本文主要是介绍Jetson_yolov8_解决模型导出.engine遇到的问题、使用gpu版本的torch和torchvision、INT8 FP16量化加快推理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、前情提要
英伟达Jetson搭建Yolov8环境过程中遇到的各种报错解决(涉及numpy、scipy、torchvision等)以及直观体验使用Yolov8目标检测的过程(CLI命令行操作、无需代码)-CSDN博客和YOLOv8_测试yolov8n.pt,yolov8m.pt训练的时间和效果、推理一张图片所需时间_解决训练时进程被终止killed-CSDN博客这两篇中,已经在Jetson环境下使用yolov8训练模型、使用yolov8n.pt和yolov8m.pt来对图片、视频进行目标检测。
遇到的问题是,检测的耗时非常久,即便是使用yolov8n.pt平均每张图片也需要预处理preprocess=7.3ms,推理interence=318.4ms,后处理postprocess=6ms,总计331.7ms;
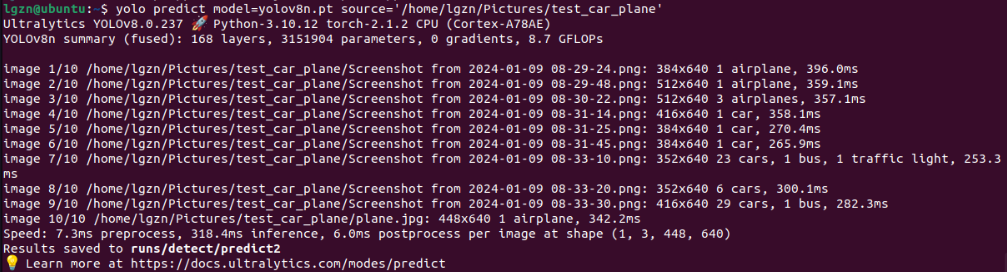
而在上面第二个链接所了解的性能图中,使用GPU的推理速度是非常快的,那么如何使用英伟达的GPU来加速这个推理的过程呢?
2、尝试模型导出.engine
在使用深度学习模型中有这么几个过程,训练、验证、预测/推理、导出、部署,其中训练模型是可以在任何机器上实现的,比如可以选择性能更好的计算机来训练你的模型,通过验证和推理来使模型达到预期的效果,然后导出部署到实际使用的设备上。
假设官方提供的模型(yolov8n.pt)已经满足要求,那么下一步就是如何导出适合于目标设备格式的模型。
下面介绍官网导出 - Ultralytics YOLOv8 文档对于导出这部分的基本操作,使用CLI方式导出的命令格式为:
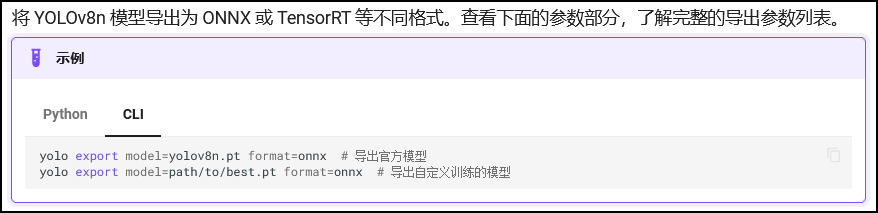
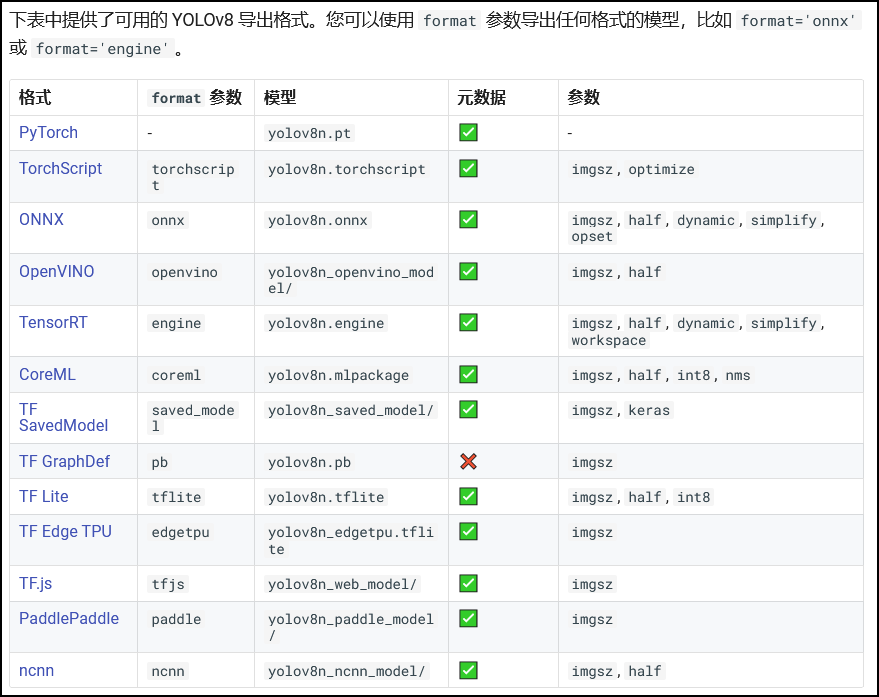
因为要部署的目标设备是不同的,所以yolov8提供了诸多导出格式,其中英伟达Jetson系列需要的是TensorRT格式,所以format=engine.
