fp16专题

fp16半精度浮点数转成float类型------C/C++
在深度学习算法模型推理时,会遇到fp16类型,但是我们的c语言中没有这种类型,直接转成unsigned short又会丧失精度,因此我们首先将FP16转成float类型,再进行计算。 方法1: typedef unsigned short ushort;//占用2个字节typedef unsigned int uint; //占用4个字节uint as_uint(const float
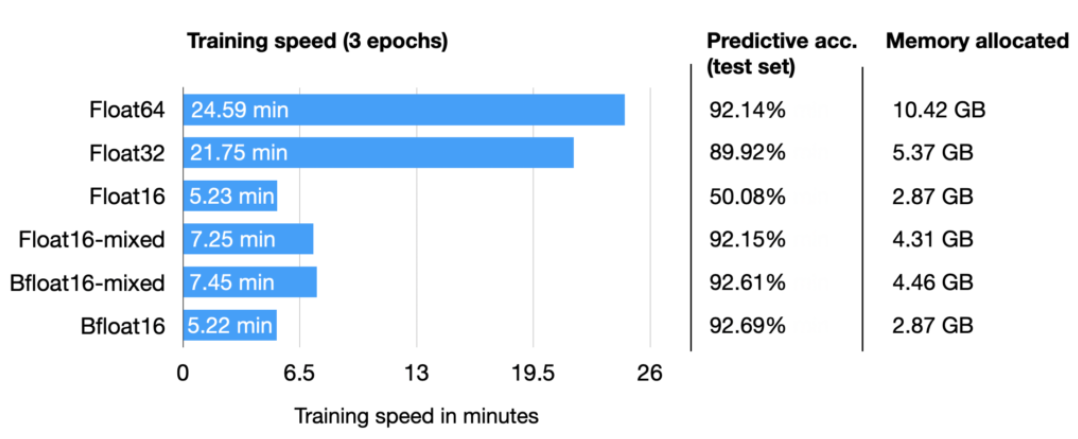
人工智能算力FP32、FP16、TF32、BF16、混合精度解读
彻底理解系列之:FP32、FP16、TF32、BF16、混合精度 随着大模型的涌现,训练和推理速度成为关键。为提升速度,需减小数据长度以降低存储和带宽消耗。为此,我专注学习并整理了各种精度细节,确保深入理解而非浅尝辄止。 1 从FP32说起 计算机处理数字类型包括整数类型和浮点类型,IEEE 754号标准定义了浮点类型数据的存储结构。
BF16相比FP16的优点
BF16和FP16 参考链接: Understanding the advantages of BF16 vs. FP16 in mixed precision trainingMegatron-LM & Megatron-CoreBFloat16: The secret to high performance on Cloud TPUs BF16相比FP16的优点: BF16和FP16都

FP16、BF16、INT8、INT4精度模型加载所需显存以及硬件适配的分析
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了FP16、INT8、INT4精度模型加载占用显存大小的分析,希望对学

AI大模型量化格式介绍(GPTQ,GGML,GGUF,FP16/INT8/INT4)
在 HuggingFace 上下载模型时,经常会看到模型的名称会带有fp16、GPTQ,GGML等字样,对不熟悉模型量化的同学来说,这些字样可能会让人摸不着头脑,我开始也是一头雾水,后来通过查阅资料,总算有了一些了解,本文将介绍一些常见的模型量化格式,因为我也不是机器学习专家,所以本文只是对这些格式进行简单的介绍,如果有错误的地方,欢迎指正。 What 量化 量化在 AI 模型中,特别是在深度

浮点数的存储方式、bf16和fp16的区别
