反馈专题

uniapp设置微信小程序的交互反馈
链接:uni.showToast(OBJECT) | uni-app官网 (dcloud.net.cn) 设置操作成功的弹窗: title是我们弹窗提示的文字 showToast是我们在加载的时候进入就会弹出的提示。 2.设置失败的提示窗口和标签 icon:'error'是设置我们失败的logo 设置的文字上限是7个文字,如果需要设置的提示文字过长就需要设置icon并给

Adblock Plus官方规则Easylist China说明与反馈贴(2015.12.15)
-------------------------------特别说明--------------------------------------- 视频广告问题:因Adblock Plus的局限,存在以下现象,优酷、搜狐、17173黑屏并倒数;乐视、爱奇艺播放广告。因为这些视频网站的Flash播放器被植入了检测代码,而Adblock Plus无法修改播放器。 如需同时使用ads

今麦郎「日记薪·1号发」 即时反馈,激活10000+名基层员工
本文内容整理自红海云CEO孙伟对今麦郎集团人力资源总经理王高峰、IT管理中心副总经理邹大勇的访谈。 坚持创新求变的品牌基因 过去30年,中国食品工业蓬勃发展,孕育出一批批在国际舞台上熠熠生辉的民族品牌。今麦郎作为民族品牌代表,自1994年创立以来,始终紧跟消费者需求变迁,从满足基础温饱的初心出发,逐步迈向品牌塑造、健康倡导及高端化探索的新征程,从家喻户晓的“今麦

uniapp交互反馈
页面交互反馈可以通过:uni.showToast(object)实现,常用属性有 ioc值说明 值说明success显示成功图标,此时 title 文本在小程序平台最多显示 7 个汉字长度,App仅支持单行显示。error显示错误图标,此时 title 文本在小程序平台最多显示 7 个汉字长度,App仅支持单行显示。fail显示错误图标,此时 title 文本无长度显示。exception

Geomagic Touch触觉力反馈设备,在虚拟环境中提供真实的反馈力
在虚拟现实(VR)和增强现实(AR)技术日益成熟的今天,为用户提供更加真实、沉浸的交互体验成为了技术发展的重要方向。Geomagic Touch触觉力反馈设备凭借其卓越的性能和广泛的应用领域,成为了这一领域中的佼佼者。本文将探讨Geomagic Touch如何在虚拟环境中提供真实的反馈力,为用户带来前所未有的体验。 卓越的力反馈技术 Geomagic Touch(原Sensable Phant

论文速读|ROS-LLM:具有任务反馈和结构化推理的具身智能ROS 框架
论文地址:https://arxiv.org/pdf/2406.19741 ROS-LLM 框架旨在通过集成大型语言模型(LLM)和机器人操作系统(ROS),实现对机器人的直观编程。该框架支持通过聊天界面接收自然语言提示,并能够根据 ROS 环境中的传感器读数自动提取和执行行为。框架支持三种行为模式:序列、行为树和状态机。此外,通过模仿学习,用户可以向系统添加新的机器人动作。该研究通过实验


第三章 转折20 客户建设性反馈
客户侧接口人A姐本周给我反馈了,觉得小杨在财务收入项目上缺少经验,希望收入专家小萍能够加入到该项目的调研中。 这个反馈非常快,小杨的第一次用户调研后,我马上收到了这个反馈。 其实对这个反馈,我并不惊讶,惊讶地只是来得如此之快。在这个项目刚启动时,我也是再三斟酌,才让小杨作为PM加入项目的,主要考量点: 1)小萍太忙了,需求调研根本没时间做,这对于产品经理的成长是非常不利的,产出也是没有保障的

景芯SoC A72实战反馈
先说结论: 内容非常全面,讲解到位,会有专门的工程师一对一答疑,整个项目跑下来提升非常大,绝对物超所值! 一些细节: 本人微电子专业研一在读,有过两次简单的数字芯片流片经历,出于学习和科研需要,报了景芯的12nm A72 UPF DVFS后端实战。 整个项目基于innovus实现,主要包括芯片partition、maia_cpu的PR和MAIA顶层的PR三个阶段。在每个阶段PR结束之后,对

