本文主要是介绍Unifying Voxel-based Representation with Transformer for 3D Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Paper name
Unifying Voxel-based Representation with Transformer for 3D Object Detection
Paper Reading Note
URL: https://arxiv.org/pdf/2206.00630.pdf
TL;DR
- NIPS 2022 文章,提出了在 voxel 特征空间统一多模态输入的方式(UVTR),便于跨模态融合及知识蒸馏
Introduction
背景
- 基于多模态传感器进行 3d 检测很重要,比如 lidar 获取精准定位信息,camera 获取丰富的上下文信息
- 需要在一个统一的特征空间进行多模态的整合,从而便于知识蒸馏和跨模态特征融合。其中一个难点是 camera 缺乏准确的深度标注,从而图片难以像点云这样被天然转换到 voxel space 中
-
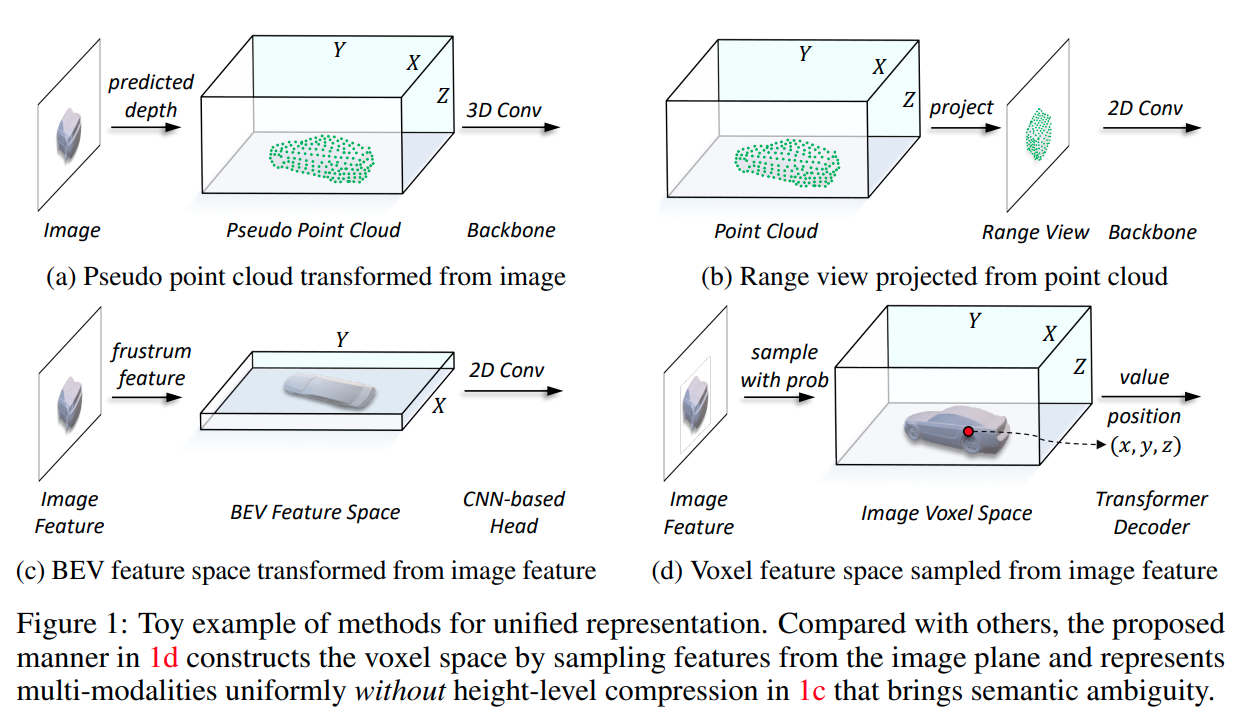
当前的跨模态输入表达方式的特点
- a:基于图像预测的深度将图像转换成伪点云
- 预测深度不准确导致的误差
- b:将 lidar 点云转换到 range-view 下
- 几何结构压缩导致空间结构信息被破坏
- a:基于图像预测的深度将图像转换成伪点云