执行yolov8.pt导出.engine格式的命令:
yolo export model=yolov8n.pt format=engine
报错了,大概就是说.engine的这种TensorRT格式是需要GPU导出的,所以自动添加了一个参数device=0来指定设备是GPU,但是又无法使用device=0因为torch.cuda.is_available():False.
CUDA(Compute Unified Device Architecture),由显卡厂商NVIDIA推出的GPU运算平台。
这才知道torch和torchvision是分CPU、GPU版本的,于是开始下面的操作。
3、安装适合于英伟达Jetson系统GPU版本的torch和torchvision
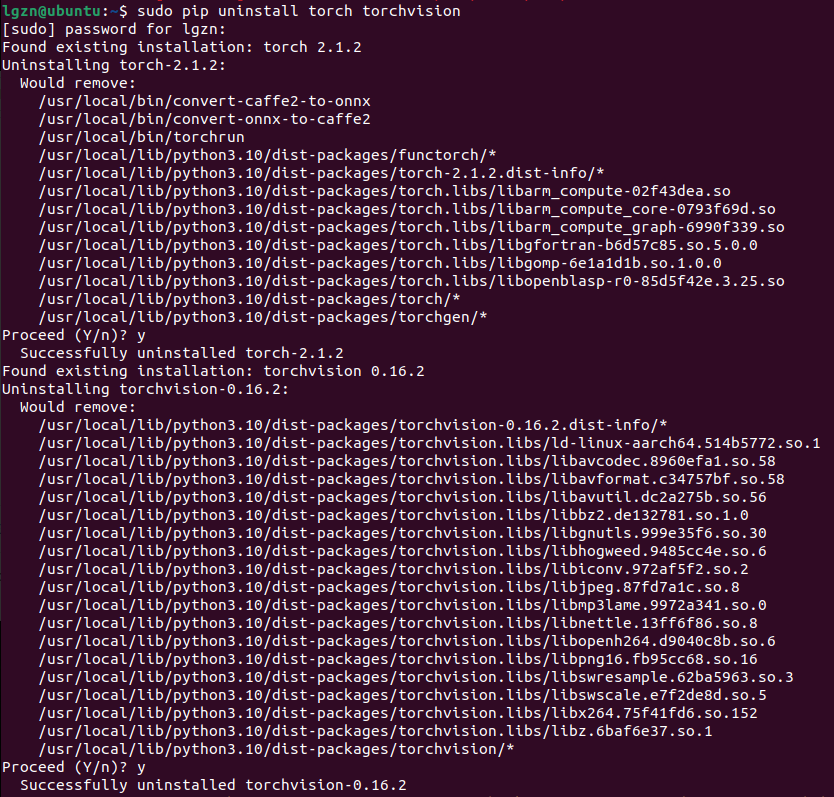
3.1、先卸载旧的torch和torchvision
sudo pip uninstall torch torchvision从下面的输出信息中看起来已经卸载了torch 2.1.2和torchvision 0.16.2。
3.2、安装torch和torchvision
3.2.1、安装途径以及选择torch和torchvision的版本
下面的安装方式来源于NVIDIA官网dPyTorch for Jetson - Announcements - NVIDIA Developer Forums
根据jtop查看JetPack版本为6.0,所以可以选择torch v2.2.0和v2.1.0,再结合下方torch和torchvision的版本匹配表格,最后一行是torchvision v0.16.1,所以最后选择torch v2.1.0,torchvision v0.16.1.(P.S.实际上torchvision最新版本不止v0.16.1,所以理论上可以选择更高的torch版本)
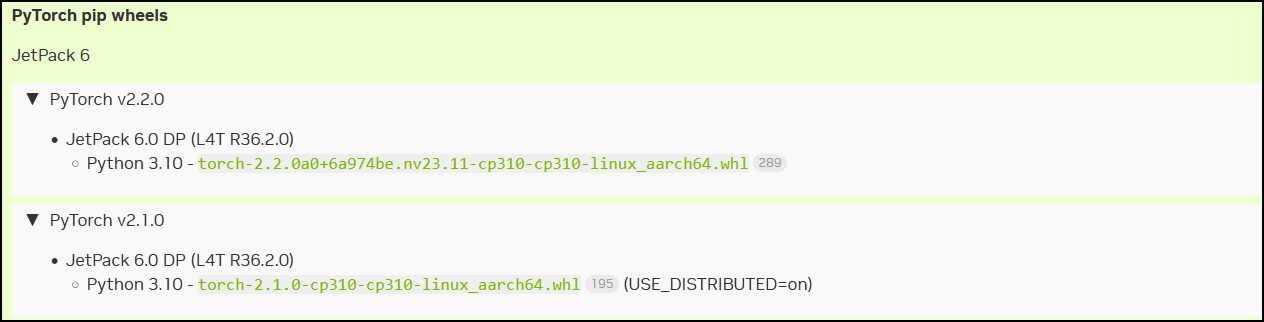

3.2.2、安装torch v2.1.0
先下载上面的torch2.1.0的.whl文件,然后使用pip命令安装。
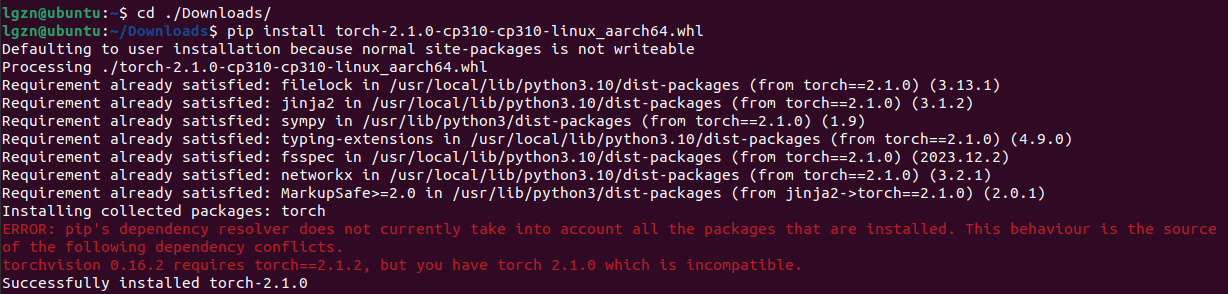