六西格玛黑带培训的评估结果如何反馈给学员?
在探讨如何将六西格玛黑带培训的评估结果有效反馈给学员时,我们首先需要明确评估的目的不仅在于衡量学员的学习成效,更在于促进学员的持续成长与自我提升。因此,反馈机制的设计应当既严谨又充满人文关怀,确保每位学员都能从中获得实质性的帮助与激励。具体方法如天行健六西格玛顾问下文所述: 一、评估结果的全面解析 在反馈之前,对评估结果进行全面而细致的分析是至关重要的一步。这包括但不限于: - 知识掌握

android反馈Crash报告
此文章转载他人,担有所改动,,在全局获取异常有所改动 为什么需要反馈Crash报告? 做Android应用程序,要尽量避免程序Crash的发生。虽然说零Crash是程序员追逐的最终目标,但是现实的情况是,程序员只能尽量的减少Crash的发生,而几乎不可能完全杜绝Crash。也许,你认为你的应用的健壮性已经近乎完美,轻松的经受住了测试部门魔鬼般的考验,但是当你的应用发布到市
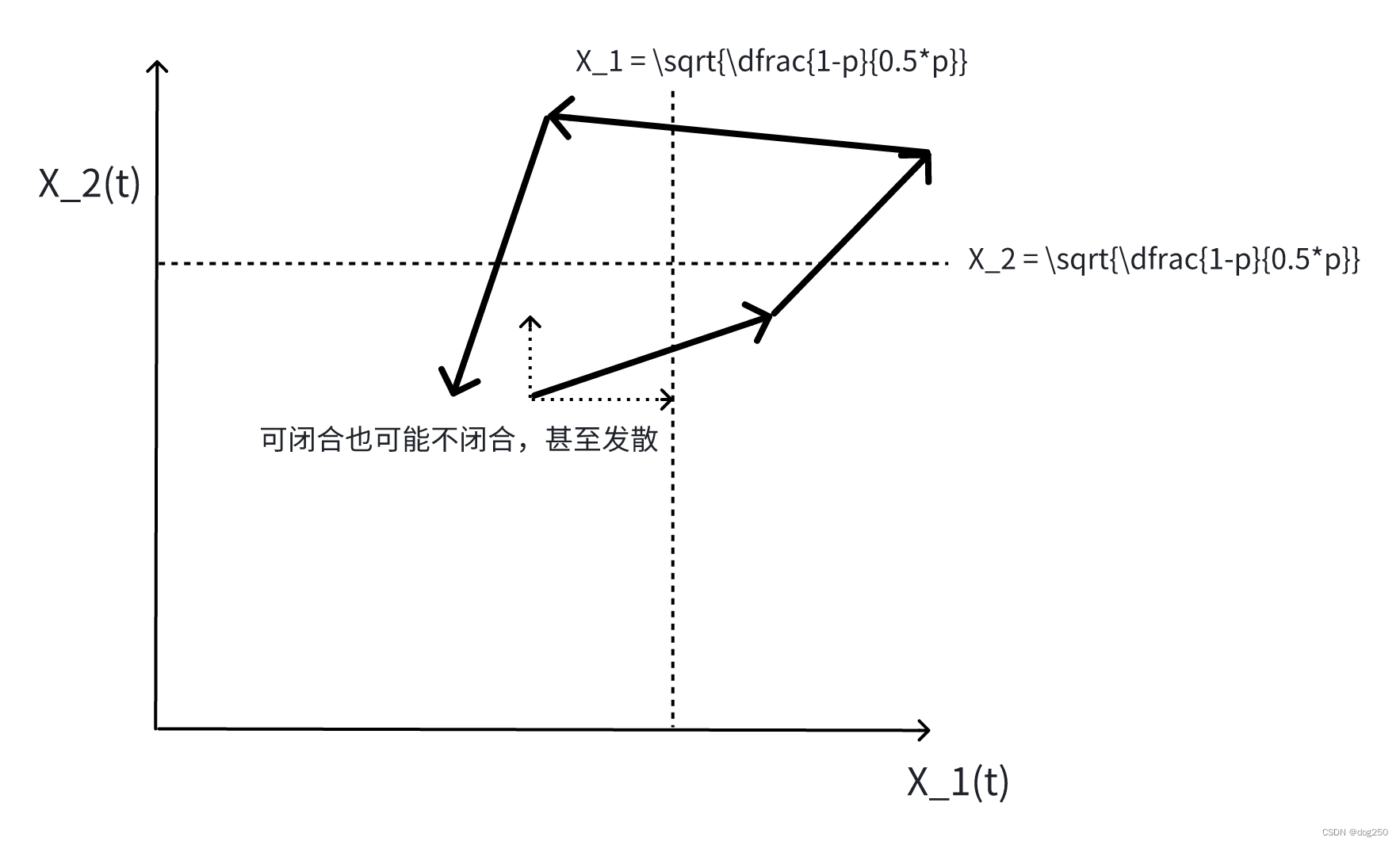
反馈时延与端到端拥塞控制
先从 越来越无效的拥塞控制 获得一个直感。 开局一张图,剩下全靠编。这是一道习题: 这图来自《高性能通信网络(第二版)》,2002 年的书,很好很高尚,目前这种书不多了。不准备做这道题,但意思要明白,时延越大越不同,系统越震荡,甚至跑飞不稳定,这个道理也可以从相轨迹看出。首先,先看经典的 aimd 收敛图是如何获得的。 aimd 系统的微分方程如下: d W d t = ( 1 − p