-
当前的跨模态特征表达方式的特点
- c:图像特征转换为 frustum,然后压缩到 BEV 域下
- BEV 下每个位置的高度压缩聚集了不同对象的特征,从而引入了语义模糊性
- c:图像特征转换为 frustum,然后压缩到 BEV 域下
-
本文认为比较合适的特征表达空间
- d: 根据图像深度的得分和几何约束在图像特征空间采样得到 voxel 特征;lidar 点云因为有准确的位置信息,可以基于特征提取 backbone 自然地转换到 voxel 特征中
- 在 voxel 特征基础上使用 transformer decoder 得到 3d 检测结果,环境语义模糊性
- d: 根据图像深度的得分和几何约束在图像特征空间采样得到 voxel 特征;lidar 点云因为有准确的位置信息,可以基于特征提取 backbone 自然地转换到 voxel 特征中
本文方案
- 提出了在 voxel 特征空间统一多模态输入的方式(UVTR),便于跨模态融合及知识蒸馏,数据增广也可以在相同的空间中做
- nuscenes test 集的精度:69.7%(lidar), 55.1%(camera), and 71.1%(fusion)
- AMOTA tracking 精度:67.0%(lidar), 51.9%(camera), and 70.1%(fusion)
Dataset/Algorithm/Model/Experiment Detail
实现方式