目录 1. 小数的二进制转换2. 浮点数的二进制转换3. 浮点数的存储3.1 以fp32为例3.2 规约形式与非规约形式 4. 各种类型的浮点数5. BF16和FP16的区别Ref 1. 小数的二进制转换 十进制小数转换成二进制小数采用「乘2取整,顺序排列」法。具体做法是:用 2 2 2 乘十进制小数,可以得到积,将积的整数部分取出,再用 2 2 2 乘余下的小数部分,又得到
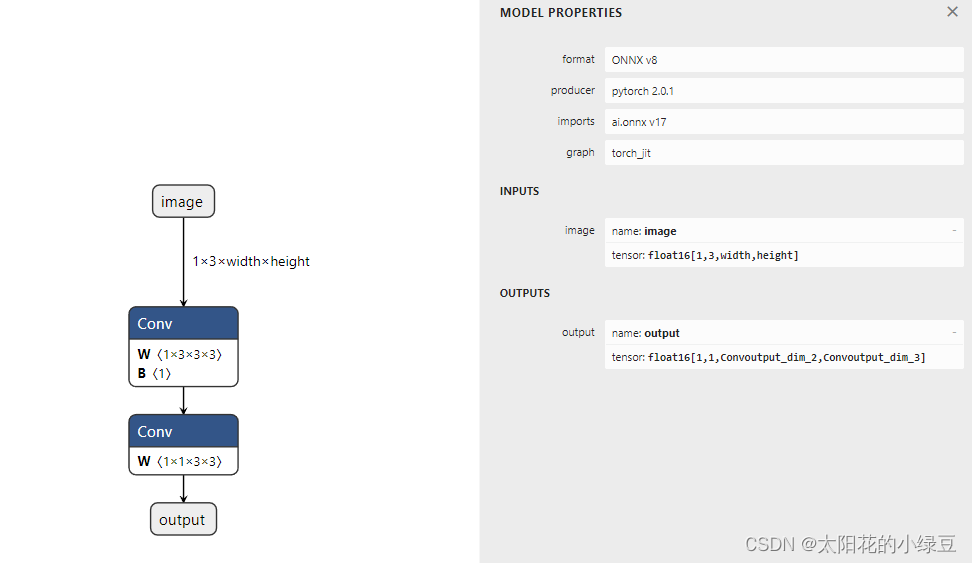
Pytorch导出FP16 ONNX模型
一般Pytorch导出ONNX时默认都是用的FP32,但有时需要导出FP16的ONNX模型,这样在部署时能够方便的将计算以及IO改成FP16,并且ONNX文件体积也会更小。想导出FP16的ONNX模型也比较简单,一般情况下只需要在导出FP32 ONNX的基础上调用下model.half()将模型相关权重转为FP16,然后输入的Tensor也改成FP16即可,具体操作可参考如下示例代码。这里需要注意
TensorRT custom_op注册 fp16及fp32相关问题
为什么fp16比fp32慢? 根据nvidia官方的说法,正好我的显卡是1070,所以出现了该问题.找不到正确的重载函数 这个问题没有找到原因,个人感觉还是跟编译器有关,因为同样的代码在Tx2上可以正常编译,在这里还请知道的朋友不吝指教.根据我的经验有两种解决思路: 1).改变写法,避开重载函数.2).指定重载函数类型,但这样会略微影响速度.记得确认自己的GPU_ARCHS,很多时候莫名奇妙的cu
模型精度fp16和fp32
FP16和FP32是两种不同的浮点数精度格式,在计算机科学特别是深度学习领域中广泛应用。 FP32(单精度浮点数): FP32代表32位(4字节)单精度浮点数格式,这是传统上大多数深度学习模型训练和推理的标准精度格式。它提供了大约7个有效数字的精度,并具有较大的动态范围(从约1.2e-38到约3.4e38)。由于更高的精度,它能够更好地捕捉较小的数值变化,对于复杂的深度学习模型中的梯度计算非常

PaddleDetection学习3——使用Paddle-Lite在 Android 上部署PicoDet模型(fp16)
使用Paddle-Lite在 Android 上运行PicoDet模型(fp16) 1. 环境准备2. 部署步骤2.1 下载Paddle-Lite-Demo2.2 打开 picodet_detection_demo项目2.2.1 修改build.gradle,配置国内镜像仓库2.2.2 NDK 配置错误问题2.2.3 gradle.properties文件配置2.2.4 NDK版本选择 2.
