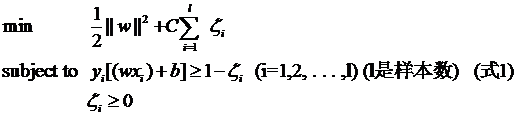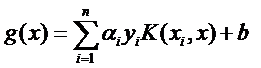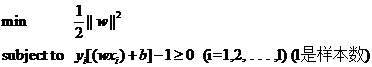本文主要是介绍svm的对偶,kkt,拉格朗日乘子法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://blog.csdn.net/bit_666/article/details/79865225
1.SVM基础模型
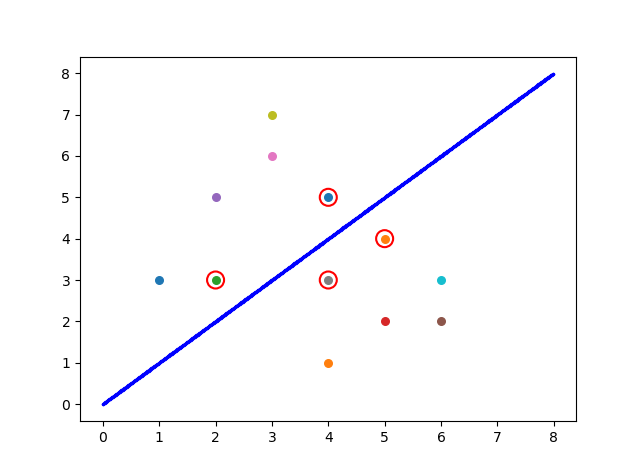
给定训练集D={(x1,y1),(x2,y2)...(xn,yn)},yi∈{-1,1},例如下面图中的点,蓝线左上方的6个点对应1类,右下方的6个点对应-1类,基于数据分类的思想,如果我们想把两类数据分开,显然蓝线不是唯一的选择,我们有无数条直线可以选择将两类数据点分开,这些划分数据的直线我们统称为划分超平面,但是这么多划分超平面,我们的目标是要寻找最优的划分超平面。
直观上看,我们应该找两类样本间最“正”的划分超平面,就像图中蓝线所示,因为该超平面对训练样本的局部扰动“抗干扰性”最好,也就是说,这个划分超平面所产生的分类效果是最好的,对未见的例子的泛化能力也最强。
在样本空间中,超平面可以通过线性方程来描述:
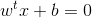
其中w=(w1,w2,w3...,wd)为法向量,决定了超平面的方向,b为位移项(截距项),决定了超平面与原点之间的距离,显然,划分超平面可被法向量w和位移b决定,下面将该平面记为(w,b),则样本中任意x到超平面(w,b)的距离为:
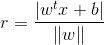
假设超平面能将样本正确分类,即对于(xi,yi)∈ D,若yi=+1,则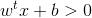
若yi=-1,则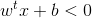
这里我们令:
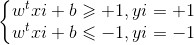
即距离超平面正向距离大于1判定为1类别,距离超平面负向距离大于1的判定为-1类别。如上图所示,标记红圈的四个点使等式成立,他们也被称为“支撑向量”(support vector),两个异类支持向量到超平面的距离之和:
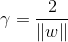
称为“间隔”.
支持向量机的目标就是找到具有“最大间隔”的划分超平面,也就是要找满足(式1.1)中的w和b,使得距离γ最大,即:
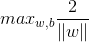
s.t.