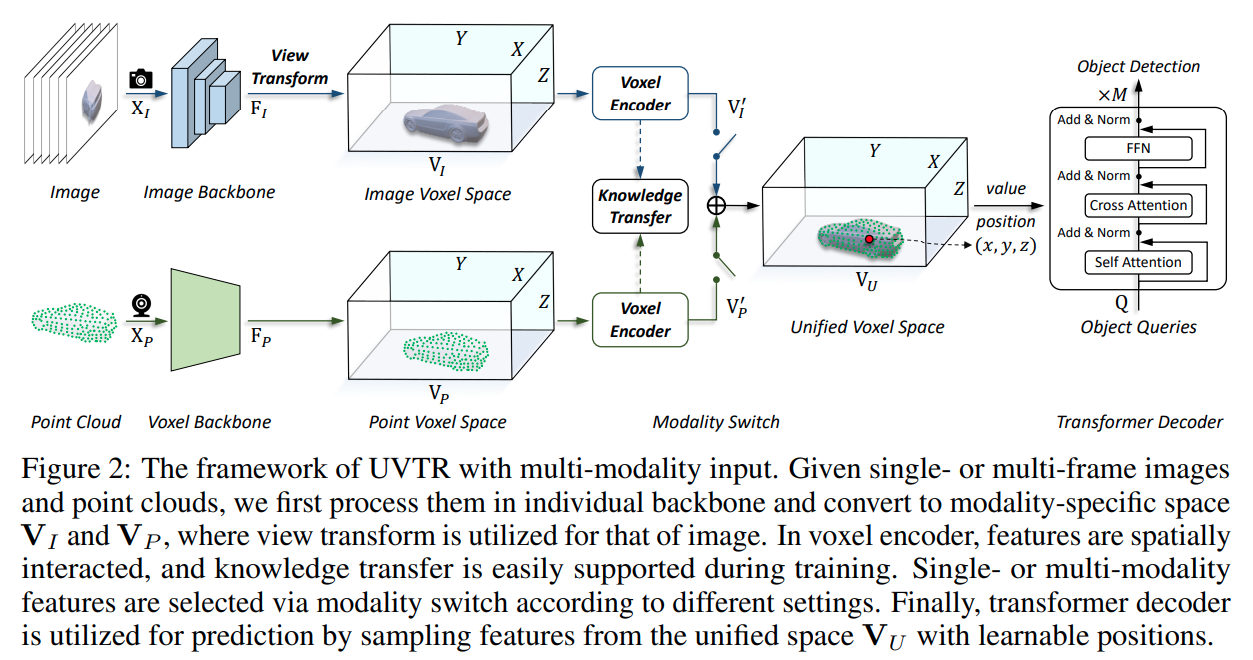
- 整体流程比较直观
- 图像经过2d backbone 提取特征,经过 view tranform 过程转换到 voxel 空间,然后经过 voxel encoder 得到 voxel 特征
- 点云经过 voxel backbone 转换到 voxel 空间,通过 voxel encoder 得到 voxel 特征
- 其中两个模态经过 voxel encoder 后的特征可以进行知识蒸馏,也可以直接加权融合
- 基于 transformer decoder 在 voxel 特征提取得到 3d 检测结果
Image Voxel 空间
-
基于 2d backbone 提取多视角或多帧图像的特征, 基于 FPN 用于生成 FI (H×W×C尺寸) 图像特征,不同 fpn stage 的 hw 不同
-
受到 lss 启发设计了一个 view transform 方案,基于 view transform 将图像特征转换到 voxel 空间上
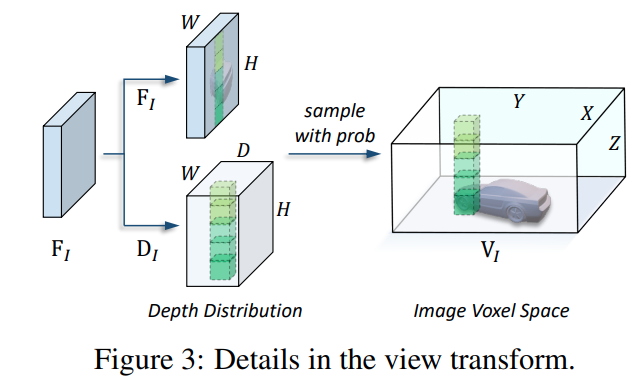
首先基于单层 conv 将 FI 处理为 D 维度,然后基于 softmax 算子得到深度分布
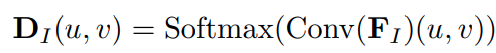
对于体素中的点 (x, y, z),基于相机外参内参可以对应到图像 plane 中的某个 (u, v, d) 点,即可以通过图像特征转换到 voxel 空间上