VFB电压反馈和CFB电流反馈运算放大器(运放)选择指南
VFB电压反馈和CFB电流反馈运算放大器(运放)选择指南 电流反馈和电压反馈具有不同的应用优势。在很多应用中,CFB和VFB的差异并不明显。当今的许多高速CFB和VFB放大器在性能上不相上下,但各有其优缺点。本指南将考察与这两种拓扑结构相关的重要考虑因素。 VFB和CFB运算放大器的直流及运行考虑因素 VFB运算放大器 对于要求高开环增益、低失调电压和低偏置电流的精密低频应用,VFB运算放

从0开发一个Chrome插件:用户反馈与更新 Chrome 插件
前言 这是《从0开发一个Chrome插件》系列的第二十二篇文章,也是最终篇,本系列教你如何从0去开发一个Chrome插件,每篇文章都会好好打磨,写清楚我在开发过程遇到的问题,还有开发经验和技巧。 专栏: 从0开发一个Chrome插件:什么是Chrome插件?从0开发一个Chrome插件:开发Chrome插件的必要知识从0开发一个Chrome插件:搭建开发环境从0开发一个Chrome插件:创建

搜维尔科技:SenseGlove虚拟训练、VR/AR 模拟和研究中的触觉反馈
训练 传统培训成本高昂且风险大,需要重复资产或停产。在培训中使用虚拟现实可以轻松解决这些问题。借助 SenseGlove,终于可以研究和评估与传统培训效果相同的虚拟培训技术。体验低成本的定制 VR 培训,同时保留现实世界的肌肉记忆和记忆力。 模拟和建模 借助 SenseGlove,与数字模型的交互变得与物理模型的交互类似。评估您的设计是否符合人体工程学,用 VR 或 AR 模拟制造过
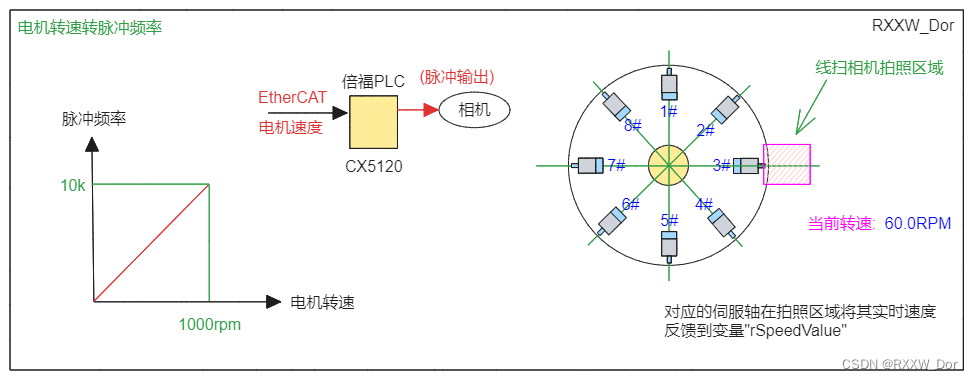
视觉应用线扫相机速度反馈(伺服转盘)
运动控制实时总线相关内容请参考运动控制专栏,这里不再赘述 1、运动控制常用单位u/s运动控制单位[u/s]介绍_运动控制 unit是什么单位-CSDN博客文章浏览阅读176次。运动控制很多手册上会写这样的单位,这里的u是英文单词unit的缩写,也就是单位的意思,所以这里的单位不是微米/秒,也不是毫米/秒,这里是一个泛指,当我们的单位选择脉冲时,它就是脉冲/秒,也就是我们说的频率(HZ)。常用脉冲