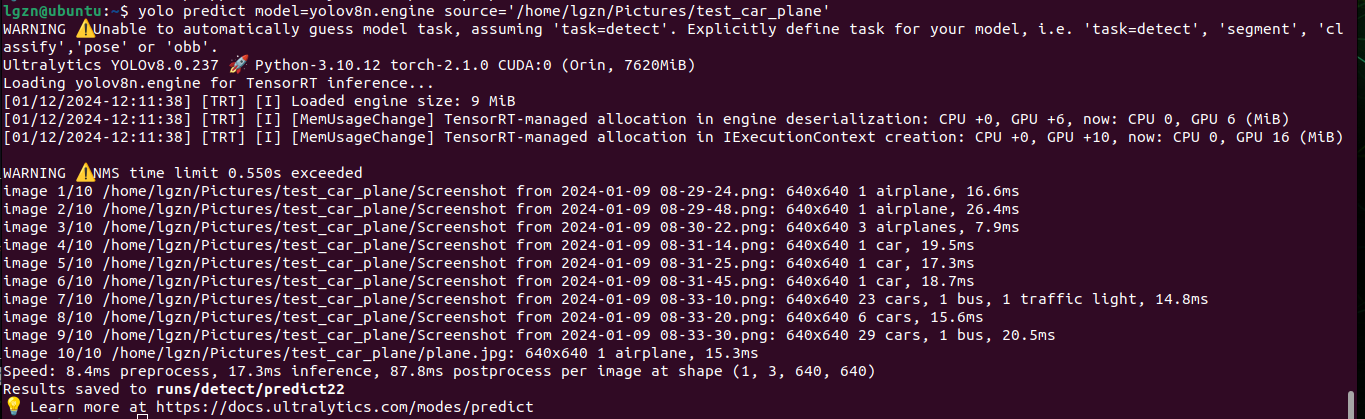
Jetson_yolov8_解决模型导出.engine遇到的问题、使用gpu版本的torch和torchvision、INT8 FP16量化加快推理
1、前情提要 英伟达Jetson搭建Yolov8环境过程中遇到的各种报错解决(涉及numpy、scipy、torchvision等)以及直观体验使用Yolov8目标检测的过程(CLI命令行操作、无需代码)-CSDN博客和YOLOv8_测试yolov8n.pt,yolov8m.pt训练的时间和效果、推理一张图片所需时间_解决训练时进程被终止killed-CSDN博客这两篇中,已经在Jetson环境
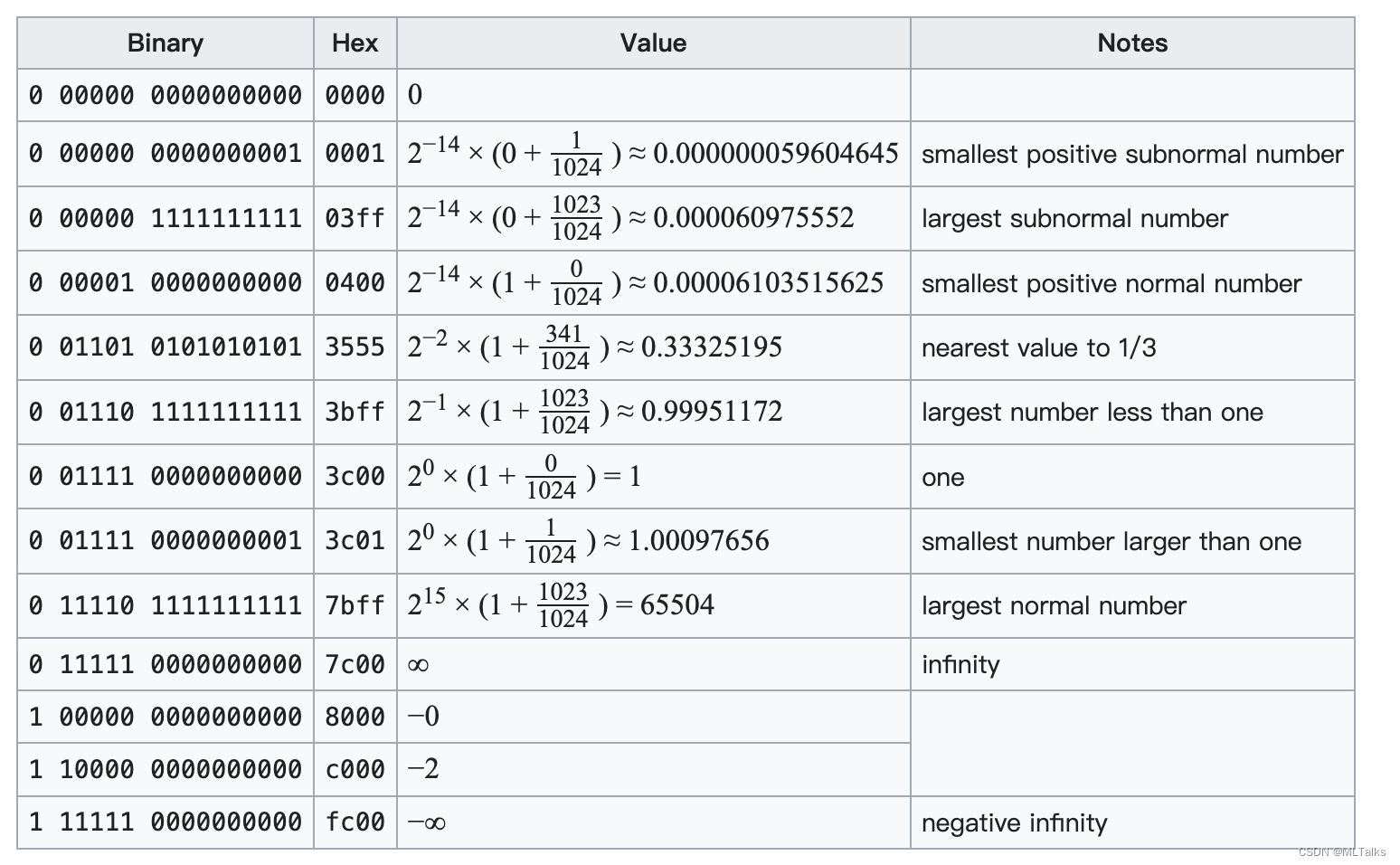
FP16数据格式详解
1. 浮点格式说明 浮点数的格式通常由三部分组成:符号位(Sign bit)、指数部分(Exponent)和尾数部分(Significand/Fraction)。整个浮点数占用的位数取决于不同的浮点数格式。例如,IEEE 754标准的单精度浮点数(float)有32位,双精度浮点数(double)有64位。参考:Floating-point arithmetic 最终的浮点表示如下,s是sig