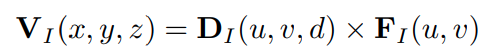
其中 D I ( u , v , d ) D_{I}(u, v, d) DI(u,v,d) 代表图像特征 F I ( u , v ) F_{I}(u, v) FI(u,v) 在 voxel (x, y, z) 的occupancy probability -
多帧处理方式:
- 所有帧都基于外参对齐到初始帧上,并将先对时间的 offsets 加到 channel 维度上,从而保存时域线索
- 将所有帧的 voxel concat 起来,经过卷积得到最终的体素输出
Point Voxel Space
- 将输入的点云分成规则的 voxel,然后利用 voxel backbone (sparse convolution) 对 voxel 进行处理
- 不同 strides 的并行 heads 用于提取多尺度的特征,主要是在每个 h 维度上进行不同 strides 的 2d 卷积,然后上采样回相同的尺度
- 多帧也是将相对时间 offset 附到点云上
Voxel Encoder
- 考虑到 image 生成的 voxel 上不同视角图片投影得到的相邻 voxel 是没有交互的,所以用 3层卷积来对 voxel 进一步处理
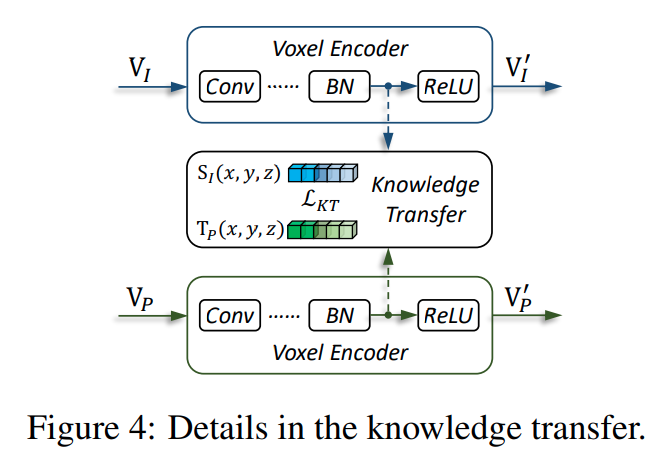
其中知识蒸馏是作用于最后的 bn 层输出
知识蒸馏
- 体素层面直接用 partial L2 距离 loss