为了最大化间隔,仅需最大化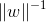
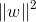
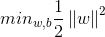
s.t. 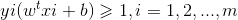
这就是SVM最基础的模型。
2.拉格朗日乘子法与对偶问题
我们希望求解式(式1.2)得到最大间隔划分超平面对应的模型:
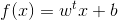
其中w,b是模型参数,这里我们使用拉格朗日乘子法得到其对偶问题,从而高效的求出结果,下面就看一下什么是拉格朗日乘子法和对偶问题。
1)lagrange乘子法
拉格朗日乘子法是一种寻找多元函数在一组约束下的极值的方法,通过引入拉格朗日乘子,可将有d个变量与k个约束条件的优化问题转换为具有d+k个变量的无约束优化问题。
考虑一个优化问题,假设x为d维,欲寻找x的某个取值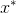
·对于约束曲面上的任意点x,该点的梯度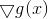
·对于最优点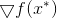
由此可知,在最优点
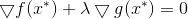
λ称为拉格朗日乘子,定义拉格朗日函数:
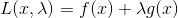
对(式2.2)函数求导即得到(式2.1),于是原约束问题可转化为对拉格朗日函数L(x,λ)的无约束问题。
2)KKT条件
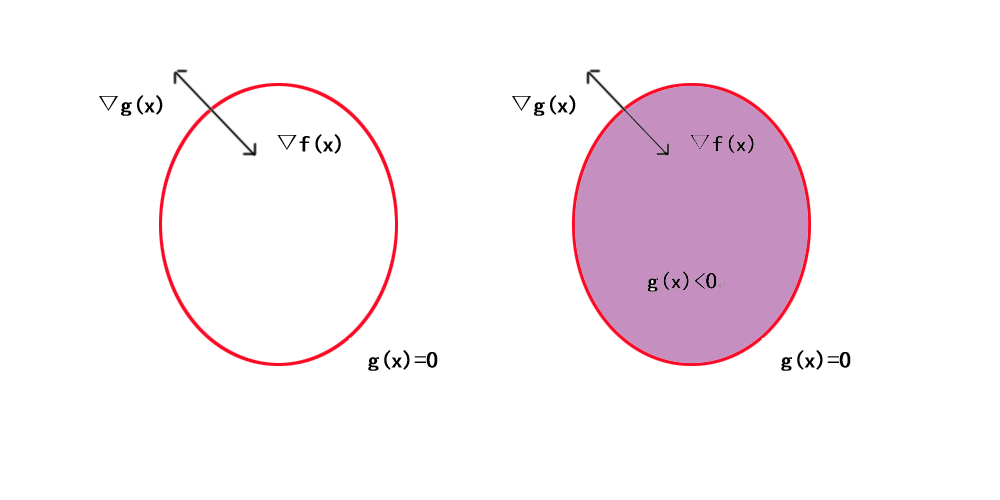
拉格朗日乘子法的几何意义即在等式g(x)=0或在不等式约束g(x)≤0下最小化目标函数f(x),红色曲线表示g(x)=0构成的曲面,阴影部分的紫色即为g(x)<0的部分.
情况1 g(x)<0 :
g(x)<0时,对f(x)求极值相当于闭区间求极值,最值点即为极值点,令λ=0,直接对f求梯度即可得到极值。
情况2 g(x) = 0 :
g(x) = 0时,说明极值点在边界取到,即g(x)<0内的点值都大于边界,梯度的定义是向函数值增加最快的方向,所以f的梯度与g的梯度相反,从而存在常数λ>0,使得:
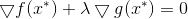
综合情况1和情况2,我们得到KKT条件:
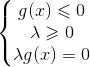
通俗意义理解KKT条件的话就是目标函数在约束条件下取得极值的充要条件,也就是目标函数在约束条件下取得极值时对应的x,λ必须满足KKT条件,反之亦然。
3)多约束问题推广
将上述做法推广到m个等式约束和n个不等式约束,且可行域非空的优化问题。
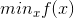
s.t.
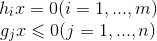
引入拉格朗日乘子λ=(λ1,λ2,...,λm).T , u=(u1,u2,...,un).T, 相应的拉格让日函数为:
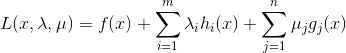
由不等式约束引入KKT条件(j=1,2,...,n):
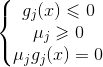
一个优化问题可以从两个角度考察,即主问题和对偶问题,对于优化问题而言,常通过将拉格朗日乘子L(x,λ,u)求导并令为0,来获得对偶函数的表达形式。下面就看一下支持向量机如何通过拉格朗日乘子法转化为对偶问题,从而求解最优超平面。
3.支持向量机的对偶问题解决
先看一下支持向量机的目标函数与约束函数:
s.t.