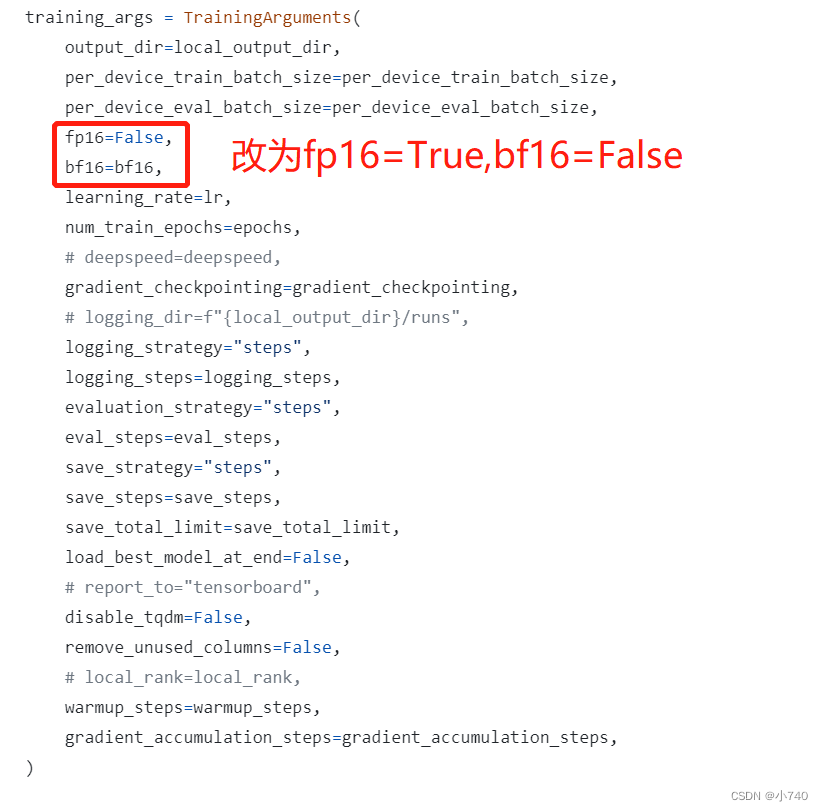
V100显卡无法支持dolly系列模型BP16运算及BP16与FP16模型转换解决方式
项目场景: 在模型训练过程中,可能会出现由BP16类型的模型需要转换到FP16类型的模型的需求,我研究了半天才试验出来,分享一个在实际过程中方便更改并能跑通的处理过程如下。 问题描述 V100无法支持BP16运算。 BP16类型的模型转换到FP16l类型的模型解决办法 原因分析: 在使用V100显卡进行模型训练:模型数据在加载及实际运算过程中会由自身配置的参数设定进行加载和运算,

Onnx精度转换 FP32->FP16
Onnx精度转换 FP32->FP16 1、依赖包 onnxonnxmltools 2、转换 from onnxmltools.utils.float16_converter import convert_float_to_float16from onnxmltools.utils import load_model,save_modelonnx_model = load_model("