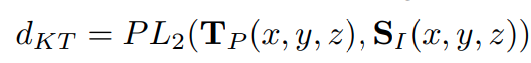
- transformer 的 object queries 直接取平均进行蒸馏
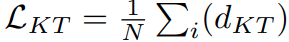
跨模态融合
- 对跨模态的体素直接相加即可,然后基于一层卷积融合
实验结果
与 SOTA 模型对比
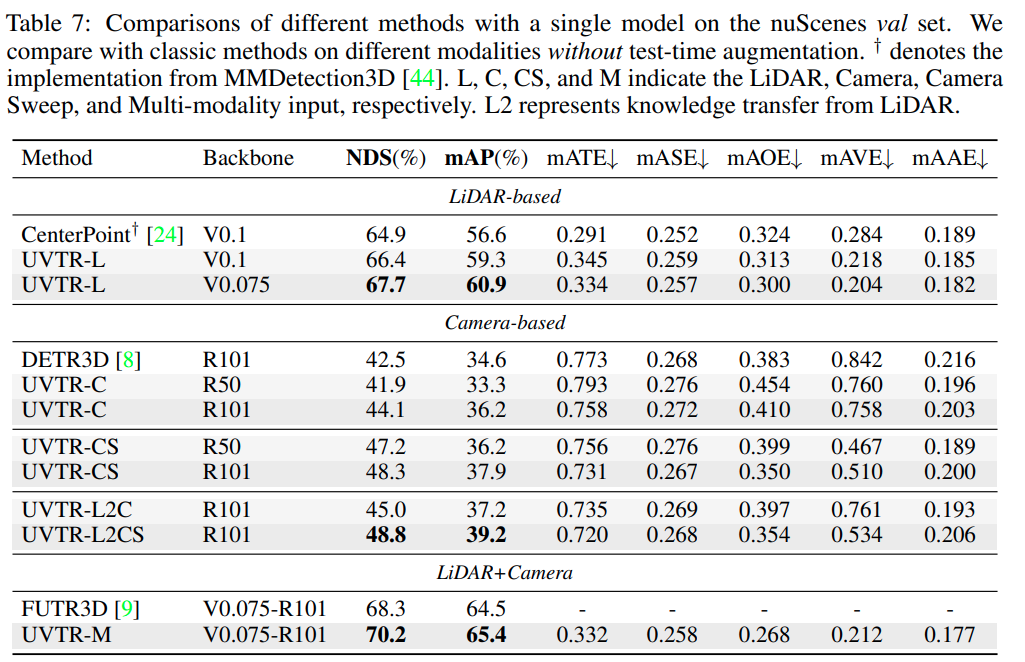
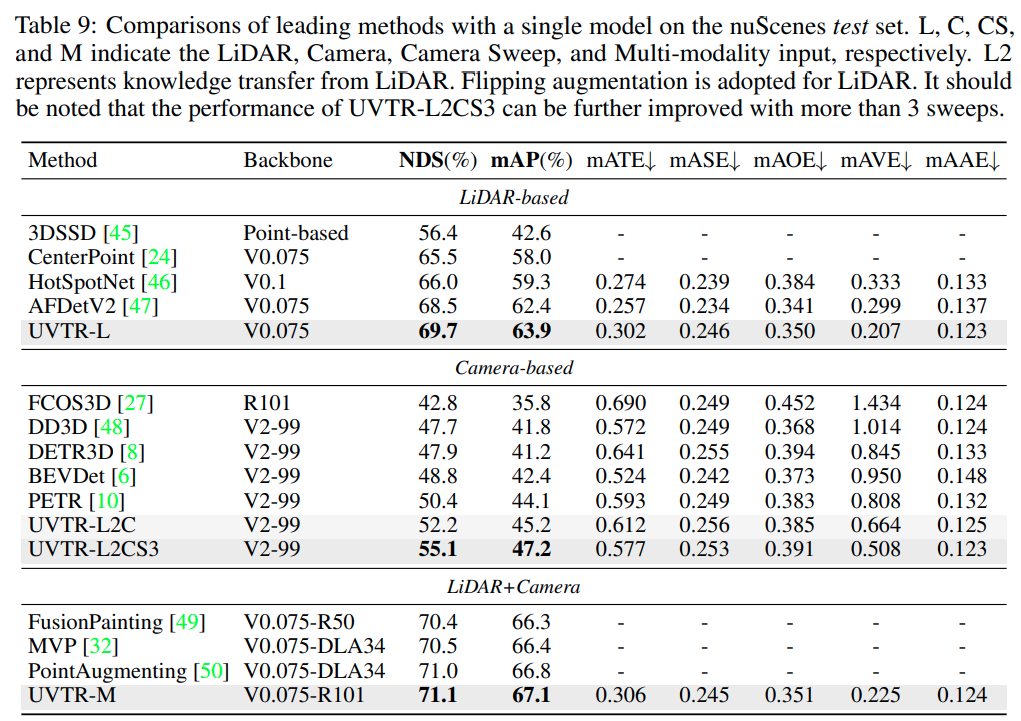
分析实验
-
相对远距离(20-30m) fusion 相对于 lidar 涨点幅度最大;lidar 和 camera 低照下精度都低;雨天基于 camera 融合涨点幅度较大
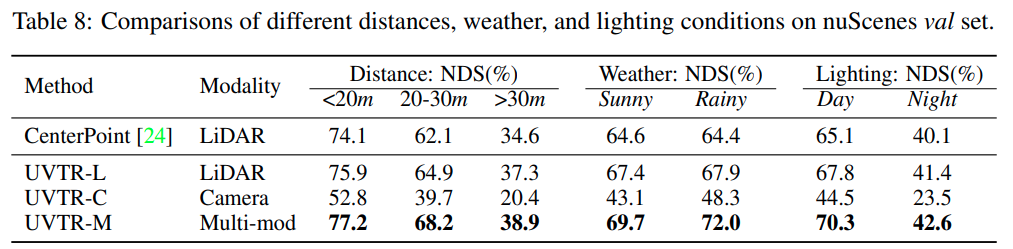
-
fusion 精度优势
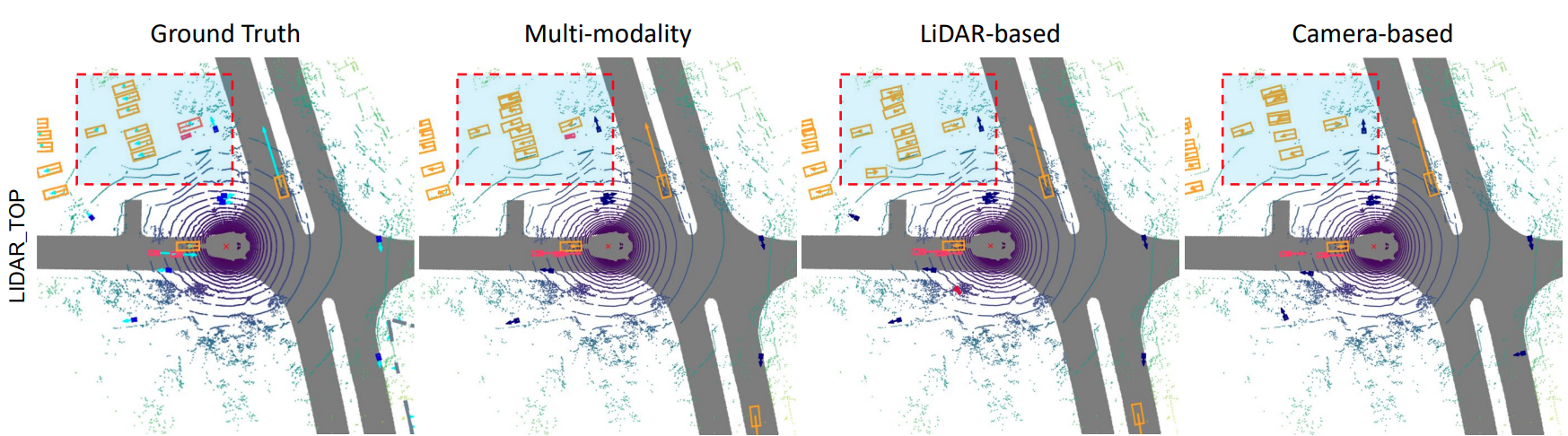


Thoughts
- voxel 作为跨模态统一的特征空间看起来确实有相应优势的,不过保留高度维度后如果能利用上轻量级别的 head 还有待研究
- 显存占用还是挺大的,大部分模型都得用 v100 训练,小部分模型需要用 a100
这篇关于Unifying Voxel-based Representation with Transformer for 3D Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