pip install torch-2.1.0-cp310-cp310-linux_aarch64.whl成功安装了torch v2.1.0,但是报了一个错,torchvision v0.16.2需要torch v2.1.2,但是安装的是torch是v2.1.0,这会导致incompatible不兼容。
但是想着上面已经卸载了torchvision v0.16.2,所以认为可能是什么残留的版本信息而已,此时就没管。
3.2.3、安装torchvision v0.16.1
官网关于torchvision的安装方式如下:
$ sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libopenblas-dev libavcodec-dev libavformat-dev libswscale-dev
$ git clone --branch <version> https://github.com/pytorch/vision torchvision # see below for version of torchvision to download
$ cd torchvision
$ export BUILD_VERSION=0.x.0 # where 0.x.0 is the torchvision version
$ python3 setup.py install --user
$ cd ../ # attempting to load torchvision from build dir will result in import error
$ pip install 'pillow<7' # always needed for Python 2.7, not needed torchvision v0.5.0+ with Python 3.6因为我的Python版本是3.10所以可以省略最后两步,因为github下载失败所以添加了反向代理,再修改实际使用的版本号,所以最后实际的指令为:
sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev libopenblas-dev libavcodec-dev libavformat-dev libswscale-dev
git clone --branch v0.16.1 https://mirror.ghproxy.com/https://github.com/pytorch/vision torchvision
cd torchvision
export BUILD_VERSION=0.16.1
python3 setup.py install --user安装过程大约用时15分钟,please wait patiently.(播音腔)
3.2.4、测试gpu版本的torch和torchvision是否安装成功
python3
import torch
import torchvision
torch.__version__
torchvision.__version__
torch.cuda.is_available()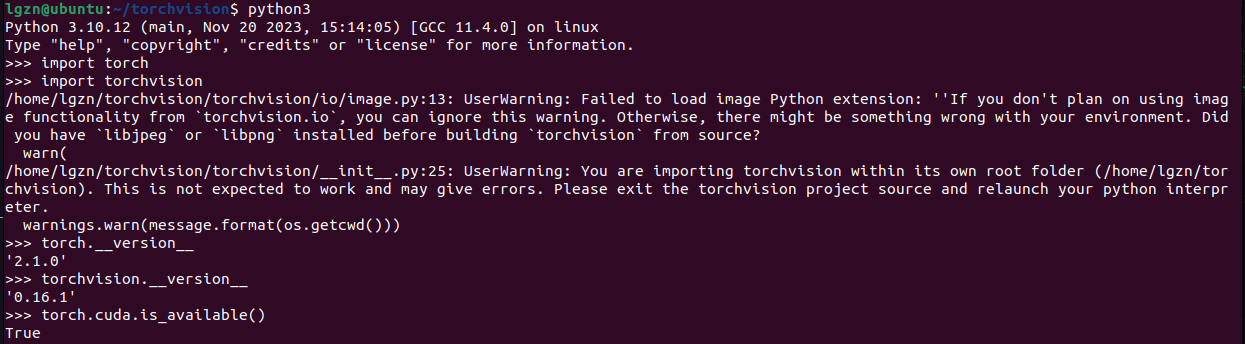
可以看到torch的版本是v2.1.0,torchvision的版本是v0.16.1,torch.cuda.is_available()是True,代表torch和torchvision正常并且torch可以访问GPU.
4、测试yolov8使用GPU推理-加速
4.1、解决遗留问题的报错
于是开始执行推理,发现了一个好消息和一个坏消息。
好消息是Ultralytics YOLOv8.0.237 python-3.10.12 后面torch-2.1.0 CUDA:0(Orin,7620MiB),说明yolov8可以使用GPU了,并且识别出设备是Jetson Orin系列,内存是8G.
坏消息是torch和torchvision的版本不兼容。
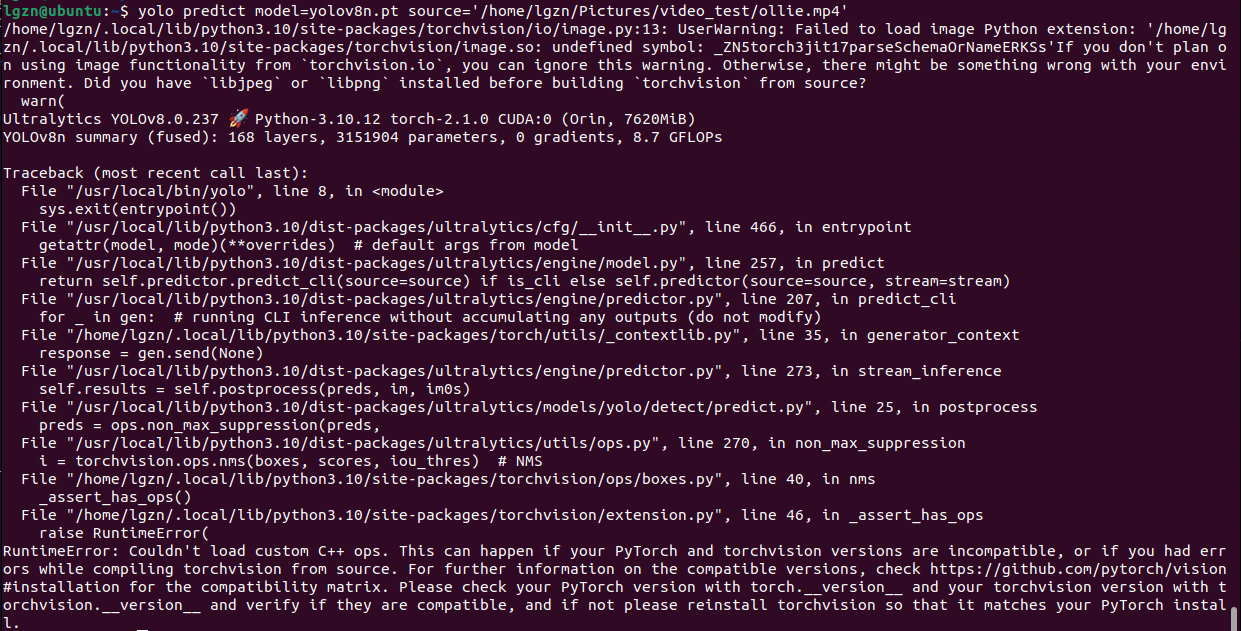
虽然我确认刚才选择的torch和torchvision版本是匹配的,而且在【3.2.4】小节也实际打印出了版本符合要求,但还是提示不兼容,这就想到了【3.2.2、安装torch v2.1.0】时产生的报错,可能系统使用的是没卸载干净的torchvision v0.16.2,于是使用pip list再次查看,果然torchvision版本是v0.16.2.于是再次卸载torchvision,注意指定版本0.16.2,因为刚才还安装了0.16.1.
