int8专题
![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
引言 今天带来第一篇量化论文LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale笔记。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 大语言模型已被广泛采用,但推理时需要大量的GPU内存。我们开发了一种Int8矩阵乘法的过程,用于Transformer中的前馈和注意力投影层,这可以将推理所需

六. 部署分类器-int8-calibration
目录 前言0. 简述1. 案例运行2. 补充说明3. 代码分析3.1 main.cpp3.2 trt_model.cpp3.3 trt_calibrator.hpp3.4 trt_calibrator.cpp 4. 校准精度影响因素结语下载链接参考 前言 自动驾驶之心推出的 《CUDA与TensorRT部署实战课程》,链接。记录下个人学习笔记,仅供自己参考 本次课程我们来学习

int8量化和tvm实现
量化主要有两种方案 直接训练量化模型如Deepcompression,Binary-Net,Tenary-Net,Dorefa-Net对训练好的float模型(以float32为例)直接进行量化(以int8为例),这边博客主要讲这个 参考NIVIDIA 量化官方文档 int8量化原理 将已有的float32型的数据改成A = scale_A * QA + bias_A,B类似,NVIDI

【tensorrt】——int8量化
转载自:https://arleyzhang.github.io/articles/923e2c40/ tensorrt int8量化的流程可参考:【tensorrt】——int8量化过程浅析/对比 1 Low Precision Inference 现有的深度学习框架 比如:TensorFlow,Caffe, MixNet等,在训练一个深度神经网络时,往往都会使用 float 32(

golang中int int8 int16 int32 int64 uint8 uint16 uint32 uint64 占用字节和取值范围
================================ go grpc-go 相关技术专栏 总入口 go语言基础知识总结、整理、收藏 ================================ 本次测试的环境是Mac系统下,CPU 64位。 注意: go语言中的int的大小是和操作系统位数相关的; 如果是32位操作系统,int类型的大小就是4字节;如果是64位操作系统

FP16、BF16、INT8、INT4精度模型加载所需显存以及硬件适配的分析
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了FP16、INT8、INT4精度模型加载占用显存大小的分析,希望对学

AI大模型量化格式介绍(GPTQ,GGML,GGUF,FP16/INT8/INT4)
在 HuggingFace 上下载模型时,经常会看到模型的名称会带有fp16、GPTQ,GGML等字样,对不熟悉模型量化的同学来说,这些字样可能会让人摸不着头脑,我开始也是一头雾水,后来通过查阅资料,总算有了一些了解,本文将介绍一些常见的模型量化格式,因为我也不是机器学习专家,所以本文只是对这些格式进行简单的介绍,如果有错误的地方,欢迎指正。 What 量化 量化在 AI 模型中,特别是在深度

go int int8 int16 int32 int64 占几个字节
go int int8 int16 int32 int64 占几个字节 在Go语言中,int类型的大小取决于具体的平台,它会根据不同的系统而变化。在32位系统上,int类型通常占4个字节(32位),而在64位系统上,int类型通常占8个字节(64位)。而int8、int16、int32和int64分别指定了整数的位数,即8位、16位、32位和64位,它们分别占据1个字节、2个字节、4个字节和8个

【yolov5】onnx的INT8量化engine
GitHub上有大佬写好代码,理论上直接克隆仓库里下来使用 git clone https://github.com/Wulingtian/yolov5_tensorrt_int8_tools.git 然后在yolov5_tensorrt_int8_tools的convert_trt_quant.py 修改如下参数 BATCH_SIZE 模型量化一次输入多少张图片 BATCH 模型量化次数

大模型量化技术原理-LLM.int8()、GPTQ
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,从而导致模型变得越来越大,因此,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。 模型压缩主要分为如下几类: 剪枝(Pruning)知识蒸馏(Knowledge Distillation)量化 之前也写过一些文章涉及大模型量化相关的内容。 基于LLaMA-7B/Bloomz-7