跨语言翻译的突破:使用强化学习与人类反馈提升机器翻译质量
在人工智能领域,知识问答系统的性能优化一直是研究者们关注的焦点。现有的系统通常面临知识更新频繁、检索成本高、以及用户提问多样性等挑战。尽管采用了如RAG(Retrieval-Augmented Generation)和微调等技术,但它们各有利弊,例如RAG在知识内容多的情况下检索成本高,而微调则面临算力成本高和训练效果不稳定的问题。 为了克服这些难题,研究者们开始探索使用强化学习与人类反馈(RL
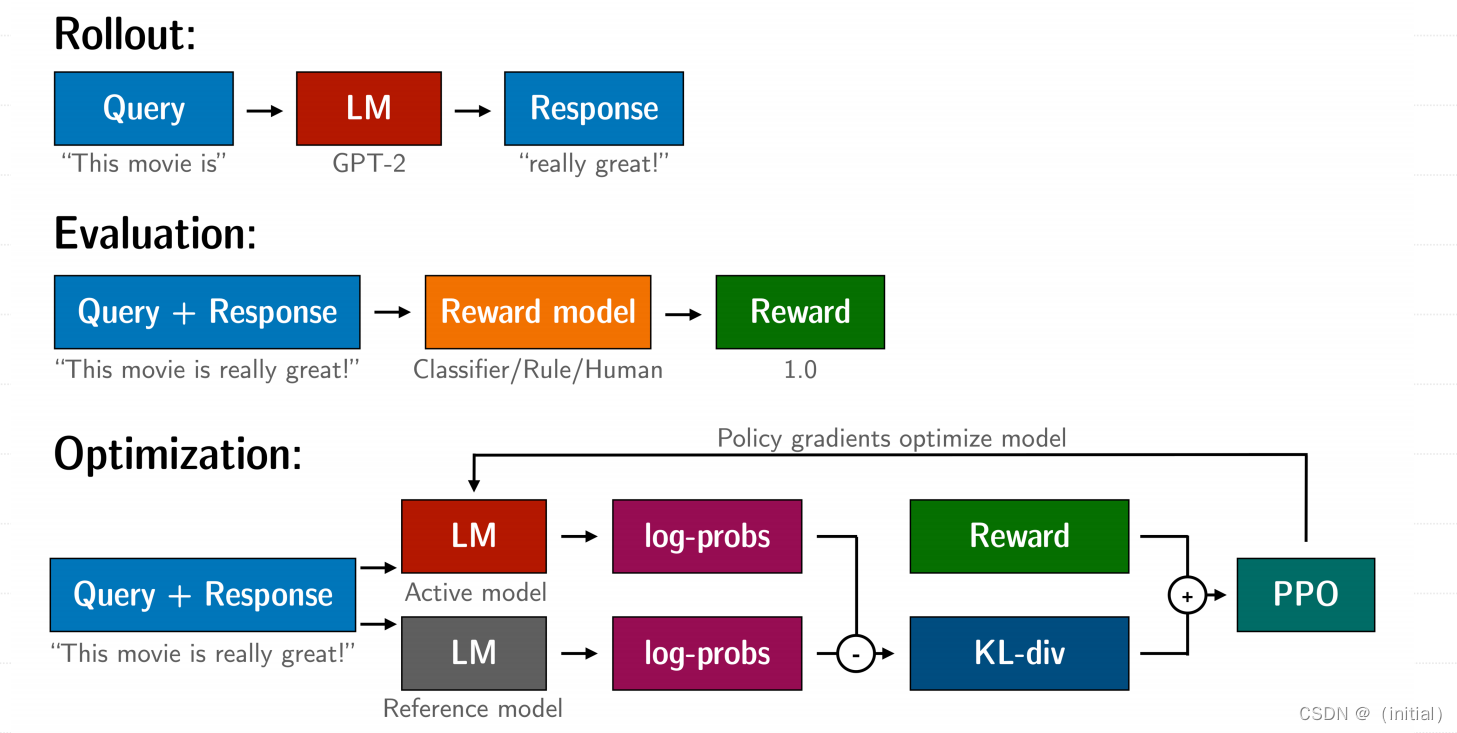
14.基于人类反馈的强化学习(RLHF)技术详解
基于人类反馈的强化学习(RLHF)技术详解 RLHF 技术拆解 RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,我们按三个步骤分解: 预训练一个语言模型 (LM) ;训练一个奖励模型 (Reward Model,RM) ;用强化学习 (RL) 方式微调 LM。 步骤一:使用SFT微调预训练语言模型 先收集⼀个提示词集合,并要求标注⼈员写出⾼质量的回复,然后使⽤该数据集以监督的⽅