对比了两次卸载torchvision的区别,使用的指令不同,第一次加了sudo,卸载涉及的路径也不同。
4.2、GPU加速推理与CPU对比
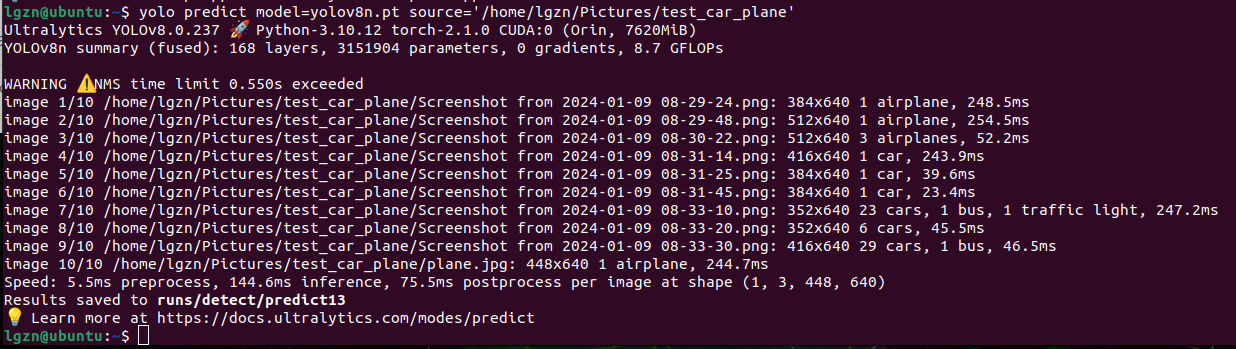
使用yolov8.pt执行GPU推理:
对比使用yolov8.pt执行CPU推理:
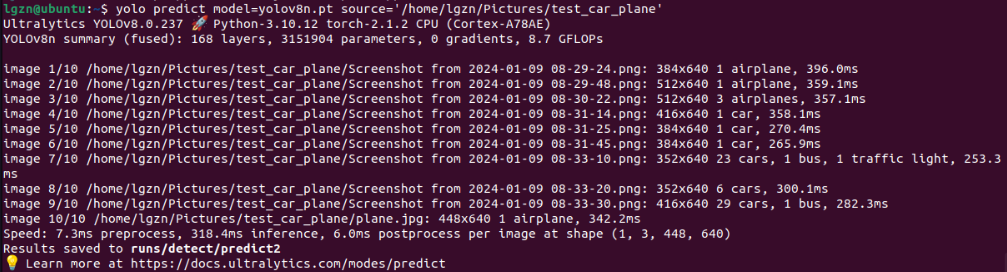
推理的时间从每张图片平均318.4ms提升到了144.6ms,是快了,但仍然不是很好,下面尝试.engine格式的。
好像又有新的问题了,后处理postprocess的时间从6ms增加到了75.5ms.
