Feedback Is More Informative Than InstructGPT Feedback
结论
InstructGPT 生成的 Feedback 要么是错的,是无关的,要么没有给人工书写 NLF 平均解决了更多错误,不给无关的。
为了更好地理解为什么人类反馈比 InstructGPT 反馈在通过率方面产生了更大的改进,我们为每个来源(即人类或 InstructGPT)随机选择了 50 个反馈样本,并注释了每个反馈样本所解决的错误的数量和类型。结果如表5和表6所示。
我们观察到 InstructGPT 经常不提供反馈(例如“代码是正确的”或“干得好!”),提供无关或不正确的反馈,或重申任务描述,而不是解决关于代码应该修复的地方。尽管如此,InstructGPT 的改进通常是正确的,即使反馈本身不是。人工撰写的反馈平均解决了更多的 bug,而且从来没有给出过无关的反馈。我们在附录A.3中提供了关于人类反馈和 InstructGPT 反馈之间差异的进一步示例。
表5. 解决每种类型 bug 的反馈比例,来自人类和 InstructGPT 的反馈。每个反馈样本都可以被标记为多个类别,因此每一列中的数量加起来不一定是 100%。
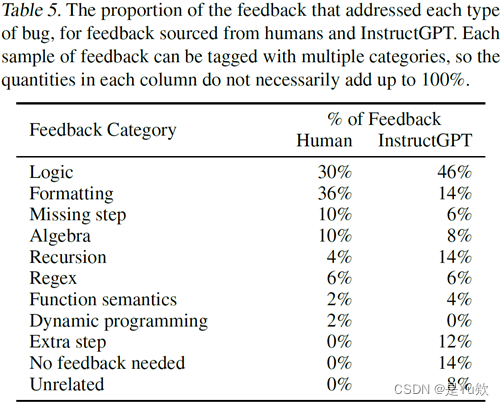
表6. 人类与 InstructGPT 生成的反馈的描述性统计。* 表示指标是在我们手动检查的 50 个随机样本上计算的,而其他指标是从完整数据集计算的。

3.5 π Refine \pi_{\text{Refine}} πRefine 努力合并解决许多 bug 的反馈
最后,我们探讨了反馈中解决的 bug 数量是否影响了 π Refine \pi_{\text{Refine}} πRefine 的修复原始代码样本的能力。结果如图5所示。解决的 bug 数量越多, π Refine \pi_{\text{Refine}} πRefine 的细化的平均通过率越低。
这表明,未来工作的一个有希望的方向可能包括:自动将反馈分解为多个步骤,并让 π Refine \pi_{\text{Refine}} πRefine 一次合并一个步骤的反馈。
事实上,Nijkamp 等人 (2022) 表明,当指令跨多个回合给出时,CODEGEN 模型通常更有效地遵循指令,而最近的思维链工作 (Wei 等人,2022) 说明了类似的提示技术。
结论
随着 NLF 中解决的 bug 增加, π Refine \pi_{\text{Refine}} πRefine 生成的 Refinements 的通过率逐渐降低。 Feedback 中处理的错误数量削弱了 π Refine \pi_{\text{Refine}} πRefine 修复原始代码样本的能力。
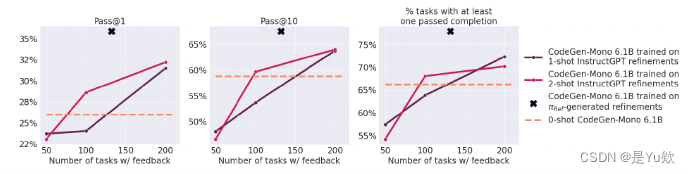
结果如图4所示。 尽管增加 InstructGPT 生成的 feedback 数量可以适度提高通过率,这些 refinement 的通过率没有超过 π θ ∗ \pi_{\theta^*} πθ∗。 即使 π θ ∗ \pi_{\theta^*} πθ∗ 在其整个训练过程中仅使用总共 122 条 feedback(44 条用于训练 π Refine \pi_{\text{Refine}} πRefine,78 条用于生成要训练的 refinement 在 π θ ∗ \pi_{\theta^*} πθ∗ 上)。 然而,随着预先训练的大型语言模型在质量上不断显著提高,我们预计人工和模型书面反馈之间的差距将越来越小。
我们从 CODEGEN-MONO 6.1B 最初没有输出正确答案的 MBPP 任务集中随机选择 k 个任务,并提示 InstructGPT 生成 feedback 和 refinement。 然后,我们评估 refinement 的正确性,并在正确的 refinement 上训练 CODEGEN-MONO 6.1B。
-
为了更好地理解为什么人类 feedback 比 InstructGPT feedback 在通过率方面有更大的改进,我们为每个来源(即人类或 InstructGPT)随机选择了 50 个 feedback 样本,并注释了每个反馈样本所处理的错误的数量和类型。 结果如表5和表6所示。 我们观察到,InstructGPT 通常没有给出任何 feedback(例如“代码是正确的”或“干得好!”),提供了无关或不正确的 feedback,或者重述了任务描述,而不是解决应该修复的代码问题。 尽管如此,InstructGPT 的 refinement 通常是正确的,即使 feedback 本身不是。 人工书面 feedback 平均解决了更多的错误,并且从不给出无关的 feedback。 我们在附录A.3中提供了人类和 InstructGPT 反馈之间差异的进一步示例。
-
最后,我们探讨了 feedback 中处理的错误数量是否影响 π Refine \pi_{\text{Refine}} πRefine 修复原始代码样本的能力。 结果如图5所示。 解决的错误数量越多, π Refine \pi_{\text{Refine}} πRefine 的 refinement 平均通过率就越低。 这表明,未来工作的一个有希望的方向可能包括将 feedback 自动分解为多个步骤,并让 π Refine \pi_{\text{Refine}} πRefine 一步一步地将 feedback 合并。 事实上,Nijkamp 等人(2022)表明,当指令在多个回合中给出时,CODEGEN 模型通常在遵循指令方面更有效,最近的思想链工作(Wei 等人,2022)说明了类似的提示技术。
Conclusion & Discussions
Conclusion
ILF可以显著提高代码生成模型的质量,即使只需要少量的人工反馈和改进。
这种方法不是针对特定模型的,可以分多轮进行,以不断改进模型。
这种方法不仅能生成正确的代码,而且针对模型可能输出特定的错误。这一点是最近的LLM离线预训练所缺少的。
这种方法是样本高效的,尽管只对78组数据进行了微调,但是在Zero-shot baseline和 MBPP 数据的微调上,pass@1 rate 相对增加了38% 和64%
展望
随着LLM的发展,未来可能会部分的或者自动化的生成自然语言反馈,减少收集反馈所需的时间和成本。
未来工作的一个有希望的方向可能包括将feedback自动分解为多个步骤,并让Refine一步一步地将反馈合并。
不足之处
当一个Feedback中包含多个错误时, 𝜋_Refine整合Feedback的效果较差
仅仅对比了一个baseline模型,未能说明ILF算法对更多的LLM都有用
仅仅评估了𝜋_Refine能否通过单元测试,缺乏对所生成代码的质量的评估,例如时间复杂度等
没有探究ILF算法在代码生成任务中的性能提升是否与具体的代码语言相关,仅仅对比了Python语言
这篇关于【网安AIGC专题10.11】2 ILF利用人类编写的 自然语言反馈 来训练代码生成模型:自动化反馈生成+多步反馈合并+处理多错误反馈+CODEGEN -M ONO 6.1 B model的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