【成品设计】基于STM32的单相瞬时值反馈逆变器
《基于STM32的单相瞬时值反馈逆变器》 整体功能: 图13 软件框图 如图13所示,由于本设计中需要通过定时器中断执行一些程序,故首先对中断进行初始化。中断初始化以后即为对串口进行初始化,总共初始化了两个串口,第一个串口波特率为9600,主要目的是为了传输数据至串口调试助手用来测试。第二个串口波特率为4800,主要目的是接收电能测量得出的数据,解析电能测量模块传过来的串口数据,采集到交流
线性反馈移位寄存器(LFSR)的原理
线性反馈移位寄存器(LFSR)是一种常用的伪随机数生成器,广泛应用于密码学和计算机科学领域。其基本原理是利用一个或多个异或门对寄存器的某些位进行线性反馈操作,从而生成伪随机序列。 原理LFSR的核心在于其反馈机制。具体来说,LFSR通过将当前寄存器状态作为输入信号,并通过一系列异或门对这些输入信号进行变换,从而得到下一个状态。这种操作可以表示为: xn=f(xn−1,xn−2,…,x1
RLHF(从人类反馈中进行强化学习)详解(四)
在人工智能领域,强化学习人类反馈(Reinforcement Learning from Human Feedback, RLHF)是一种将人类反馈与强化学习相结合的方法。通过引入人类反馈,RLHF可以训练出更符合人类期望和需求的智能体。然而,要确保训练效果,评测成为了关键的一环。本篇博客将详细探讨RLHF中的评测技术,并提供具体实例和代码示例。 什么是RLHF? RLHF是一种通过人类反馈来
用户反馈解决方案 —— 兔小巢构建反馈功能
目录 01: 前言 02: 用户反馈整体实现方案分析 03: 兔小巢全解析 04: 基于兔小巢实现用户反馈 05: 总结 01: 前言 在前台系统中,用户反馈 功能也是一个非常常见的需求。 通过反馈功能,我们可以知道当前的应用存在的一些不足和用户相应的一些诉求。 通常情况下,构建用户反馈平台有两种方式: 1. 自研反馈平台:数据自主,但是成本较高。 2. 第三