飞桨paddlespeech语音唤醒推理C INT8 定点实现
前面的文章(飞桨paddlespeech语音唤醒推理C定点实现)讲了INT16的定点实现。因为目前商用的语音唤醒方案推理几乎都是INT8的定点实现,于是我又做了INT8的定点实现。 实现前做了一番调研。量化主要包括权重值量化和激活值量化。权重值由于较小且均匀,还是用最大值非饱和量化。最大值法已不适合8比特激活值量化,用的话误差会很大,识别率等指标会大幅度的降低。激活值量化好多方案用的是NVI
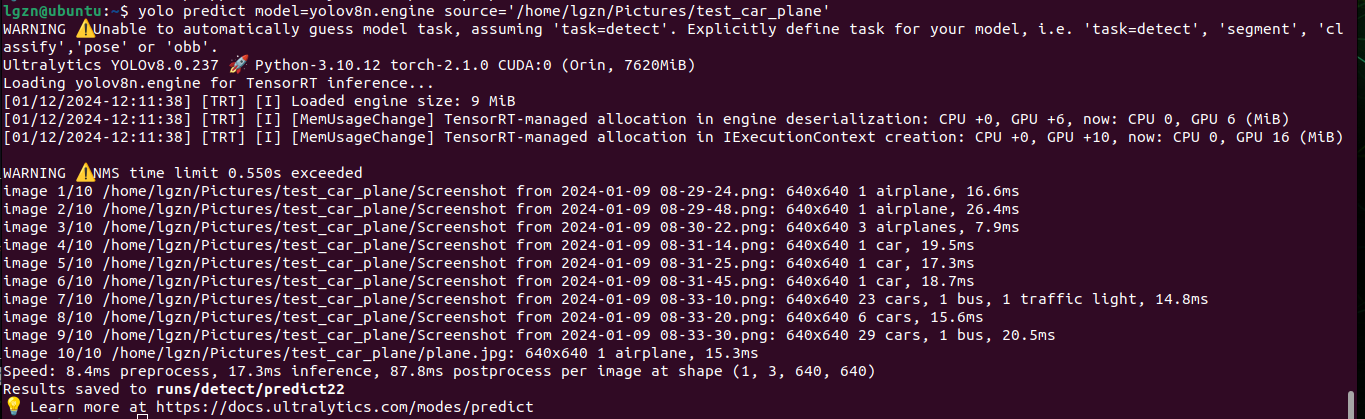
Jetson_yolov8_解决模型导出.engine遇到的问题、使用gpu版本的torch和torchvision、INT8 FP16量化加快推理
1、前情提要 英伟达Jetson搭建Yolov8环境过程中遇到的各种报错解决(涉及numpy、scipy、torchvision等)以及直观体验使用Yolov8目标检测的过程(CLI命令行操作、无需代码)-CSDN博客和YOLOv8_测试yolov8n.pt,yolov8m.pt训练的时间和效果、推理一张图片所需时间_解决训练时进程被终止killed-CSDN博客这两篇中,已经在Jetson环境

基于算能的国产AI边缘计算盒子,内置强悍TPU | 32TOPS INT8算力
边缘计算盒子 内置强悍TPU | 32TOPS INT8算力 ● 支持浮点运算的TPU平台盒子,支持32TOPS@INT8,16TFLOPS@FP16,2TFLOPS@FP32高算力 ● 单芯片最高支持32路H.264 & H.265的实时解码能力 ● 支持国产算法框架Paddle飞桨,适配Caffe/TensorFlow/MxNet/PyTorch/ONNX等主流深度学习框架 ● 支持

史上最快的实例分割SparseInst Int8量化实录
近期,YOLOv7里面借鉴(复 制 粘 贴)了一个新的模型,SparseInst,我借助YOLOv7的基建能力,将其导出到了ONNX, 获得了一个非常不错的可以直接用OnnxRuntime, 或者TensorRT跑的实例分割 (后续也可能把link加到官方的repo当中)。索性就一不作二不休,把int8也给他加上。于是就有了这个踩坑记录博客。 本文将带你从0开始量化一个复杂网络,这个Spar

OpenVINO 2021r1 超分辨率重建 INT8量化 - Waifu2x
接下来试试超分的INT8量化, 还是拿waifu2x模型来试验 首先毫无意外的掉进坑里了... ... 本来系统里已经装好了OpenVINO 2021r2, 想直接从这个版本开始,先安装accuracy_checker和pot的最新版本 到openvino_2021\deployment_tools\open_model_zoo\tools\accuracy_checker目录下运行
PyTorch模型INT8量化基础
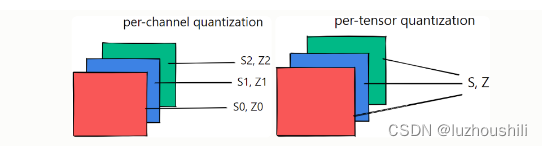
PyTorch模型INT8量化基础 最基础的Tensor量化校准两种不同的量化方案每张量和每通道量化方案量化后端引擎配置QConfigTensor量化Post Training Static Quantization (训练后静态量化)fuse_model:融合网络中的一些层 设置qCONFIGprepare: 定标 :scale 和 zero_point喂数据转换模型完整的demo-针对单
PyTorch模型INT8量化基础
PyTorch模型INT8量化基础 最基础的Tensor量化校准两种不同的量化方案每张量和每通道量化方案量化后端引擎配置QConfigTensor量化Post Training Static Quantization (训练后静态量化)fuse_model:融合网络中的一些层 设置qCONFIGprepare: 定标 :scale 和 zero_point喂数据转换模型完整的demo-针对单