本文主要是介绍深度学习方法(十六):Batch Normalization及其变种——Layer Norm, Group Norm,Weight Norm等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
很久没写博文了,今天晚上得点空, 抽时间把一块很基础的Layer设计——归一化层写一下,主要是方便自己日后查阅。写的可能会有点慢,有空就写一点。
本文的内容包括:
- Batch Normalization
- Layer Normalization
- Instance Normalization
- Group Normalization
- Weight Normalization
- Batch Renormalization
- Spectral Normalization for GAN
- …
Batch Normalization
第一篇肯定要讲下BN,现在BN基本上成为CNN类网络的标配,它通过缩放每一层Feature map值至均值0,方差1,让Feature map的分布在训练过程中不要发生大的变化,以此来加速网络的收敛。论文提到,这个就是受CV里面“白化Whitening”的启发,Whitening在很多图像处理中运用。
至于论文通篇在讲的为了避免 internal covariate shift,似乎略有牵强,在今年ICLR上还有专门文章问题原论文中该观点是错误的,就不细说了,感兴趣的同学建议还是去看下原文[1],我想这么多Normalization论文,至少要看看这一篇最经典的。
需要注意的是BN在训练过程和推理过程计算步骤是一样的,区别在于均值方差的来源。训练时来自于当前mini-batch统计而来;而推理时是通过整个之前的训练过程得到,因此是fix的。
BN在训练阶段的前向过程如下:

Mini-batch就是指在一个计算device上,一次计算的图片张数(假设数据是图片),在这个Mini-batch上统计出mean、variance,然后做normalize,最后为了让Feature Map可以缩放,又重新引入了较为简单的 γ \gamma γ和 β \beta β。在数量上,每一个输出的channel会各有1个mean,var, γ \gamma γ和 β \beta β。
BN的训练反向如果不想细看也可以不看,因为BN整个过程是可微的,因此在当前的framework下都可以自动完成反向传播。过程如下:
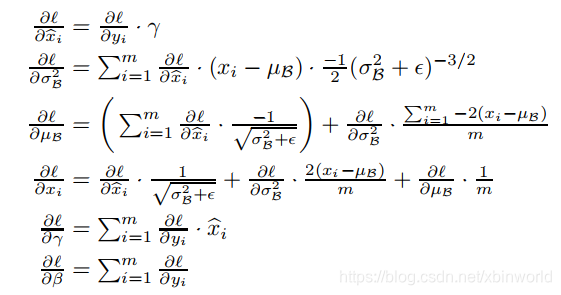
很基础的链式求导法则,通过前面的前向过程反过来求导,可以一步一步的推出上述结果。
BN所处的位置:一般是紧跟在Conv或者FC层之后,激活函数之前,即Conv - BN - Scale - Relu。当然,也有一些论文研究BN到底应该放在哪,目前看也并没有必然,毕竟BN只是起了一个归一化的作用,不同地方对不同网络有好有坏。BN有一个很大的作用就是:宣布了从12年Alexnet开始的Local Response Normalization层的结束,从BN之后基本没有再用LRN层了(这个层计算真的很变扭)。
Layer Norm,Instance Norm,Group Norm

借用He Kaiming大神的论文[2]中的图,简单总结了一下这几种类型的差异。
都要做归一化操作:
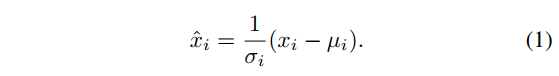
而均值方差计算公式都是:

唯一的区别就是计算均值方差的范围不同。
- Layer Norm:因为BN需要统计一个小batch,但是当batch太小比如=1,2这样的时候,BN有时候会有些问题,因此有人设计出了LN,即对整个样本自己统计一组mean和var,而无需关心其他样本。
- Instance Norn:会每个样本的每个channel统计一组mean和var
- Group Norm:取了一个折中,每个样本的部分channel统计一组mean和var
后面还有一个Scale层,就是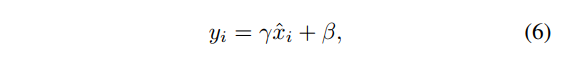
一律都是per-channel的 γ \gamma γ和 β \beta β,上述几个方法都是一致的。
Weight Normalization
这篇和前面的思路不同,是通过限制Weight的范围来让训练变得更快,方法非常简单:不直接训练W,而是训练v和g

v和w一样size,g是一个标量,让w可以有比较容易地缩放。这个过程本身就是可微的,在framework中比较容易实现。论文还提到了一句,为了让g伸缩更快,可以采用exponential parameterization,即 g = e s g = e^s g=es,然后优化的是s。但是论文说通过实验,发现似乎没有明显的差异。
参考资料
[1] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
[2] Group Normalization
[3] Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
[4]
[5]
这篇关于深度学习方法(十六):Batch Normalization及其变种——Layer Norm, Group Norm,Weight Norm等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