5、.pt一键导出.engine
使用yolov8提供的CLI命令,一键就可将.pt的模型导出.engine格式,方便。
yolo export model=yolov8n.pt format=engine总体流程是先转成onnx格式,然后再将onnx格式转成engine格式。

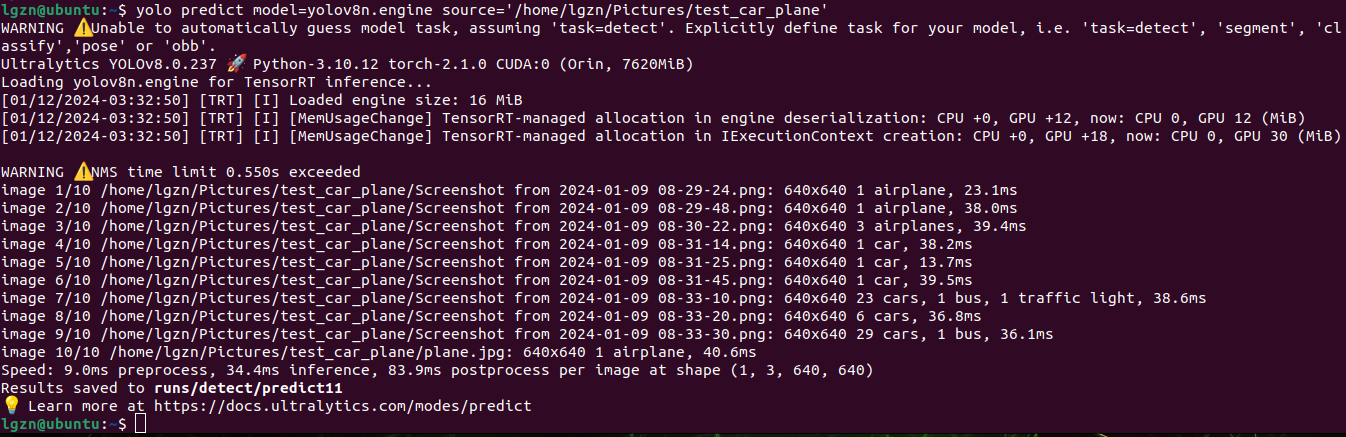
6、测试.engine的推理速度
效果很明显,平均每张图片提升到了34.4ms,与之前的三百多ms相比差不多快了10倍,但是也就那样,最终的目的是要实时识别视频的,30fps来算起码一帧需要在33ms以下。
7、调整导出.engine的参数进一步提高速度_使用INT8、FP16量化
导出 - Ultralytics YOLOv8 文档,可以得到可修改的参数列表如下:

将导出.engine的参数int8和half修改为True:
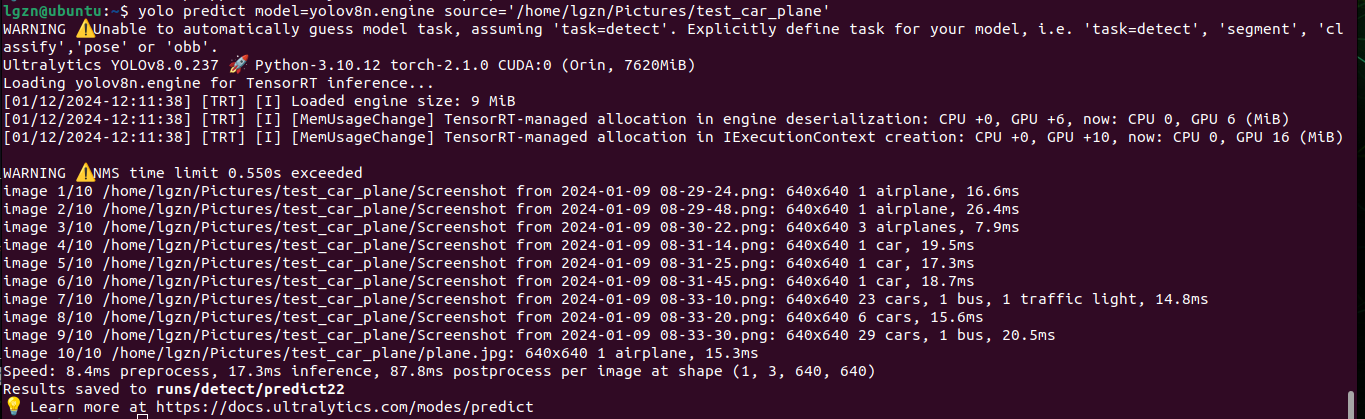
yolo export model=yolov8n.pt format=engine int8=True half=True加INT8、FP16量化之后,一张图片的推理时间从34.4ms提升到17.3ms,速度又提高了2倍。
这篇关于Jetson_yolov8_解决模型导出.engine遇到的问题、使用gpu版本的torch和torchvision、INT8 FP16量化加快推理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