关于《RecyclerView的item添加悬浮层的效果》的问题反馈
前言 如果你还没看过自定义View:实现RecyclerView的item添加悬浮层的效果,可以先阅读上一篇。 上一周向郭神的微信公众号投稿《RecyclerView的item添加悬浮层的效果》,看到有那么多的朋友阅读和留言评论,心情十分激动,文章已将近过去一周,阅读的高峰期应该已经过去了,这里针对评论反馈的问题,来写一个解答篇。 正文 ListView版本已发布 之前说会做一个List
高效程序员的45个习惯之敏捷反馈
高效程序员的第十九个习惯:守护天使 使用自动化的单元测试。好的单元测试能为你的代码问题提供及时的警报。如果没有到位的单元测试,不要进行任何设计和代码修改。 高效程序员的第二十个习惯:先用它再实现它 将TDD(测试驱动开发)作为设计工具,它会为你带来更简单更有实效的设计。 高效程序员的第二十一个习惯:不同环境,就有不同问题 使用持续集成工具,在每一种支持的平台和环境中运行单元测试。要积极的
管理能力学习笔记十一:如何通过反馈做好辅导
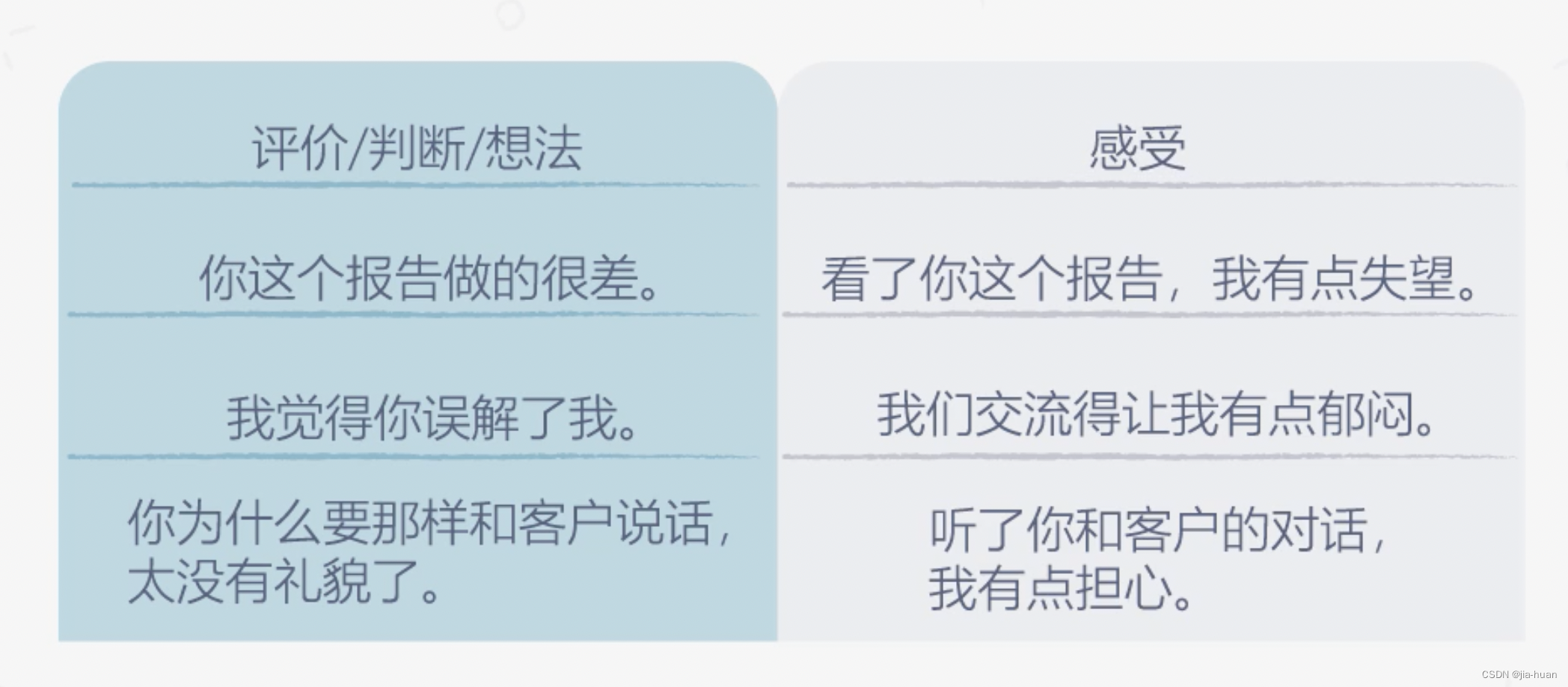
关于辅导的常见错误 辅导过于细致 辅导的首要障碍: 不相信对方的潜力需要有成长型思维:即便员工现在不OK,未来会更好因材施教:对不同风格的下属,采取不同的辅导风格 凡事亲力亲为 作为管理者,我们要做的是:辅导员工做到,而不是替他们做到分配工作时不能分配过于超过他们能力的工作 把辅导变成了较劲 辅导效果不佳:就要考虑是否是辅导问题,是否是人岗不匹配 如何对员工进行具体的辅导 消极反馈