对每条约束添加拉格朗日乘子αi≥0,则该问题的拉格朗日函数可写为:
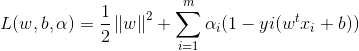
其中α=(α1,α2,...,αm),令L(w,b,α)对w和b求偏导为0可得(此处涉及到矩阵求导):
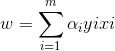
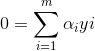
将上式带入拉格让日函数中w和b消去:
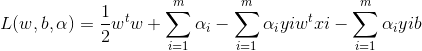
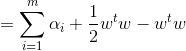
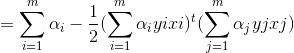
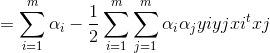
从而得到对偶问题:
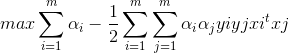
s.t .
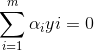
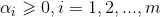
解出α后,通过
即可得到w,b的求解通过任一支持向量即可求出,因为在支持向量处,满足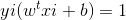
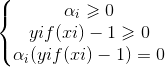
4.对偶问题与KKT条件推导
拉格朗日成乘数法主要解决约束优化问题,通过引入拉格朗日乘子,将n个变量,k个约束的问题转化为n+k个变量的无约束问题
基本形态:
z = f(x,y) 在满足 g(x,y)=0 的条件下,可转化为F(x,y,λ) = f(x,y) + g φ(x,y)
KKT:
KKT条件即在满足一定规则下,一个非线性规划问题能有最优解的必要和充分条。上面通过图像上的梯度直观了解了KKT条件,下面通过对偶问题的推导得到KKT的条件:
![]()
其中 ![]()
proof:
由已知条件可得
![]()
所以去掉一个小于等于0的项目可得(☆)
![]()
两边同时加min可得(☆☆)
![]()
接下来计算对偶问题,这里将L(x,u)展开可得
![]()
![]()
先计算后面一项
![]()
∴ 对min ug(x) 取max时最大只能取到0 此时 u=0 或 g(x)=0(☆☆☆)
![]()
∴ 对偶问题的后一项即为0 可以省略,又有:
![]()
这里因为f(x) 为关于x的函数,所以与u无关,所以可以省略掉max符号,可得:
![]()
结合(☆☆)处的公式可得:
![]()
即:

∴ 我们称max min L(x,u) 为 min max L(x,u)的对偶问题,这表明在一定条件下(KKT条件),原问题与对偶问题与min f(x)的解相同,且在最优解x*处,u=0 或者 g(x)=0,这里可以结合上文中图片解释,会有更好的理解。
将x*带入(☆)式:
![]()
又:
![]()
可得:
![]()
即:
![]()
∴ x*也是拉格朗日问题 L(x,u) 的极值点,这也说明引入拉格朗日乘子的可行性。

总结:
通俗来讲,对偶问题就是使求解更加高效且目标函数值不变,通过先消去w,b,得到关于α的函数,然后单独计算 α,通过得到的α反求w,b,最后获得超平面的参数,相比于先对α的不等式约束进行计算,对偶的方式使得计算更加便捷。另外KKT条件就是在约束下求得目标函数极值时αi满足的条件,只有满足了kkt条件,才算是满足了目标函数和约束函数,因此之后介绍的计算迭代算法也是基于KKT条件,通过不断修改不满足KKT条件的α,使其满足KKT条件,从而求出目标函数的最优值。下篇文章将主要推导一种计算w和b的高效算法-SMO算法,看看实际中如何通过对偶问题公式推出α,从而由α推出w和b.本文主要参考西瓜书,有问题欢迎大家交流~
这篇关于svm的对偶,kkt,拉格朗日乘子法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!